SPARK_sql加载,hive以及jdbc使用
sql加载


格式

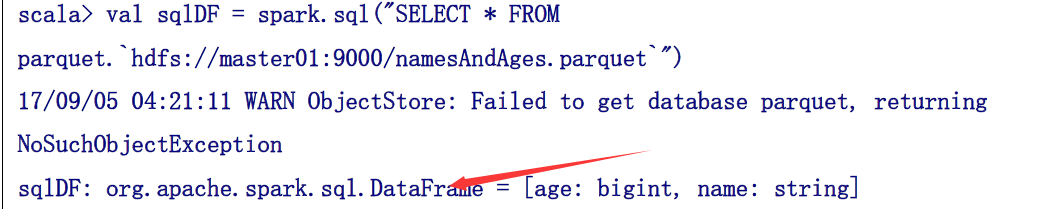
或者下面这种直接json加载

或者下面这种spark的text加载
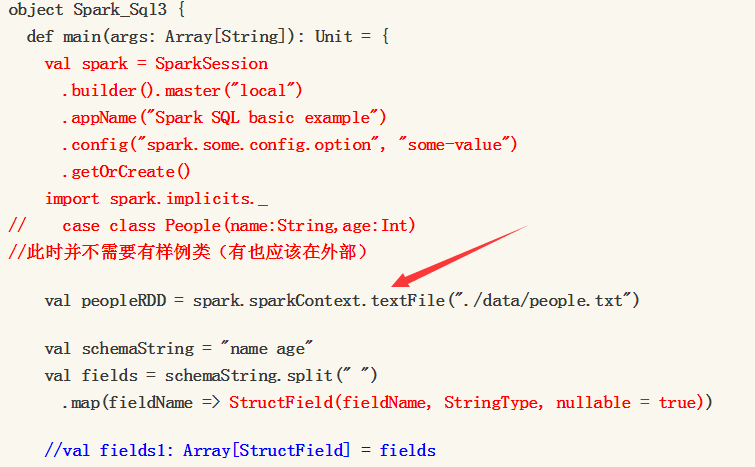

以及rdd的加载


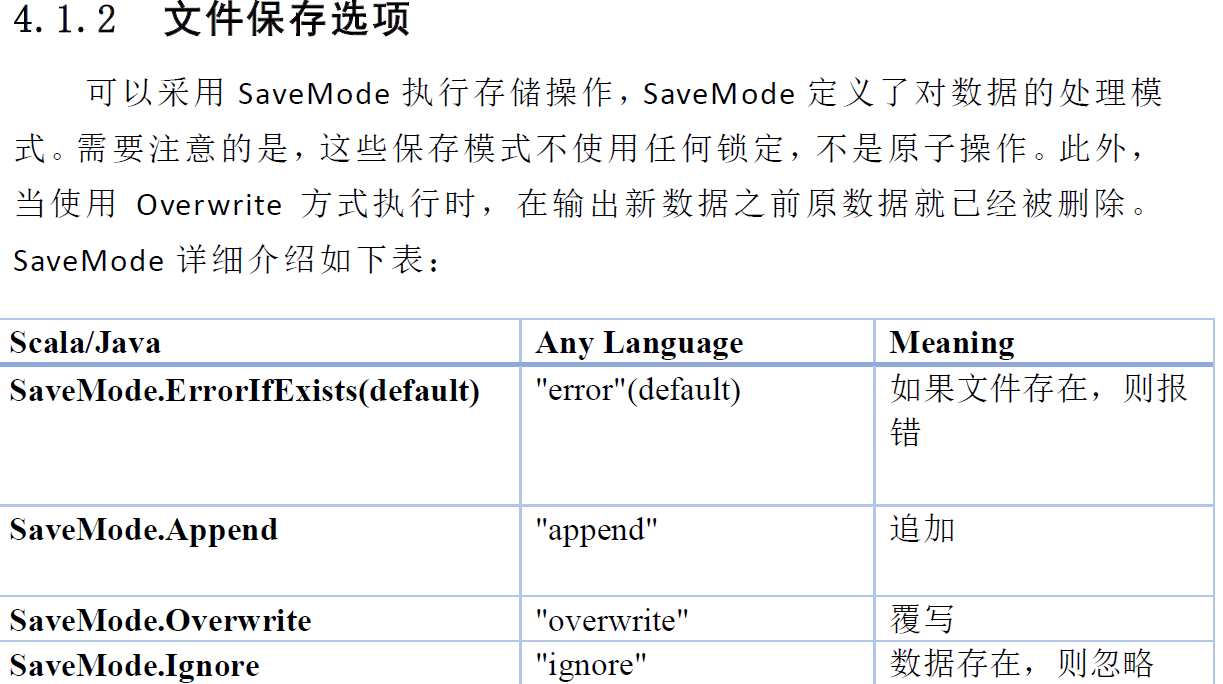

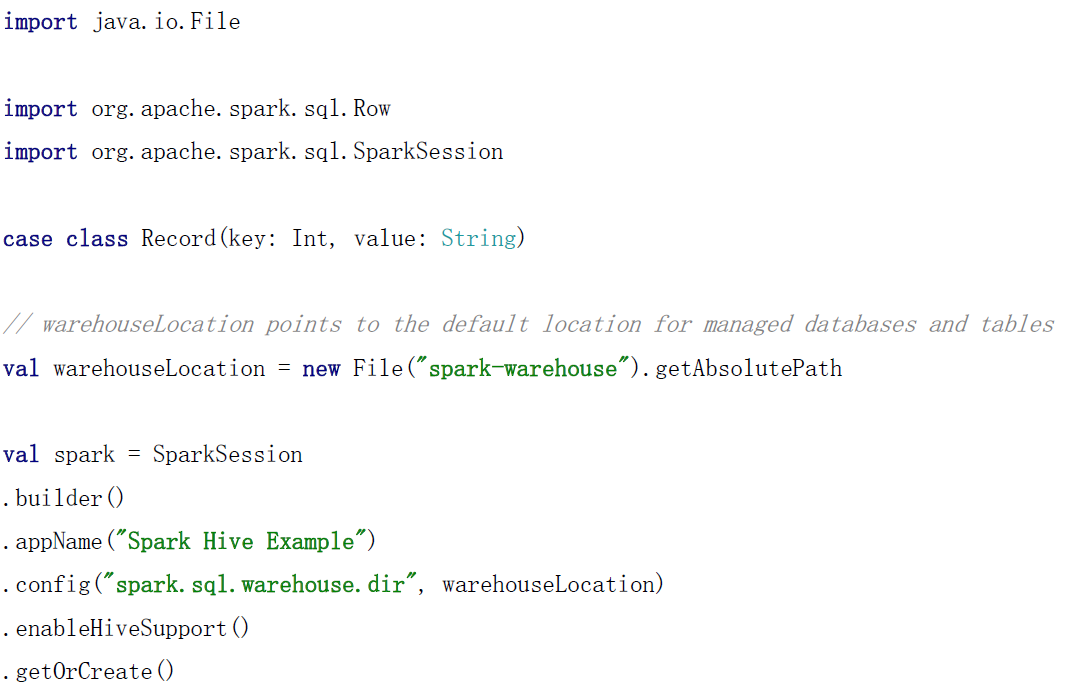
上述记得配置文件加入.mastrt("local")或者spark://master:7077


dataset的生成

下面是dataframe

下面是dataset





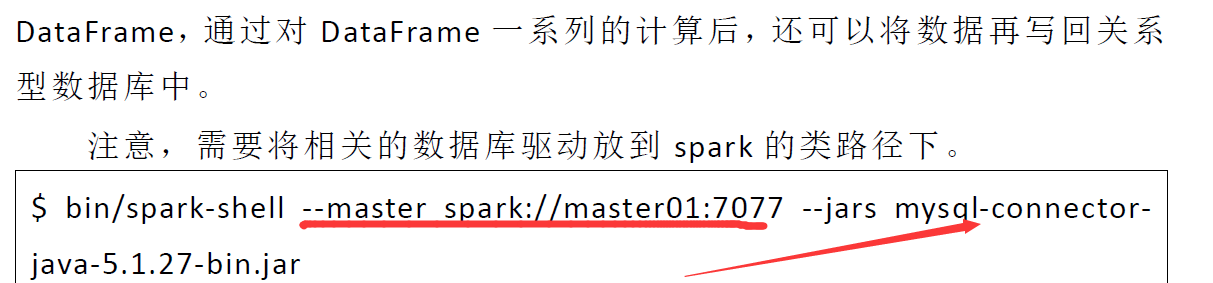
$ bin/spark-shell --master spark://master01:7077 --jars mysql-connector-java-5.1.27-bin.jar
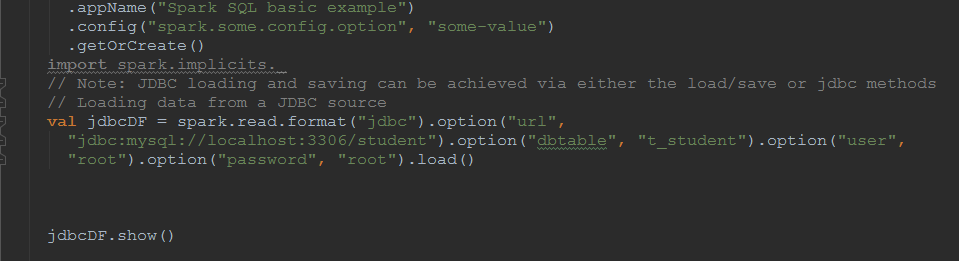
加载连接的两种方式

// Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
val jdbcDF = spark.read.format("jdbc").option("url",
"jdbc:mysql://master01:3306/mysql").option("dbtable", "db").option("user",
"root").option("password", "hive").load()
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "hive")
val jdbcDF2 = spark.read .jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)
保存数据的两种方式
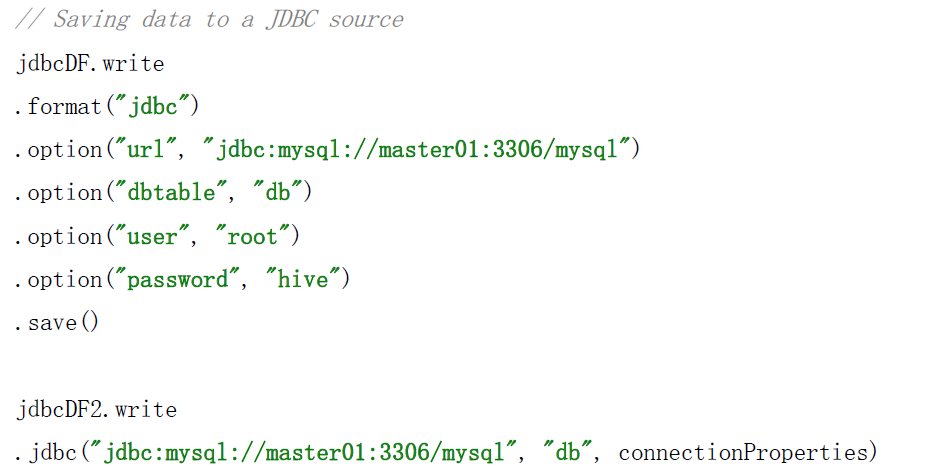
// Saving data to a JDBC source
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:mysql://master01:3306/mysql")
.option("dbtable", "db")
.option("user", "root")
.option("password", "hive")
.save()
jdbcDF2.write .jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)

// Specifying create table column data types on write
jdbcDF.write
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)
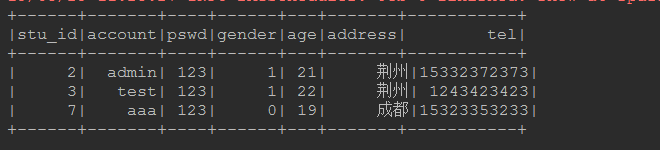



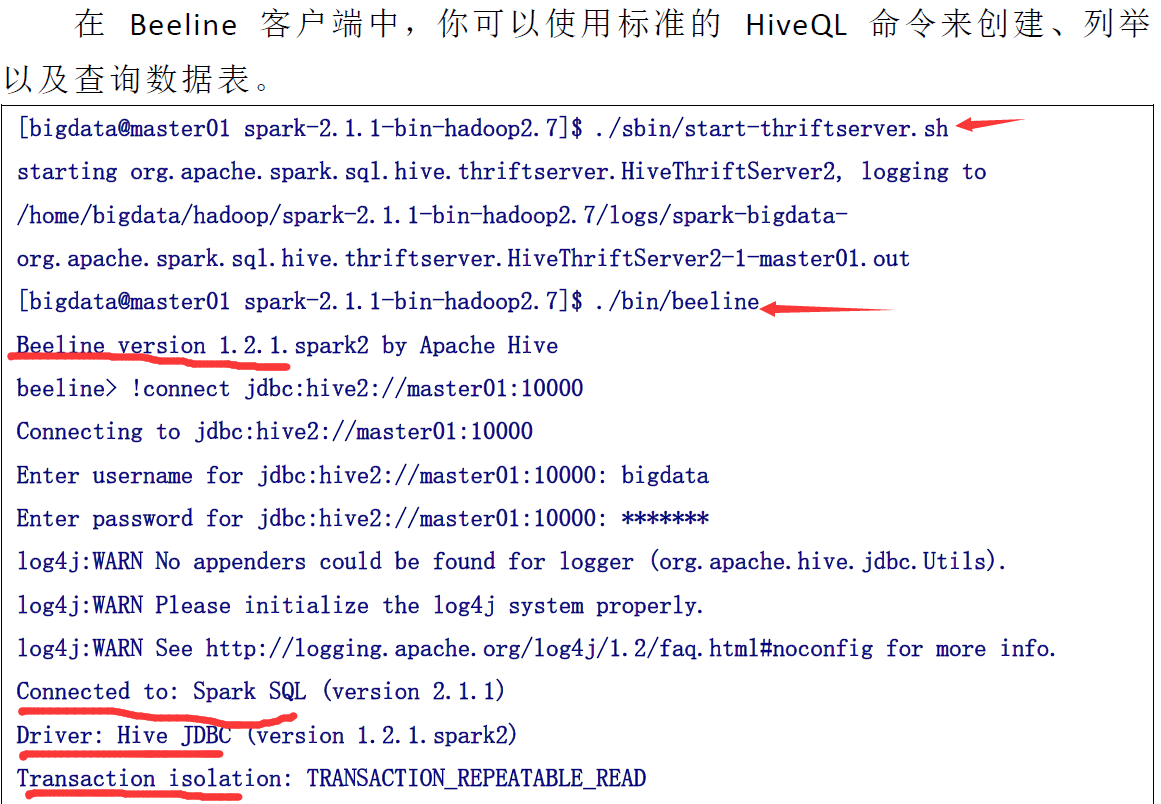


SPARK_sql加载,hive以及jdbc使用的更多相关文章
- kylin加载hive表错误:ERROR [http-bio-7070-exec-10] controller.TableController:189 : org/apache/hadoop/hive/conf/HiveConf java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConf 解决办法
一.问题背景 在kylin中加载hive表时,弹出提示框,内容是“oops!org/apache/hadoop/hive/conf/HiveConf”,无法加载hive表,查找kylin的日志时发现, ...
- Impala 加载Hive的UDF
Impala的UDF有两种: Native Imapal UDF:使用C++开发的,性能极高,官方性能测试比第二种高出将近10倍 Hive的UDF:是Hive中的UDF,直接加载到Impala中,优点 ...
- Spring Boot 2程序不能加载 com.mysql.jdbc.Driver 问题
用Spring Boot Starter 向导生成了一个很简单SpringBoot程序, 用到了 MySQL, 总是下面不能加载 Mysql driver class 错误. Cannot load ...
- java8--类加载机制与反射(java疯狂讲义3复习笔记)
本章重点介绍java.lang.reflect包下的接口和类 当程序使用某个类时,如果该类还没有被加载到内存中,那么系统会通过加载,连接,初始化三个步骤来对该类进行初始化. 类的加载时指将类的clas ...
- java加载机制整理
本文是根据李刚的<疯狂讲义>作的笔记,程序有的地方做了修改,特别是路径,一直在混淆,浪费了好多时间!!希望懂的同学能够指导本人,感激尽............ 1.jvm 和 类的关系 当 ...
- SpringJUnit4加载类目录下(src)和WEF-INF目录下的配置文件
路径说明: 一.加载类目录下的配置文件 @RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration("classpath:ap ...
- Java程序设计19——类的加载和反射-Part-B
接下来可以随意提供一个简单的主类,该主类无须编译就可使用上面的CompileClassLoader来运行它. package chapter18; public class Hello { publi ...
- Java进阶知识点8:高可扩展架构的利器 - 动态模块加载核心技术(ClassLoader、反射、依赖隔离)
一.背景 功能模块化是实现系统能力高可扩展性的常见思路.而模块化又可分为静态模块化和动态模块化两类: 1. 静态模块化:指在编译期可以通过引入新的模块扩展系统能力.比如:通过maven/gradle引 ...
- spark SQL (五)数据源 Data Source----json hive jdbc等数据的的读取与加载
1,JSON数据集 Spark SQL可以自动推断JSON数据集的模式,并将其作为一个Dataset[Row].这个转换可以SparkSession.read.json()在一个Dataset[Str ...
随机推荐
- zoj-3433-Gu Jian Qi Tan
/* Gu Jian Qi Tan -------------------------------------------------------------------------------- T ...
- 关于Python安装官方whl包和tar.gz包的方法详解
Windows环境: 安装whl包:pip install wheel -> pip install **.whl 安装tar.gz包:cd到解压后路径,python setup.py inst ...
- Python list和dict方法
###list类的方法 ###append 列表内最后增加一个元素a = [1,2,3,4,5,6,"dssdsd"]a.append(5)print(a) ###clear 清空 ...
- css伪类(Pseudo-classes)
简介:伪类(Pseudo classes)是选择符的螺栓,用来指定一个或者与其相关的选择符的状态.它们的形式是selector:pseudo class { property: value; },简单 ...
- 对称加密——对入参进行DES加密处理
体验更优排版请移步原文:http://blog.kwin.wang/programming/symmetric-encryption-des-js-java.html 对称加密是最快速.最简单的一种加 ...
- 将本地Jar包安装到maven仓库中去
开发中会遇到无法通过pom.xml下载jar包的情况,遇到这种情况我们可以手动在本地安装jar包到本地仓库中去,这样就可以下次再用到的话不用再次联网下载,具体以oracle的驱动包ojdbc6.jar ...
- 让低版本IE支持Html5的新语义标签
HTML5能为我们做的事儿很多,最为可口的就是语义化标签的应用,如果你已经在Chrome或者其他支持HTML5的浏览器上用过它的牛x,那这篇文章对你一定有用,因为现在你也可以在IE上用到HTML5. ...
- My97DatePicker日期控件的使用
本文演示如何在MyEclipse项目中使用My97DatePicker日期控件 1.下载My97DatePicker日期控件, My97DatePicker日期控件下载地址 2.在MyEclipse项 ...
- 全文搜索技术—Solr
1. 学习计划 1. Solr的安装及配置 a) Solr整合tomcat b) Solr后台管理功能介绍 c) 配置中文分析器 2. 使用Solr的后台管理索引库 a) ...
- 使用OpenSsl自己CA根证书,二级根证书和颁发证书(亲测步骤)
---恢复内容开始--- 一.介绍 企业自用, 到证书机构签发证书的费用和时间等都可以省下..... SSl证书的背景功用.......(省略万字,不废话) 可以参考: SSL证书_百度百科 X509 ...