cloudera learning2:HDFS
存入HDFS的文件会按块(block)划分,默认每块128MB。默认1个block还有2个备份。备份增加了数据的可靠性和提高计算效率(数据本地化)。
HDFS部署可选择不支持HA,也可选择支持HA。
NameNode内存中有metadata,metadata里主要记录的信息包括:file location,ownership,permissions,block's name and location。
metadata持久化在fsimage文件中,每次NameNode启动时加载到内存。Block location的信息并不存在fsimage中,而是启动后,dataNode定时发给NameNode.
对metadata进行的操作不仅保留在内存中,同时也会写到edit log文件中。当NameNode关闭后,内存中的metadata会消失,下次启动时,会动过edit log一条条还原所有的修改,这个过程导致NameNode启动非常的慢,后来增加了SecondaryNameNode,NameNode会定期的把fsimage和edit log传给Secondary NameNode. Secondary NameNode合并fsimage和log成为新的fsimg并传回NameNode,这样下次启动的时候,就可以只读fsimage了,大大减少启NameNode启动时间。每次SecondaryNameNode对fsimage的update叫做一次checkpoint。
SecondaryNameNode并不是NameNode的failover Node,只是它的“小秘书”。
SecondaryNameNode只在非HA的模式下存在,应该安装在与NameNode不同的机器上,SecondaryNameNode同样需要NameNode一样多的内存。
HDFS的HA是为了解决NameNode的单点问题。两个NameNode一个active,一个standby。standby负责checkpoint.
DataNode控制block的访问权限并保持与NameNode的通信。
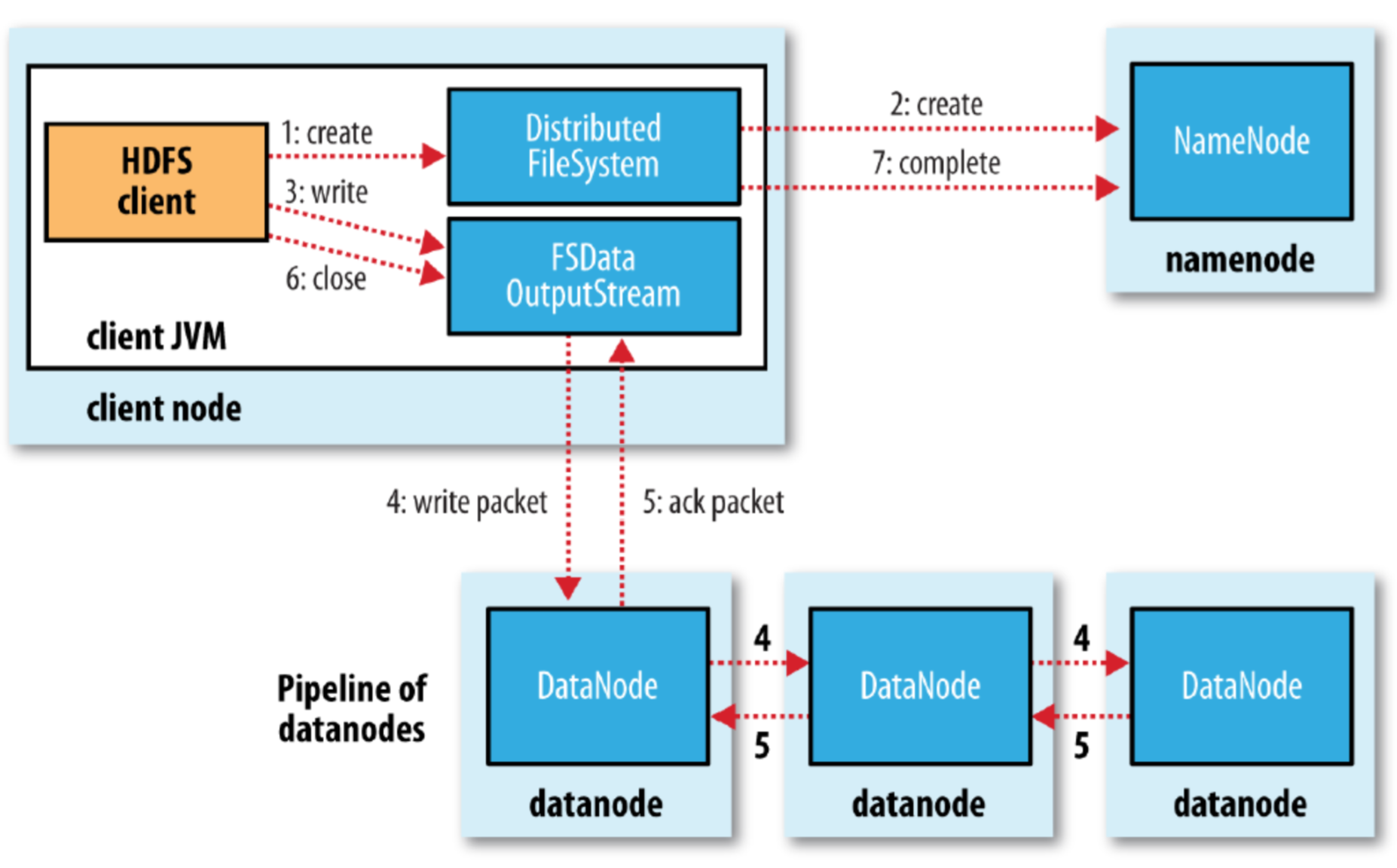
1.client connect to NameNode。
2.NameNode在metadata中为要写入的文件建立一条记录并返回可以写入的blockname和dataNode lists给client。
3.client connect 第一个DataNode,send data。
4.第一个DataNode接收到data后connect第二个DataNode,send data.
5.第二个DataNode又connect第三个dataNode,send data。
6.请求写入结果,并返回给client
7.client向NameNode发送写入完成信息。
在写入的过程中,如果第一个DataNode的pipeline断掉了,会有一个新的pipline建立起来,向第二个dataNode继续写。NameNode会继续找新的dataNode进行备份。
在block被写入时,client会对每一个block计算checksum同时发给dataNode,从而保持数据的完整性。
HDFS读数据流程:

1.client connect to NameNode。
2.Namenode返回要读出的数据所存放的datanode list(list中datanode的排序安照离client又近到远)和开头的几个block的名字。
3.client链接datanode读取数据,如果第一个datanode失去链接,则client去链接list中下一个datanode。
读取的过程中同样执行checksum。
Hadoop是机架感知的,在配好机架信息的前提下,hdfs的备份会存放在不同的机架。
DataNode每隔三秒向NameNode发送一次heartbeat,表示自己是health的。如果一段时间内NameNode没有收到某DataNode发送的heartbeat,则可认定这个DataNode lost,NameNode会把改dataNode上存储的blocks再在系统里进行一次备份,保证每个block的3备份。
Data never travels via a Namedata.
NameNode运行时,所有的metadata都在内存中,默认的NameNode堆大小为1G。1G的内存可以hold住1million的hdfs block。
cloudera learning2:HDFS的更多相关文章
- cloudera hbase集群简单思路
文章copy link:http://cloudera.iteye.com/blog/889468 链接所有者保留所有权! http://www.csdn.net/article/2013-05-10 ...
- hadoop cdh 4.5的安装配置
春节前用的shark,是从github下载的源码,自己编译.shark的master源码仅支持hive 0.9,支持hive 0.11的shark只是个分支,不稳定,官方没有发布release版,在使 ...
- Apache Pig处理数据示例
Apache Pig是一个高级过程语言,可以调用MapReduce查询大规模的半结构化数据集. 样例执行的环境为cloudera的单节点虚拟机 读取结构数据中的指定列 在hdfs上放置一个文件 [cl ...
- Hadoop-Impala学习笔记之入门
CDH quickstart vm包含了单节点的全套hadoop服务生态,可从https://www.cloudera.com/downloads/quickstart_vms/5-13.html下载 ...
- cdh日常维护常见问题及解决方案
为数据节点添加新硬盘 - 挂载硬盘到指定文件夹.如`/dfs_diskb`: - 打开cloudera manager -> hdfs -> 配置 -> DataNode -> ...
- 《ProgrammingHive》阅读笔记-第二章
书本第二章的一些知识点,在cloudera-quickstart-vm-5.8.0-0上进行操作. 配置文件 配置在/etc/hive/conf/hive-site.xml文件里面,采用mysql作为 ...
- Apache Hive处理数据示例
继上一篇文章介绍如何使用Pig处理HDFS上的数据,本文将介绍使用Apache Hive进行数据查询和处理. Apache Hive简介 首先Hive是一款数据仓库软件 使用HiveQL来结构化和查询 ...
- CDH 5.16.1 离线部署 & 通过 CDH 部署 Hadoop 服务
参考 Cloudera Enterprise 5.16.x Installing Cloudera Manager, CDH, and Managed Services Installation Pa ...
- Hello World on Impala
Cloudera Impala 官方教程 <Impala Tutorial>,解说了Impala一些基本操作,但操作步骤前后缺少连贯性,本文节W选<Impala Tutorial&g ...
随机推荐
- NET微信公众号开发-5.0微信支付(待测试)
开发前准备. 1.0微信支付官方开发者文档 2.0官方demo下载 我们用c#所以选择.net版本 不过这个官方的demo根本跑步起来 3.0官方demo运行起来解决方案 4.0微信支付官方.net版 ...
- 编辑 Ext 表格(一)——— 动态添加删除行列
一.动态增删行 在 ext 表格中,动态添加行主要和表格绑定的 store 有关, 通过对 store 数据集进行添加或删除,就能实现表格行的动态添加删除. (1) 动态添加表格的行 gridS ...
- mysql多表联合查询
转自:http://www.cnblogs.com/Toolo/p/3634563.html 多表连接,小分三种(笛卡尔积.内连接.外连接),多分五种 (笛卡尔积.内连接.左连接.右连接.全连接(my ...
- VMware如何实现和主机共享网络上网
VMware虚拟机的三种联网方法及原理 一.Brigde--桥接 :默认使用VMnet0 1.原理: Bridge 桥"就是一个主机,这个机器拥有两块网卡,分别处于两个局域网中,同时在& ...
- WPF下的仿QQ图片查看器
本例中的大图模式使用图片控件展示,监听控件的鼠标滚轮事件和移动事件,缩略图和鹰眼模式采用装饰器对象IndicatorObject和Canvas布局.百分比使用一个定时器,根据图片的放大倍数计算具体的数 ...
- 1.0 Quartz 2D 简介
本文并非最终版本,如有更新或更正会第一时间置顶,联系方式详见文末 如果觉得本文内容过长,请前往本人 “简书” Quartz2D须知: (1)Quartz 2D是苹果官方的二维绘图引擎,同时支持 ...
- Is It A Tree?[HDU1325][PKU1308]
Is It A Tree? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tot ...
- 提高C#代码质量-规范
[规范习惯]命名规范1-命名空间 使用<Company>.<Component>2-程序集不必与命名空间同名3-命名空间使用附复数4-避免与FCL的类型重名5-类型名称用名词6 ...
- 静态属性,直接把iis搞垮掉 Http error 503 Service Unavailable
属性有个好处,可以在get的时候做一些特殊处理,比如返回一个默认值,正是这个特性,吸引我讲静态字段修改了成静态属性,代码如下: public static string 微信订阅号 { get { i ...
- js-倒计时自动隐藏
<!doctype html><html><head><meta charset="utf-8"><title>无标题文 ...