Boosting算法简介
一、Boosting算法的发展历史
Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boostrapping方法和bagging方法。我们先简要介绍一下bootstrapping方法和bagging方法。
1)bootstrapping方法的主要过程
主要步骤:
i)重复地从一个样本集合D中采样n个样本
ii)针对每次采样的子样本集,进行统计学习,获得假设Hi
iii)将若干个假设进行组合,形成最终的假设Hfinal
iv)将最终的假设用于具体的分类任务
2)bagging方法的主要过程
主要思路:
i)训练分类器
从整体样本集合中,抽样n* < N个样本 针对抽样的集合训练分类器Ci
ii)分类器进行投票,最终的结果是分类器投票的优胜结果
但是,上述这两种方法,都只是将分类器进行简单的组合,实际上,并没有发挥出分类器组合的威力来。直到1989年,Yoav Freund与 Robert Schapire提出了一种可行的将弱分类器组合为强分类器的方法。并由此而获得了2003年的哥德尔奖(Godel price)。
Schapire还提出了一种早期的boosting算法,其主要过程如下:
i)从样本整体集合D中,不放回的随机抽样n1 < n 个样本,得到集合 D1
训练弱分类器C1
ii)从样本整体集合D中,抽取 n2 < n 个样本,其中合并进一半被 C1 分类错误的样本。得到样本集合 D2
训练弱分类器C2
iii)抽取D样本集合中,C1 和 C2 分类不一致样本,组成D3
训练弱分类器C3
iv)用三个分类器做投票,得到最后分类结果
到了1995年,Freund and schapire提出了现在的adaboost算法,其主要框架可以描述为:
i)循环迭代多次
更新样本分布
寻找当前分布下的最优弱分类器
计算弱分类器误差率
ii)聚合多次训练的弱分类器
在下图中可以看到完整的adaboost算法:

现在,boost算法有了很大的发展,出现了很多的其他boost算法,例如:logitboost算法,gentleboost算法等等。在这次报告中,我们将着重介绍adaboost算法的过程和特性。
二、Adaboost算法及分析
从图1.1中,我们可以看到adaboost的一个详细的算法过程。Adaboost是一种比较有特点的算法,可以总结如下:
1)每次迭代改变的是样本的分布,而不是重复采样(re weight)
2)样本分布的改变取决于样本是否被正确分类
总是分类正确的样本权值低
总是分类错误的样本权值高(通常是边界附近的样本)
3)最终的结果是弱分类器的加权组合
权值表示该弱分类器的性能
简单来说,Adaboost有很多优点:
1)adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单
4)简单,不用做特征筛选
5)不用担心overfitting!
总之:adaboost是简单,有效。
下面我们举一个简单的例子来看看adaboost的实现过程:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:
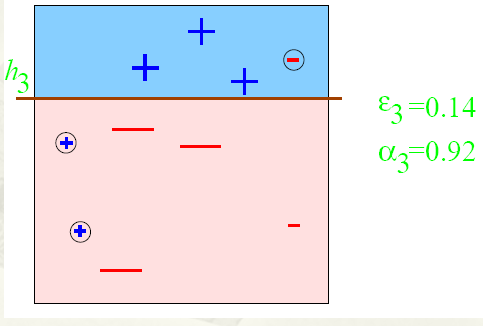
得到一个子分类器h3
整合所有子分类器:
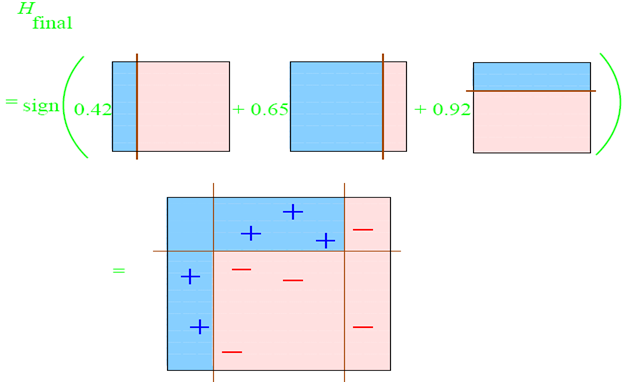
因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
Adaboost算法的某些特性是非常好的,在我们的报告中,主要介绍adaboost的两个特性。一是训练的错误率上界,随着迭代次数的增加,会逐渐下降;二是adaboost算法即使训练次数很多,也不会出现过拟合的问题。
下面主要通过证明过程和图表来描述这两个特性:
1)错误率上界下降的特性
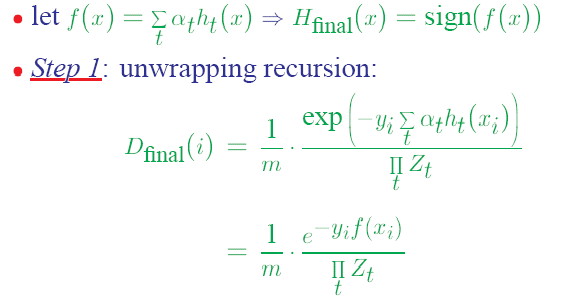


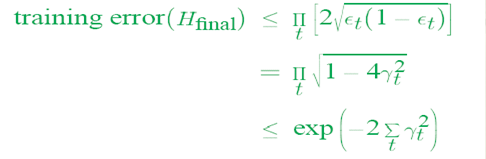
从而可以看出,随着迭代次数的增加,实际上错误率上界在下降。
2)不会出现过拟合现象
通常,过拟合现象指的是下图描述的这种现象,即随着模型训练误差的下降,实际上,模型的泛化误差(测试误差)在上升。横轴表示迭代的次数,纵轴表示训练误差的值。
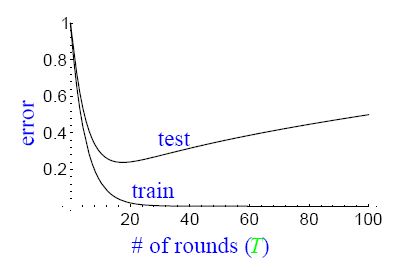
而实际上,并没有观察到adaboost算法出现这样的情况,即当训练误差小到一定程度以后,继续训练,返回误差仍然不会增加。
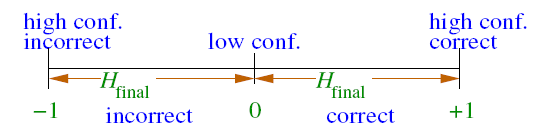
对这种现象的解释,要借助margin的概念,其中margin表示如下:
通过引入margin的概念,我们可以观察到下图所出现的现象:
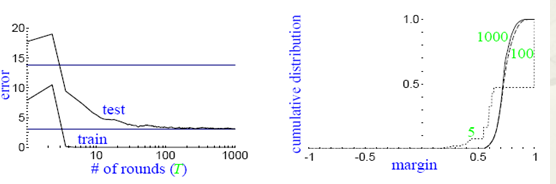
从图上左边的子图可以看到,随着训练次数的增加,test的误差率并没有升高,同时对应着右边的子图可以看到,随着训练次数的增加,margin一直在增加。这就是说,在训练误差下降到一定程度以后,更多的训练,会增加分类器的分类margin,这个过程也能够防止测试误差的上升。
三、多分类adaboost
在日常任务中,我们通常需要去解决多分类的问题。而前面的介绍中,adaboost算法只能适用于二分类的情况。因此,在这一小节中,我们着重介绍如何将adaboost算法调整到适合处理多分类任务的方法。
目前有三种比较常用的将二分类adaboost方法。
1、adaboost M1方法
主要思路: adaboost组合的若干个弱分类器本身就是多分类的分类器。
在训练的时候,样本权重空间的计算方法,仍然为:

在解码的时候,选择一个最有可能的分类
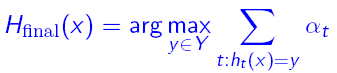
2、adaboost MH方法
主要思路: 组合的弱分类器仍然是二分类的分类器,将分类label和分类样例组合,生成N个样本,在这个新的样本空间上训练分类器。
可以用下图来表示其原理:
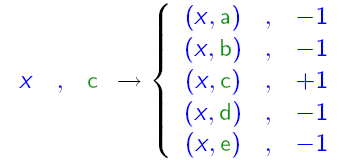
3、对多分类输出进行二进制编码
主要思路:对N个label进行二进制编码,例如用m位二进制数表示一个label。然后训练m个二分类分类器,在解码时生成m位的二进制数。从而对应到一个label上。
四、总结
最后,我们可以总结下adaboost算法的一些实际可以使用的场景:
1)用于二分类或多分类的应用场景
2)用于做分类任务的baseline
无脑化,简单,不会overfitting,不用调分类器
3)用于特征选择(feature selection)
4)Boosting框架用于对badcase的修正
只需要增加新的分类器,不需要变动原有分类器
由于adaboost算法是一种实现简单,应用也很简单的算法。Adaboost算法通过组合弱分类器而得到强分类器,同时具有分类错误率上界随着训练增加而稳定下降,不会过拟合等的性质,应该说是一种很适合于在各种分类场景下应用的算法。
Boosting算法简介的更多相关文章
- Gradient Boosting算法简介
最近项目中涉及基于Gradient Boosting Regression 算法拟合时间序列曲线的内容,利用python机器学习包 scikit-learn 中的GradientBoostingReg ...
- webrtc 的回声抵消(aec、aecm)算法简介(转)
webrtc 的回声抵消(aec.aecm)算法简介 webrtc 的回声抵消(aec.aecm)算法主要包括以下几个重要模块:1.回声时延估计 2.NLMS(归一化最小均方自适应算法) ...
- AES算法简介
AES算法简介 一. AES的结构 1.总体结构 明文分组的长度为128位即16字节,密钥长度可以为16,24或者32字节(128,192,256位).根据密钥的长度,算法被称为AES-128,AES ...
- 排列熵算法简介及c#实现
一. 排列熵算法简介: 排列熵算法(Permutation Entroy)为度量时间序列复杂性的一种方法,算法描述如下: 设一维时间序列: 采用相空间重构延迟坐标法对X中任一元素x(i)进行相空间 ...
- <算法图解>读书笔记:第1章 算法简介
阅读书籍:[美]Aditya Bhargava◎著 袁国忠◎译.人民邮电出版社.<算法图解> 第1章 算法简介 1.2 二分查找 一般而言,对于包含n个元素的列表,用二分查找最多需要\(l ...
- LARS 最小角回归算法简介
最近开始看Elements of Statistical Learning, 今天的内容是线性模型(第三章..这本书东西非常多,不知道何年何月才能读完了),主要是在看变量选择.感觉变量选择这一块领域非 ...
- AI - 机器学习常见算法简介(Common Algorithms)
机器学习常见算法简介 - 原文链接:http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/ 应 ...
- STL所有算法简介 (转) http://www.cnblogs.com/yuehui/archive/2012/06/19/2554300.html
STL所有算法简介 STL中的所有算法(70个) 参考自:http://www.cppblog.com/mzty/archive/2007/03/14/19819.htmlhttp://hi.baid ...
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
随机推荐
- Vue ES6
Vue ES6 Jade Scss Webpack Gulp 一直以来非常庆幸曾经有翻过<代码大全2>:这使我崎岖编程之路少了很多不必要的坎坷.它在软件工艺的话题中有写到一篇:“首先是 ...
- 积累的VC编程小技巧之编辑框
1.如何让对话框中的编辑框接收对话框的消息 ////////////////////////////////////////////////// 如何让对话框中的CEdit控件类接收对话框的消息/// ...
- 学习VC MFC开发必须了解的常用宏和指令
1.#include指令 包含指定的文件 2.#define指令 预定义,通常用它来定义常量(包括无参量与带参量),以及用来实现那些“表面似和善.背后一长串”的宏,它本身并不在编译过程中进行,而 ...
- 在实体类中将数据库中数据类型为CLOB的数据转化成String类型
@Lob @Basic(fetch = FetchType.EAGER) @Column(name = "JYAQ", columnDefinition = &qu ...
- <一年成为Emacs高手>更新到20130706版
这次更新比较多,加了第三方精品插件推荐,添加了我认为不错的Emacs社区. 见 原文
- ZipHelper 压缩和解压帮助类
ZipHelper 压缩和解压帮助类 关于本文档的说明 本文档基于ICSharpCode.SharpZipLib.dll的封装,常用的解压和压缩方法都已经涵盖在内,都是经过项目实战积累下来的 欢迎传播 ...
- Function 详解(一)
一直想写一系列关于javascript的东西,可惜从申请博客以来就一直抽不出时间来好好写上一番,今天终于熬到周末,是该好好整理一下,那么先从声明函数开始吧; 总所周知,在javascript中有匿名函 ...
- hdu 1530 Maximum Clique
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1530 题目分类:最大团问题 DP + DFS 代码: #include<bits/stdc++. ...
- Delphi实现窗口一直在桌面工作区内显示(重写WM_WINDOWPOSCHANGING消息)
有的时候我们要实现一个悬浮窗口,并使该窗口一直显示在桌面的工作区内.即整个窗口要一直显示在屏幕上,不能超出屏幕的上下左右边缘.此功能的实现也不难,我们需要自己写代码来响应窗口的WM_WINDOWPOS ...
- How to write simple HTTP proxy with Boost.Asio
How to write simple HTTP proxy with Boost.Asio How to write simple HTTP proxy with Boost.Asio Russia ...