Kubernetes运维生态-cAdvisor分析
Kubernetes的生态中,cAdvisor是作为容器监控数据采集的Agent,其部署在每个节点上,内部代码结构大致如下:代码结构很良好,collector和storage部分基本可做到增量扩展开发。
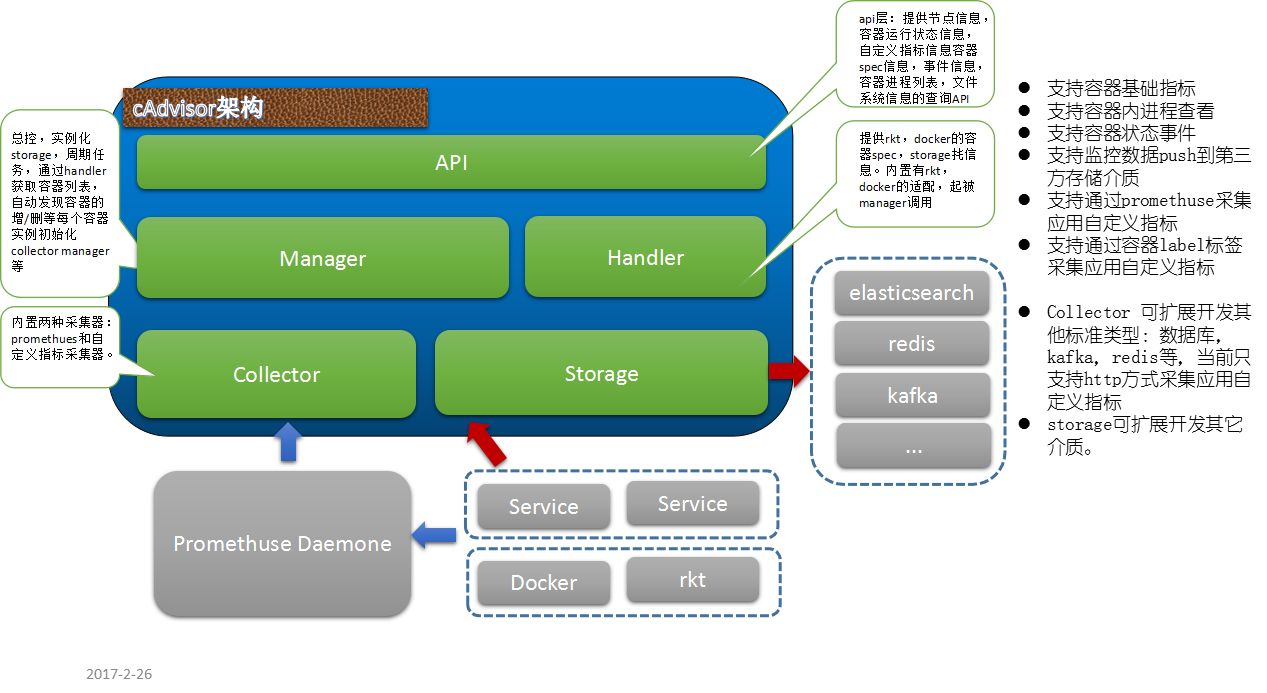
关于cAdvisor支持自定义指标方式能力,其自身是通过容器部署的时候设置lable标签项:io.cadvisor.metric.开头的lable,而value则为自定义指标的配置文件,形如下:
{
"endpoint" : {
"protocol": "https",
"port": 8000,
"path": "/nginx_status"
},
"metrics_config" : [
{ "name" : "activeConnections",
"metric_type" : "gauge",
"units" : "number of active connections",
"data_type" : "int",
"polling_frequency" : 10,
"regex" : "Active connections: ([0-9]+)"
},
{ "name" : "reading",
"metric_type" : "gauge",
"units" : "number of reading connections",
"data_type" : "int",
"polling_frequency" : 10,
"regex" : "Reading: ([0-9]+) .*"
},
{ "name" : "writing",
"metric_type" : "gauge",
"data_type" : "int",
"units" : "number of writing connections",
"polling_frequency" : 10,
"regex" : ".*Writing: ([0-9]+).*"
},
{ "name" : "waiting",
"metric_type" : "gauge",
"units" : "number of waiting connections",
"data_type" : "int",
"polling_frequency" : 10,
"regex" : ".*Waiting: ([0-9]+)"
}
]
}
当前cAdvisor只支持http接口方式,也就是被监控容器应用必须提供http接口,所以能力较弱,如果我们在collector这一层做扩展增强,提供数据库,mq等等标准应用的监控模式是很有价值的。在此之前的另一种方案就是如上图所示搭配promethuese(其内置有非常丰富的标准应用的插件涵盖了APM所需的采集大部分插件),但是这往往会导致系统更复杂(如果应用层并非想使用promethuse)
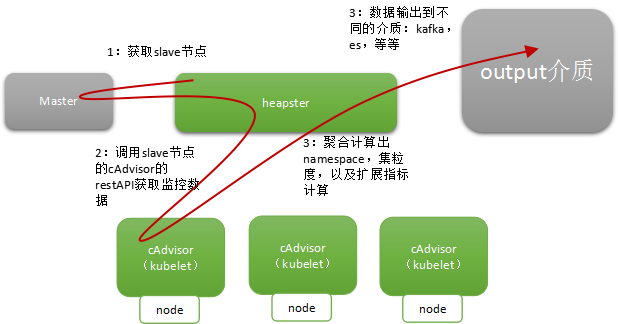
在Kubernetes监控生态中,一般是如下的搭配使用:
Kubernetes运维生态-cAdvisor分析的更多相关文章
- Kubernetes运维生态-Heapster分析
Heapster在Kubernetes的运维生态中如下:集群的容器的监控数据收敛汇聚层 heapster1.0版本后内部分为event和metric两个进程,可制作为两个docker镜像部署为两个独立 ...
- 从运维角度来分析mysql数据库优化的一些关键点【转】
概述 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善. 1.数据库表设计 项目立项后,开发部根据产品部需求开发项目,开发工程师工作其中一部分 ...
- 从运维的角度分析使用阿里云数据库RDS的必要性--你不应该在阿里云上使用自建的MySQL/SQL Server/Oracle/PostgreSQL数据库
开宗明义,你不应该在阿里云上使用自建的MySQL or SQL Server数据库,对了,还有Oracle or PostgreSQL数据库. 云数据库 RDS(Relational Database ...
- 故障排除--kubernetes 运维操作步骤 -- kubedns -- busybox -- nslookup 问题
1.node的扩容 在k8s中,对一个新的node的加入非常简单,只需要在node节点上安装docker.kubelet和kube-proxy服务,然后将kubelet和kube-proxy的启动参数 ...
- 运维DBA要不要学python
运维DBA要不要学python 我个人认为是:要 现在python在运维数据库的工作中主要用在 1.编写一些运维脚本 2.编写运维管理平台 3.研究互联网大厂的运维脚本/工具并应有 特别是运维开源数据 ...
- 双态运维分享之:业务场景驱动的服务型CMDB
最近这几年,国内外CMDB失败的案例比比皆是,成功的寥寥可数,有人质疑CMDB is dead?但各种业务场景表明,当下数据中心运维,CMDB依然是不可或缺的一部分,它承载着运维的基础,掌握运维的命脉 ...
- Docker集群管理工具 - Kubernetes 部署记录 (运维小结)
一. Kubernetes 介绍 Kubernetes是一个全新的基于容器技术的分布式架构领先方案, 它是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernete ...
- Linux运维之道(大量经典案例、问题分析,运维案头书,红帽推荐)
Linux运维之道(大量经典案例.问题分析,运维案头书,红帽推荐) 丁明一 编 ISBN 978-7-121-21877-4 2014年1月出版 定价:69.00元 448页 16开 编辑推荐 1 ...
- 从一到万的运维之路,说一说VM/Docker/Kubernetes/ServiceMesh
摘要:本文从单机真机运营的历史讲起,逐步介绍虚拟化.容器化.Docker.Kubernetes.ServiceMesh的发展历程.并重点介绍了容器化阶段之后,各项重点技术的安装.使用.运维知识.可以说 ...
随机推荐
- 背景图片等比缩放的写法background-size简写法
1.背景图片或图标也可像img一样给其宽高就能指定其缩放大小了. 比如一个实际宽高36*28的图标,要缩小一半引用进来的写法就是: background:rgba(0, 0, 0, 0) url(&q ...
- java_web学习(8)会话与状态管
HTTP简介 WEB浏览器与WEB服务器之间的一问一答的交互过程必须遵循一定的规则,这个规则就是HTTP协议.HTTP是hypertext transfer protocol(超文本传输协 ...
- 简述Android系统内存不足时候,内存回收机制
当Android系统的内存不足时,会根据以下的内存回收规则来回收内存: 1.先回收与其他Activity或Service/Intent Receiver无关的进程(即优先回收独立的Activity) ...
- Struts框架中struts-config.xml文件配置小结
弄清楚struts-config.xml中各项元素的作用,对于我们构建web项目有莫大的好处.<struts-config>是struts的根元素,它主要有8个子元素,DTD定义 如下: ...
- oracle取字符串长度的函数length()和hengthb()
http://blog.itpub.net/161195/viewspace-613263/ lengthb(string)计算string所占的字节长度 :返回字符串的长度,单位是字节 length ...
- Microsoft IoT Starter Kit 开发初体验-反馈控制与数据存储
在上一篇文章<Microsoft IoT Starter Kit 开发初体验>中,讲述了微软中国发布的Microsoft IoT Starter Kit所包含的硬件介绍.开发环境搭建.硬件 ...
- 搭建spring工程配置数据源连接池
Spring作为一个优秀的开源框架,越来越为大家所熟知,前段时间用搭了个spring工程来管理数据库连接池,没有借助Eclipse纯手工搭建,网上此类文章不多,这里给大家分享一下,也作为一个手记. 工 ...
- page cache 与free
我们经常用free查看服务器的内存使用情况,而free中的输出却有些让人困惑,如下: 先看看各个数字的意义以及如何计算得到: free命令输出的第二行(Mem):这行分别显示了物理内存的总量(tota ...
- js在新页面中返回到上一页浏览的历史位置
在微信浏览器中浏览页面时,在当前页面中当我们将页面往下滚动到某一个位置时,可能我们就会点击某个链接而页面跳转到了另外一个页面,而当我们又返回到上一个页面时我们会发现那个页面还停留在我们之前浏览的位置, ...
- ArcGIS Pro 简明教程(3)数据编辑
ArcGIS Pro 简明教程(3)数据编辑 by 李远祥 数据编辑是GIS中最常用的功能之一,ArcGIS Pro在GIS数据编辑上使用习惯有一定的改变,因此,本章可以重点看看一些编辑工具的使用和使 ...