sqlserver锁机制详解(sqlserver查看锁)
简介
在SQL Server中,每一个查询都会找到最短路径实现自己的目标。如果数据库只接受一个连接一次只执行一个查询。那么查询当然是要多快好省的完成工作。但对于 大多数数据库来说是需要同时处理多个查询的。这些查询并不会像绅士那样排队等待执行,而是会找最短的路径执行。因此,就像十字路口需要一个红绿灯那 样,SQL Server也需要一个红绿灯来告诉查询:什么时候走,什么时候不可以走。这个红绿灯就是锁。

图1.查询可不会像绅士们那样按照次序进行排队
为什么需要锁
在开始谈锁之前,首先要简单了解一下事务和事务的ACID属性。如果你了解了事务之间的影响方式,你就应该知道在数据库中,理论上所有的事务之间应 该是完全隔离的。但是实际上,要实现完全隔离的成本实在是太高(必须是序列化的隔离等级才能完全隔离,这个并发性有点….)。所以,SQL Server默认的Read Commited是一个比较不错的在隔离和并发之间取得平衡的选择。SQL Server通过锁,就像十字路口的红绿灯那样,告诉所有并发的连接,在同一时刻上,那些资源可以读取,那些资源可以修改。前面说到,查询本身可不是什么 绅士,所以需要被监管。当一个事务需要访问的资源加了其所不兼容的锁,SQL Server会阻塞当前的事务来达成所谓的隔离性。直到其所请求资源上的锁被释放,如图2所示。
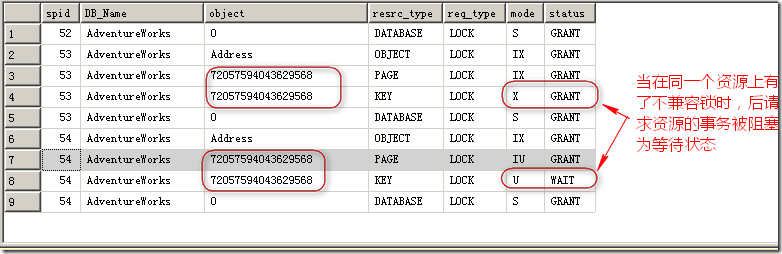
图2.SQL Server通过阻塞来实现并发
如何查看锁
了解SQL Server在某一时间点上的加锁情况无疑是学习锁和诊断数据库死锁和性能的有效手段。我们最常用的查看数据库锁的手段不外乎两种:
使用sys.dm_tran_locks这个DMV
SQL Server提供了sys.dm_tran_locks这个DMV来查看当前数据库中的锁,前面的图2就是通过这个DMV来查看的.
这里值得注意的是sys.dm_tran_locks这个DMV看到的是在查询时间点的数据库锁的情况,并不包含任何历史锁的记录。可以理解为数据 库在查询时间点加锁情况的快照。sys.dm_tran_locks所包含的信息分为两类,以resource为开头的描述锁所在的资源的信息,另一类以 request开头的信息描述申请的锁本身的信息。如图3所示。更详细的说明可以查看MSDN(http://msdn.microsoft.com/en-us/library/ms190345.aspx)
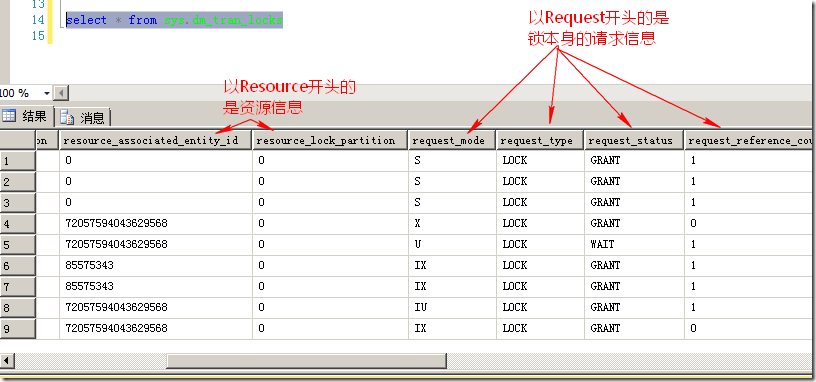
图3.sys.dm_tran_locks
这个DMV包含的信息比较多,所以通常情况下,我们都会写一些语句来从这个DMV中提取我们所需要的信息。如图4所示。
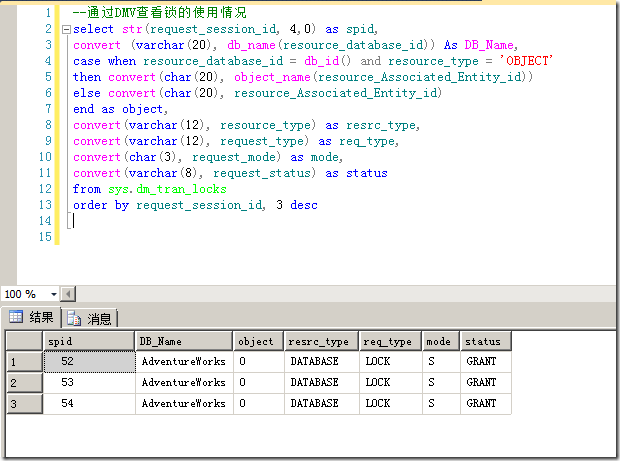
图4.写语句来提取我们需要的锁信息
使用Profiler来捕捉锁信息
我们可以通过Profiler来捕捉锁和死锁的相关信息,如图5所示。
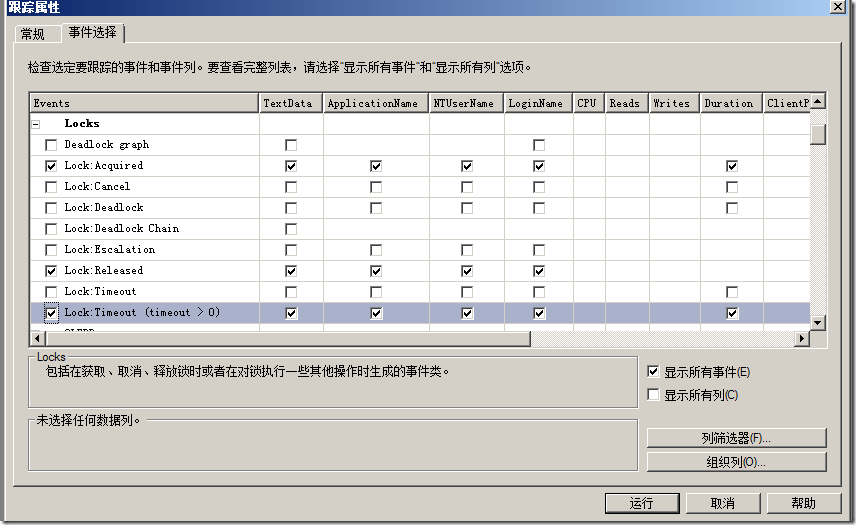
图5.在Profiler中捕捉锁信息
但默认如果不过滤的话,Profiler所捕捉的锁信息包含SQL Server内部的锁,这对于我们查看锁信息非常不方便,所以往往需要筛选列,如图6所示。
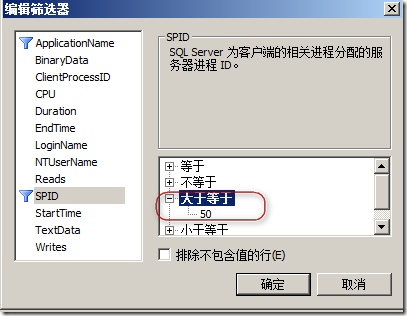
图6.筛选掉数据库锁的信息
所捕捉到的信息如图7所示。
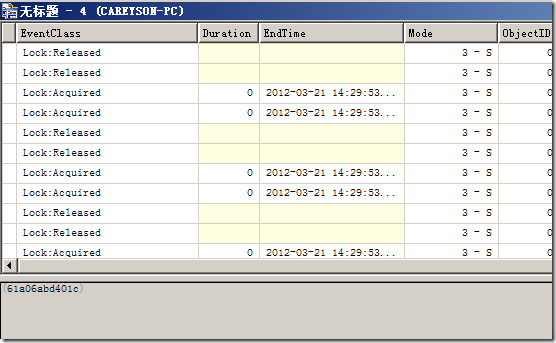
图7.Profiler所捕捉到的信息
锁的粒度
锁是加在数据库对象上的。而数据库对象是有粒度的,比如同样是1这个单位,1行,1页,1个B树,1张表所含的数据完全不是一个粒度的。因此,所谓锁的粒度,是锁所在资源的粒度。所在资源的信息也就是前面图3中以Resource开头的信息。
对于查询本身来说,并不关心锁的问题。就像你开车并不关心哪个路口该有红绿灯一样。锁的粒度和锁的类型都是由SQL Server进行控制的(当然你也可以使用锁提示,但不推荐)。锁会给数据库带来阻塞,因此越大粒度的锁造成更多的阻塞,但由于大粒度的锁需要更少的锁, 因此会提升性能。而小粒度的锁由于锁定更少资源,会减少阻塞,因此提高了并发,但同时大量的锁也会造成性能的下降。因此锁的粒度对于性能和并发的关系如图 8所示。
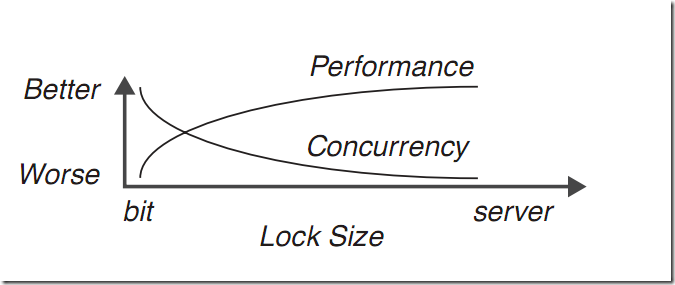
图8.锁粒度对于性能和并发的影响
SQL Server决定所加锁的粒度取决于很多因素。比如键的分布,请求行的数量,行密度,查询条件等。但具体判断条件是微软没有公布的秘密。开发人员不用担心SQL Server是如何决定使用哪个锁的。因为SQL Server已经做了最好的选择。
在SQL Server中,锁的粒度如表1所示。
|
资源 |
说明 |
|---|---|
|
RID |
用于锁定堆中的单个行的行标识符。 |
|
KEY |
索引中用于保护可序列化事务中的键范围的行锁。 |
|
PAGE |
数据库中的 8 KB 页,例如数据页或索引页。 |
|
EXTENT |
一组连续的八页,例如数据页或索引页。 |
|
HoBT |
堆或 B 树。 用于保护没有聚集索引的表中的 B 树(索引)或堆数据页的锁。 |
|
TABLE |
包括所有数据和索引的整个表。 |
|
FILE |
数据库文件。 |
|
APPLICATION |
应用程序专用的资源。 |
|
METADATA |
元数据锁。 |
|
ALLOCATION_UNIT |
分配单元。 |
|
DATABASE |
整个数据库。 |
表1.SQL Server中锁的粒度
锁的升级
前面说到锁的粒度和性能的关系。实际上,每个锁会占96字节的内存,如果有大量的小粒度锁,则会占据大量的内存。
下面我们来看一个例子,当我们选择几百行数据时(总共3W行),SQL Server会加对应行数的Key锁,如图9所示
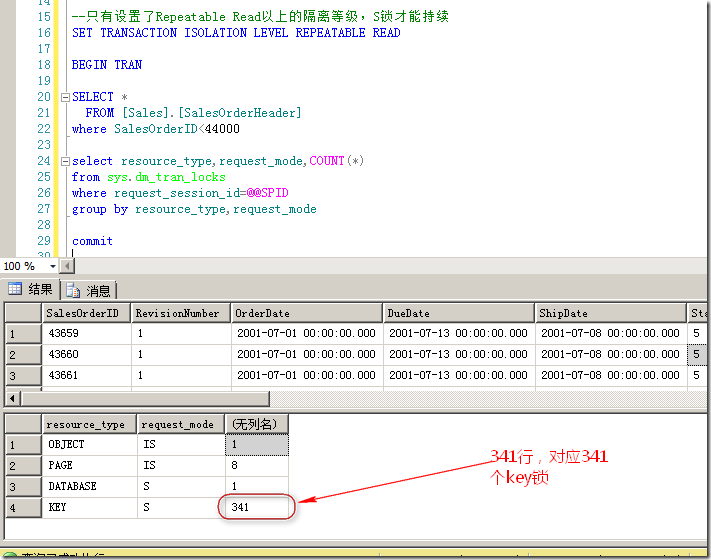
图9.341行,则需要动用341个key锁
但当所取得的行的数目增大时,比如说6000(表中总共30000多条数据),此时如果用6000个键锁的话,则会占用大约 96*6000=600K左右的内存,所以为了平衡性能与并发之间的关系,SQL Server使用一个表锁来替代6000个key锁,这就是所谓的锁升级。如图10所示。
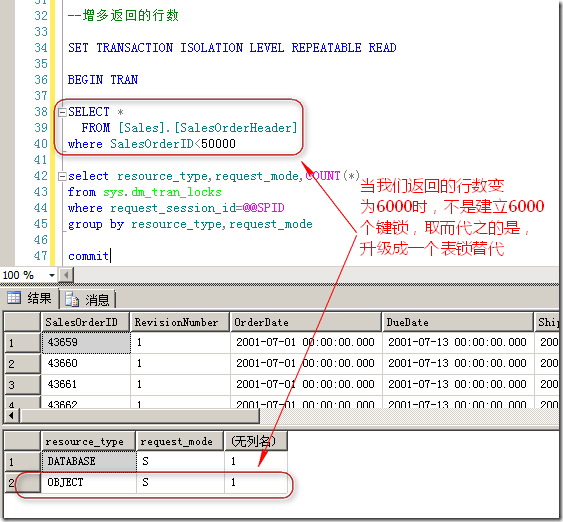
图10.使用一个表锁代替6000个键锁
虽然使用一个表锁代替了6000个键锁,但是会影响到并发,我们对不在上述查询中行做更新(id是50001,不在图10中查询的范围之内),发现会造成阻塞,如图11所示。
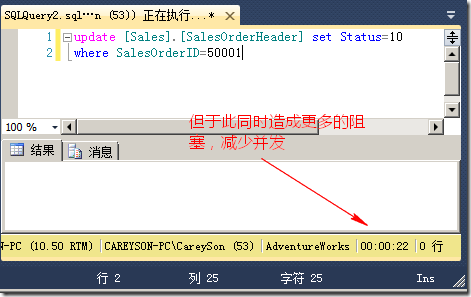
图11.锁升级提升性能以减少并发为代价
锁模式
当SQL Server请求一个锁时,会选择一个影响锁的模式。锁的模式决定了锁对其他任何锁的兼容级别。如果一个查询发现请求资源上的锁和自己申请的锁兼容,那么 查询就可以执行下去,但如果不兼容,查询会被阻塞。直到所请求的资源上的锁被释放。从大类来看,SQL Server中的锁可以分为如下几类:
共享锁(S锁):用于读取资源所加的锁。拥有共享锁的资源不能被修改。共享锁默认情况下是读取了资源马上被释放。比如我读100条数据,可以想像成读完了 第一条,马上释放第一条,然后再给第二条数据上锁,再释放第二条,再给第三条上锁。以此类推直到第100条。这也是为什么我在图9和图10中的查询需要将 隔离等级设置为可重复读,只有设置了可重复读以上级别的隔离等级或是使用提示时,S锁才能持续到事务结束。实际上,在同一个资源上可以加无数把S锁。
排他锁(X锁): 和其它任何锁都不兼容,包括其它排他锁。排它锁用于数据修改,当资源上加了排他锁时,其他请求读取或修改这个资源的事务都会被阻塞,知道排他锁被释放为止。
更新锁(U锁) :U锁可以看作是S锁和X锁的结合,用于更新数据,更新数据时首先需要找到被更新的数据,此时可以理解为被查找的数据上了S锁。当找到需要修改的数据时, 需要对被修改的资源上X锁。SQL Server通过U锁来避免死锁问题。因为S锁和S锁是兼容的,通过U锁和S锁兼容,来使得更新查找时并不影响数据查找,而U锁和U锁之间并不兼容,从而 减少了死锁可能性。这个概念如图12所示。
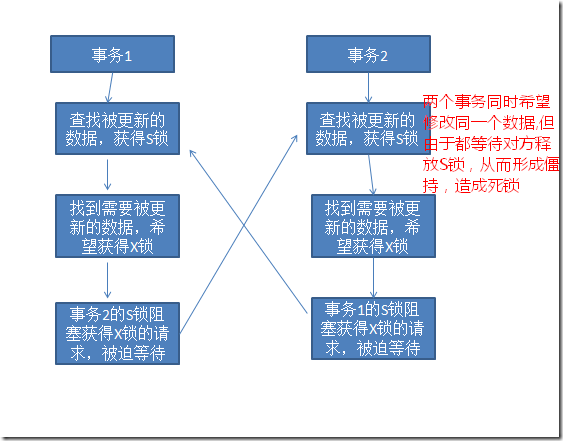
图12.如果没有U锁,则S锁和X锁修改数据很容易造成死锁
意向锁(IS,IU,IX):意向锁与其说是锁,倒不如说更像一个指示器。在SQL Server中,资源是有层次的,一个表中可以包含N个页,而一个页中可以包含N个行。当我们在某一个行中加了锁时。可以理解成包含这个行的页,和表的一 部分已经被锁定。当另一个查询需要锁定页或是表时,再一行行去看这个页和表中所包含的数据是否被锁定就有点太痛苦了。因此SQL Server锁定一个粒度比较低的资源时,会在其父资源上加上意向锁,告诉其他查询这个资源的某一部分已经上锁。比如,当我们更新一个表中的某一行时,其 所在的页和表都会获得意向排他锁,如图13所示。

图13.当更新一行时,其所在的页和表都会获得意向锁
其它类型的构架锁,键范围锁和大容量更新锁就不详细讨论了,参看MSDN(http://msdn.microsoft.com/zh-cn/library/ms175519.aspx)
锁之间的兼容性微软提供了一张详细的表,如图14所示。
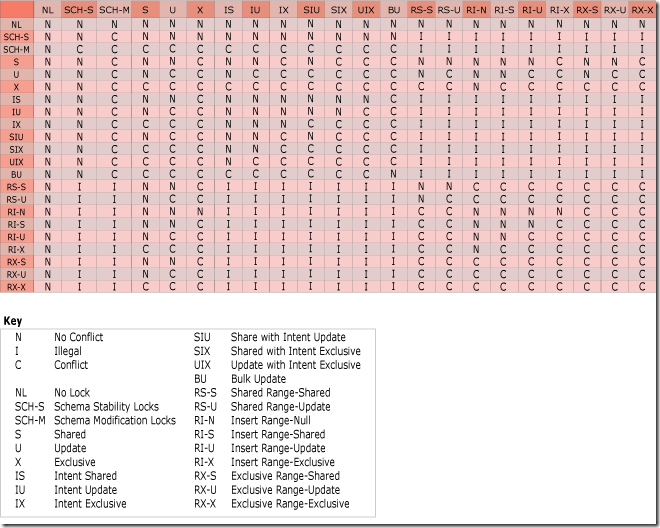
图14.锁的兼容性列表
理解死锁
当两个进程都持有一个或一组锁时,而另一个进程持有的锁和另一个进程视图获得的锁不兼容时。就会发生死锁。这个概念如图15所示。
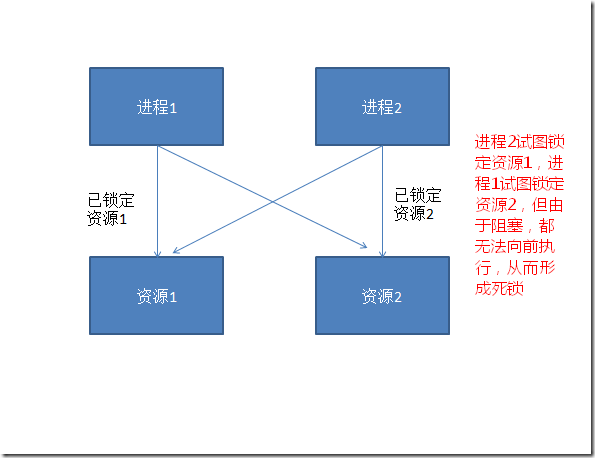
图15.死锁的简单示意
下面我们根据图15的概念,来模拟一个死锁,如图16所示。
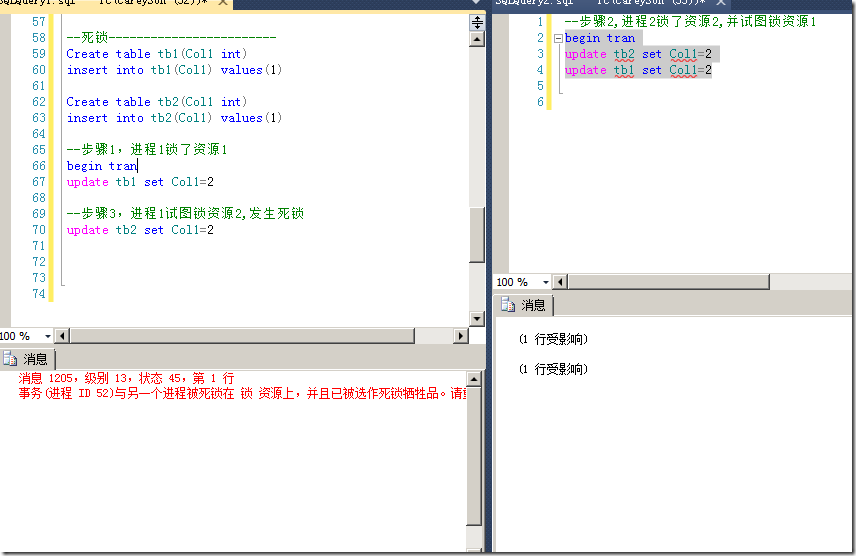
图16.模拟一个死锁
可以看到,出现死锁后,SQL Server并不会袖手旁观让这两个进程无限等待下去,而是选择一个更加容易Rollback的事务作为牺牲品,而另一个事务得以正常执行。
sqlserver锁机制详解(sqlserver查看锁)的更多相关文章
- mysql的锁机制详解
这段时间一直在学习mysql数据库.项目组一直用的是oracle,所以对mysql的了解也不深.本文主要是对mysql锁的总结. Mysql的锁主要分为3大类: 表级锁:存储引擎为Myisam.锁住整 ...
- 关于MySQL的锁机制详解
锁概述 MySQL的锁机制,就是数据库为了保证数据的一致性而设计的面对并发场景的一种规则. 最显著的特点是不同的存储引擎支持不同的锁机制,InnoDB支持行锁和表锁,MyISAM支持表锁. 表锁就是把 ...
- 关于MySQL中的锁机制详解
锁概述 MySQL的锁机制,就是数据库为了保证数据的一致性而设计的面对并发场景的一种规则. 最显著的特点是不同的存储引擎支持不同的锁机制,InnoDB支持行锁和表锁,MyISAM支持表锁. 表锁就是把 ...
- mysql锁机制详解
前言 大概几个月之前项目中用到事务,需要保证数据的强一致性,期间也用到了mysql的锁,但当时对mysql的锁机制只是管中窥豹,所以本文打算总结一下mysql的锁机制. 本文主要论述关于mysql锁机 ...
- mysql事务与锁机制详解
一.事务 1.事务简介 (1)事务的场景 转账:一个账户减少,另一个账户增加.两个动作同时成功或者同时失败.就要开启事务. (2)事务定义 事务是数据库管理系统执行过程中的一个逻辑单元,由一个有限的数 ...
- sqlserver锁表、解锁、查看锁表
sqlserver锁表.解锁.查看锁表 http://www.cnblogs.com/zfanlong1314/p/3698566.html http://www.cnblogs.com/chjf20 ...
- “全栈2019”Java多线程第三十二章:显式锁Lock等待唤醒机制详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- MySQL详解--锁,事务
http://www.cnblogs.com/jukan/p/5670950.html http://blog.csdn.net/xifeijian/article/details/20313977 ...
- MySQL详解--锁,事务(转)
锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算资源(如CPU.RAM.I/O等)的争用以外,数据也是一种供许多用户共享的资源.如何保证数据并发访问的一致性.有效性是所有数 ...
随机推荐
- ajax刷新输出实时数据
setInterval('shuaxin()',3000); function shuaxin(){ $.ajax({//股票 url:"http://apimarkets.wallstre ...
- C语言 五子棋
#include <stdlib.h> #include <stdio.h> #include <conio.h> #include <string.h> ...
- 深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 最近接下来几篇博文会回到神经网络结构 ...
- hdu 5001(概率DP)
Walk Time Limit: 30000/15000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Subm ...
- Porting of cURL to Android OS using NDK (from The Software Rogue)
Porting of cURL to Android OS using NDK In continuing my journey into Android territory, I decided ...
- EF – 2.EF数据查询基础(上)查询数据的实用编程技巧
目录 5.4.1 查询符合条件的单条记录 EF使用SingleOrDefault()和Find()两个方法查询符合条件的单条记录. 5.4.2 Entity Framework中的内部数据缓存 DbS ...
- Web开发入门知识小总结
原来是写给 http://www.zhihu.com/question/22689579 的答案,也算是学了一学期web课程后的一点小总结,搬运到博客里存一下吧~ ================== ...
- [实战]MVC5+EF6+MySql企业网盘实战(14)——思考
写在前面 从上面更新编辑文件夹,就一直在思考一个问题,之前编辑文件夹名称,只是逻辑上的修改,但是保存的物理文件或者文件夹名称并没有进行修改,这样就导致一个问题,就是在文件或者文件夹修改名称后就会找不到 ...
- 浅谈css中浮动和清除浮动带来的影响
有很多时候,我们都会用到浮动,而我们有时候对浮动只是一知半解,却不是太清楚它到底是怎么回事,不知道各位有没有和我一样的感觉,只知道用它,却不知道它到底是怎么回事,所以,在学习的过程中,就要把一个概念不 ...
- bzoj 1483 链表 + 启发式合并
思路:将颜色相同的建成一个链表, 变颜色的时候进行链表的启发式合并.. 因为需要将小的接到大的上边,所以要用个f数组. #include<bits/stdc++.h> #define LL ...