使用ScrapySharp快速从网页中采集数据
ScrapySharp是一个帮助我们快速实现网页数据采集的库,它主要提供了如下两个功能
- 从Url获取Html数据
- 提供CSS选择器的方式解析Html节点
安装:
ScrapySharp可以直接从Nuget上下载,直接从Package Console里面输入如下命令即可:
PM> Install-Package ScrapySharp
Html下载
首先我们来看看它的Html下载功能,它是通过ScrapingBrowser类来实现的:
var browser = new ScrapingBrowser();
var html = browser.DownloadString(new
Uri("http://www.cnblogs.com/"));
这个只是一个简单的示例,实际上ScrapingBrowser的功能还是非常全面的,常见的功能如:Charset探测,AutoRedirect、Cache、 Proxy、Cookie、UserAgent、表单提交等都支持得非常好,用它来获取网页比HttClient要方便很多。
Html解析
ScrapySharp的Html解析是基于大名鼎鼎的HtmlAgilityPack来实现的,它主要提供了两个扩展函数CssSelect和CssSelect:
static
IEnumerable<HtmlNode> CssSelect(this
HtmlNode node, string expression);
static
IEnumerable<HtmlNode> CssSelect(this
IEnumerable<HtmlNode> nodes, string expression);
static
IEnumerable<HtmlNode> CssSelectAncestors(this
HtmlNode node, string expression);
static
IEnumerable<HtmlNode> CssSelectAncestors(this
IEnumerable<HtmlNode> nodes, string expression);
相比HtmlAgilityPack提供的层级式解析和Xpath方式的解析比起来,CSS选择器的更为简单快捷,这里以解析博客园的首页标题为例,首先用开发者工具定位标题,可以看到其HTML结构的方式如下:
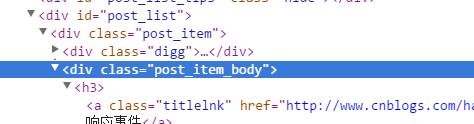
解析的代码如下:
var doc = new
HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
var nodes = docNode.CssSelect(".titlelnk");
foreach (var htmlNode in nodes)
{
Console.WriteLine(htmlNode.InnerText);
}
其中关键代码只有docNode.CssSelect(".titlelnk")一句,非常简洁。另外,由于CSS方式比较灵活,如下方式也能获取到标题
var nodes = docNode.CssSelect(".post_item_body > h3");
var nodes = docNode.CssSelect("div#post_list").CssSelectAncestors("h3");
最后,列举一下常用的CSS查询,以方便后续的使用:
html.CssSelect("div"); //all div elements
html.CssSelect("div.content"); //all div elements with css class 'content'
html.CssSelect("div.widget.monthlist"); //all div elements with the both css class
html.CssSelect("#postPaging"); //all HTML elements with the id postPaging
html.CssSelect("div#postPaging.testClass"); // all HTML elements with the id postPaging and css class testClass
html.CssSelect("div.content > p.para"); //p elements who are direct children of div elements with css class 'content'
html.CssSelect("input[type = text].login"); // textbox with css class login
更多的CSS选择器使用方法可以参看W3的网页:CSS 选择器参考手册
使用ScrapySharp快速从网页中采集数据的更多相关文章
- Web网页中动态数据区域的识别与抽取 Dynamical Data Regions Identification and Extraction in Web Pages
Web网页中动态数据区域的识别与抽取 Dynamical Data Regions Identification and Extraction in Web Pages Web网页中动态数据区域的识别 ...
- 网页中的数据的4个处理方式:CRUD(Creat, Retrive, Update, Delete)
网页中的数据的4个处理方式:CRUD(Creat, Retrive, Update, Delete) 2018-12-21, 后续完善
- 使用Xpath从网页中获取数据
/// <summary> /// 从官方网站中抓取产品信息存放在本地数据库中 /// </summary> /// <returns></returns&g ...
- 使用 CSS 选择器从网页中提取数据
在 R 中,关于网络爬虫最简单易用的扩展包是 rvest.运行以下代码从 CRAN 上安装:install.packages("rvest")首先,加载包并用 read_html( ...
- 【转载】使用 gnuplot 在网页中显示数据
来源:http://www.ibm.com/developerworks/cn/aix/library/au-gnuplot/ 简介 gnuplot 是一个用于生成趋势图和其他图形的工具.它通常用于收 ...
- PHP 爬取网页中表格数据
public function spider_j($page) { $url="http://aaa/bbb".$page."_0/"; $fcontents= ...
- 通过spark-sql快速读取hive中的数据
1 配置并启动 1.1 创建并配置hive-site.xml 在运行Spark SQL CLI中需要使用到Hive Metastore,故需要在Spark中添加其uris.具体方法是将HIVE_CON ...
- Asp.net网页中DataGridView数据导出到Excel
经过上网找资料,终于找到一种可以直接将GridView中数据导出到Excel文件的方法,归纳方法如下: 1. 注:其中的字符集格式若改为“GB2312”,导出的部分数据可能为乱码: 导出之前需要关闭分 ...
- css注入获取网页中的数据
<style><?php echo htmlspecialchars($_GET['x']);?></style> <br><br>< ...
随机推荐
- centos6.5 安装、启动vnc
一.安装vnc 1.确保当前账号是root2.查看本机是否已经安装vncserver rpm -qa|grep tigervnc 3.安装vncserver yum -y install tigerv ...
- free之后将指针置为NULL
free一个指针,只是将指针指向的内存空间释放掉了,并没有将指针置为NULL,指针仍指向被释放掉的内存的地址,在判断指针是否为NULL的时候,通常是通过if(pt == NULL) ,这时,导致指针成 ...
- 20165301 预备作业二:学习基础和C语言基础调查
<做中学>读后感及C语言学习调查 读<做中学>有感 娄老师在文章中多次提到「做中学(Learning By Doing)」的概念,并通过娄老师自己的减肥经历.五笔练习经历.乒乓 ...
- 大理石在哪儿(UVa10474)
题目具体描述见:https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=835&a ...
- bzoj 1115 转换+阶梯博弈
思路:我打了半天的表找规律.... 我们将每两个数的差值看成一堆堆石子,那么题目实际上就变为了 从当前堆可以拿出一些石子放到下一堆里去,就变成了一个阶梯博弈... #include<bits/ ...
- Nodejs JSON.parse()无法解析ObjectID和ISODate的问题
一个早上搞清楚了一个问题,关于Nodjes JSON.parse()方法只能解析字符串.布尔值.数字等,但不能解析ObjectID及ISODate的值 原因:<How to handle Obj ...
- 井字棋游戏升级版 - TopTicTacToe项目 简介
一.游戏简介 井字棋是一款世界闻名的游戏,不用我说,你一定知道它的游戏规则. 这款游戏简单易学,玩起来很有意思,不过已经证明出这款游戏如果两个玩家都足够聪明的话, 是很容易无法分出胜负的,即我们得到的 ...
- java 数组操作方法
数组操作方法: 实现数组拷贝: 语法:System.arraycopy(源数组名称,源数组拷贝开始索引,目标数组名称,目标数组拷贝数组索引,长度) 数组A:1 . 2 . 3 . 4 . 5 . 6 ...
- hibernate for循环执行添加操作出错问题
操作数据库使用hibernate框架 hibernate插入对象的时候,对于id唯一,数据库设置为自增的时候执行完操作后会将id赋予该对象 再次插入就会出现问题. 由于session缓存,得再研究下.
- xpath相关巩固
python爬虫xpath的语法 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历. XPath 是 W3C XSLT 标准的主要元素,并且 ...