Kubernetes运维生态-cAdvisor分析
Kubernetes的生态中,cAdvisor是作为容器监控数据采集的Agent,其部署在每个节点上,内部代码结构大致如下:代码结构很良好,collector和storage部分基本可做到增量扩展开发。
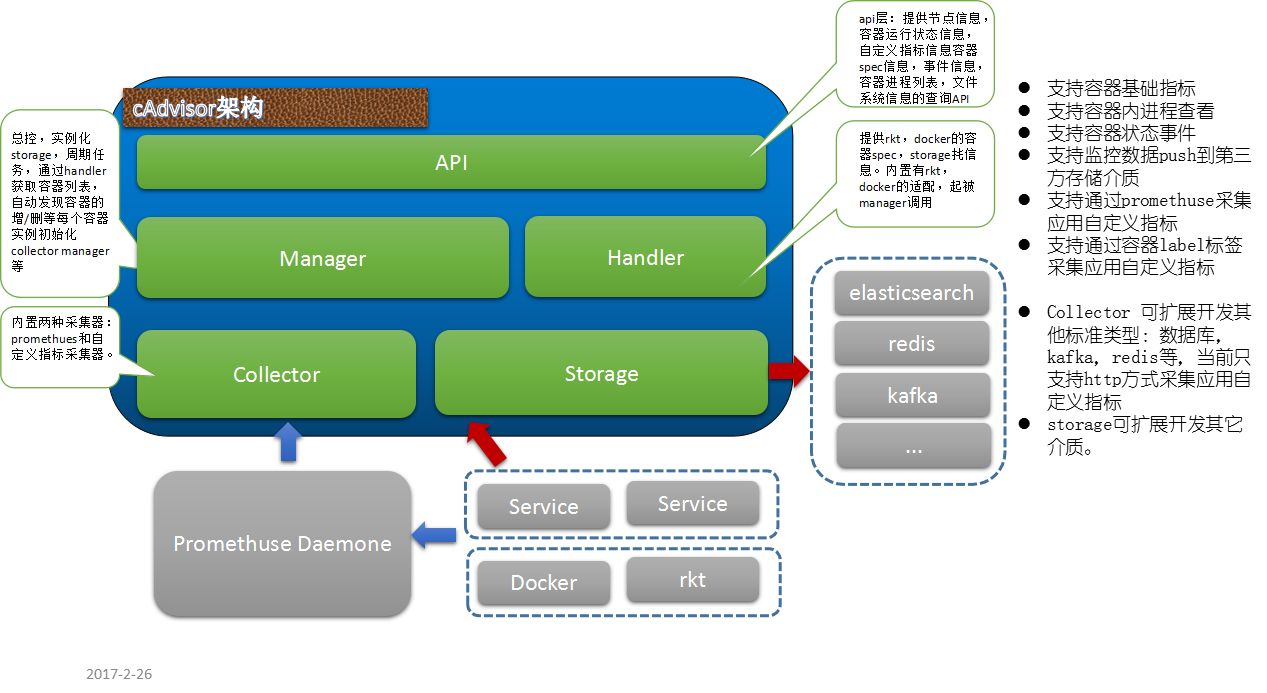
关于cAdvisor支持自定义指标方式能力,其自身是通过容器部署的时候设置lable标签项:io.cadvisor.metric.开头的lable,而value则为自定义指标的配置文件,形如下:
{
"endpoint" : {
"protocol": "https",
"port": 8000,
"path": "/nginx_status"
},
"metrics_config" : [
{ "name" : "activeConnections",
"metric_type" : "gauge",
"units" : "number of active connections",
"data_type" : "int",
"polling_frequency" : 10,
"regex" : "Active connections: ([0-9]+)"
},
{ "name" : "reading",
"metric_type" : "gauge",
"units" : "number of reading connections",
"data_type" : "int",
"polling_frequency" : 10,
"regex" : "Reading: ([0-9]+) .*"
},
{ "name" : "writing",
"metric_type" : "gauge",
"data_type" : "int",
"units" : "number of writing connections",
"polling_frequency" : 10,
"regex" : ".*Writing: ([0-9]+).*"
},
{ "name" : "waiting",
"metric_type" : "gauge",
"units" : "number of waiting connections",
"data_type" : "int",
"polling_frequency" : 10,
"regex" : ".*Waiting: ([0-9]+)"
}
]
}
当前cAdvisor只支持http接口方式,也就是被监控容器应用必须提供http接口,所以能力较弱,如果我们在collector这一层做扩展增强,提供数据库,mq等等标准应用的监控模式是很有价值的。在此之前的另一种方案就是如上图所示搭配promethuese(其内置有非常丰富的标准应用的插件涵盖了APM所需的采集大部分插件),但是这往往会导致系统更复杂(如果应用层并非想使用promethuse)
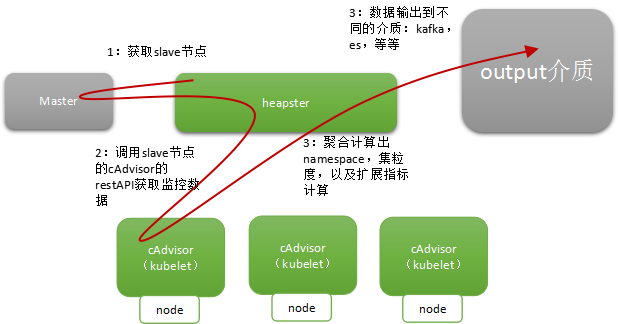
在Kubernetes监控生态中,一般是如下的搭配使用:
Kubernetes运维生态-cAdvisor分析的更多相关文章
- Kubernetes运维生态-Heapster分析
Heapster在Kubernetes的运维生态中如下:集群的容器的监控数据收敛汇聚层 heapster1.0版本后内部分为event和metric两个进程,可制作为两个docker镜像部署为两个独立 ...
- 从运维角度来分析mysql数据库优化的一些关键点【转】
概述 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善. 1.数据库表设计 项目立项后,开发部根据产品部需求开发项目,开发工程师工作其中一部分 ...
- 从运维的角度分析使用阿里云数据库RDS的必要性--你不应该在阿里云上使用自建的MySQL/SQL Server/Oracle/PostgreSQL数据库
开宗明义,你不应该在阿里云上使用自建的MySQL or SQL Server数据库,对了,还有Oracle or PostgreSQL数据库. 云数据库 RDS(Relational Database ...
- 故障排除--kubernetes 运维操作步骤 -- kubedns -- busybox -- nslookup 问题
1.node的扩容 在k8s中,对一个新的node的加入非常简单,只需要在node节点上安装docker.kubelet和kube-proxy服务,然后将kubelet和kube-proxy的启动参数 ...
- 运维DBA要不要学python
运维DBA要不要学python 我个人认为是:要 现在python在运维数据库的工作中主要用在 1.编写一些运维脚本 2.编写运维管理平台 3.研究互联网大厂的运维脚本/工具并应有 特别是运维开源数据 ...
- 双态运维分享之:业务场景驱动的服务型CMDB
最近这几年,国内外CMDB失败的案例比比皆是,成功的寥寥可数,有人质疑CMDB is dead?但各种业务场景表明,当下数据中心运维,CMDB依然是不可或缺的一部分,它承载着运维的基础,掌握运维的命脉 ...
- Docker集群管理工具 - Kubernetes 部署记录 (运维小结)
一. Kubernetes 介绍 Kubernetes是一个全新的基于容器技术的分布式架构领先方案, 它是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernete ...
- Linux运维之道(大量经典案例、问题分析,运维案头书,红帽推荐)
Linux运维之道(大量经典案例.问题分析,运维案头书,红帽推荐) 丁明一 编 ISBN 978-7-121-21877-4 2014年1月出版 定价:69.00元 448页 16开 编辑推荐 1 ...
- 从一到万的运维之路,说一说VM/Docker/Kubernetes/ServiceMesh
摘要:本文从单机真机运营的历史讲起,逐步介绍虚拟化.容器化.Docker.Kubernetes.ServiceMesh的发展历程.并重点介绍了容器化阶段之后,各项重点技术的安装.使用.运维知识.可以说 ...
随机推荐
- fastreport.net cdoe 自己的代码
//初始 Report report1 = new Report(); report1.Clear(); string Re ...
- 字符集 ISO-8859-1(3)
详细见 http://www.w3school.com.cn/tags/html_ref_urlencode.html
- python 循环使用 while 或 for 语句实现用户名密码输错三次退出
如有错误欢迎大家指出,新手初来乍到.程序没那么复杂,是最简单的. 一.需求 编写登录文件 .py1. 输入用户名密码2. 正确,输出欢迎登录3. 当输入用户名和密码小于 3 次,输入用户名或者密码错误 ...
- [ Android 五种数据存储方式之三 ] —— SQLite存储数据
SQLite是轻量级嵌入式数据库引擎,它支持 SQL 语言,并且只利用很少的内存就有很好的性能.此外它还是开源的,任何人都可以使用它.许多开源项目((Mozilla, PHP, Python)都使用了 ...
- C# Unity游戏开发——Excel中的数据是如何到游戏中的 (二)
本帖是延续的:C# Unity游戏开发——Excel中的数据是如何到游戏中的 (一) 上个帖子主要是讲了如何读取Excel,本帖主要是讲述读取的Excel数据是如何序列化成二进制的,考虑到现在在手游中 ...
- TortoiseSVN使用简介
TortoiseSVN使用简介 2009-04-24 来源: dev.idv.tw 1.安装及下载client 端 2.什么是SVN(Subversion)? 3.为甚么要用SVN? 4.怎么样在Wi ...
- xhtmlrenderer渲染pdf,中文换行
在实际开发中,发现在table中显示中文,渲染出来的pdf,中文内容不自动换行.经过搜索发现了一种解决方案,如下: 重写Breaker,修改right计算方式 /* * Breaker.java * ...
- aJax请求结果中包含form的问题
jsp页面a.jsp如下: <form action='login' id='formId' method='post'> <input name='user'> </f ...
- 汇编实现HelloWorl!
hello word~ ASSUME CS:CODE,DS:DATA DATA SEGMENT DB "HELLO WORLD" ;存储要显示的数据 DATA ENDS CODE ...
- Windows下Python读取GRIB数据
之前写了一篇<基于Python的GRIB数据可视化>的文章,好多博友在评论里问我Windows系统下如何读取GRIB数据,在这里我做一下说明. 一.在Windows下Python为什么无法 ...