Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用
Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
- settings.py 文件的使用
- 想要详细查看 settings.py文件的更多内容,可查看中文文档:
Settings 中配置 USER_AGENTS
- 在 settings.py 文件中很多东西默认是给注释掉的,当我们需要使用的时候,根据注释的提示,我们编写我们自己的内容
- 例如:
- 我们想设置一个 USER_AGENT 列表
- 在 settings.py 文件中找到 USER_AGENT ,拷贝常用的 USER _AGENT 值在它下面
- 但是 settings 只有一行,就是没有具体的内容,我们想要使用的话,就需要我们自己去填写
- 这就需要我们自己在网上找到常用的浏览器 User-Agent 值, 我找到了一些,想要使用直接拷贝就可以
- 在 settings.py 文件中找到 USER_AGENT ,拷贝常用的 USER _AGENT 值在它下面
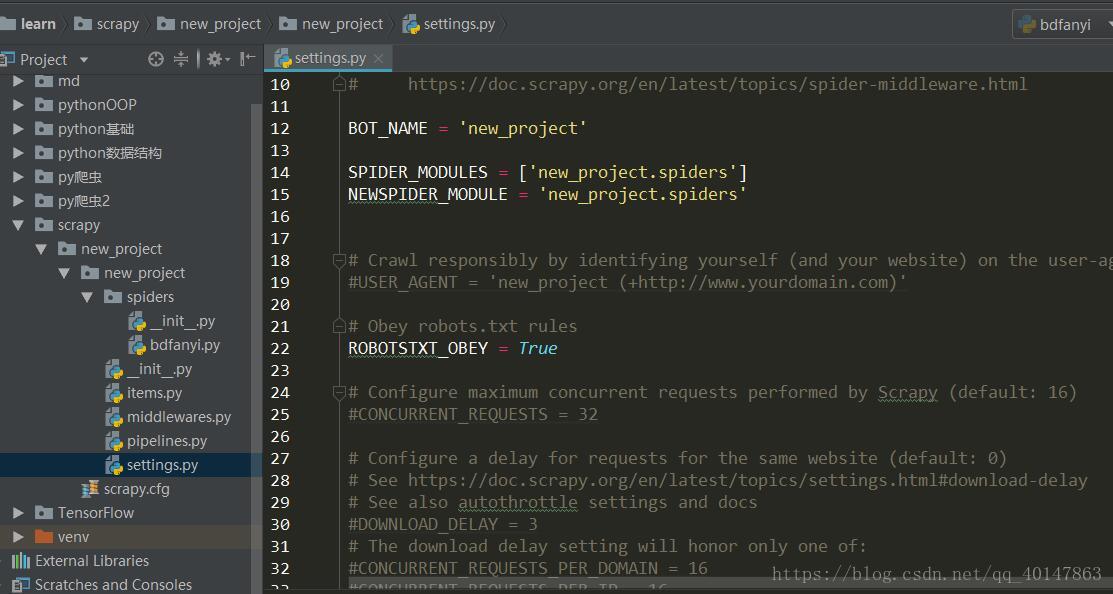

USER_AGENTS = [
"Mozilla/5.0 (compatible; MISE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.5.727; Media Center PC 6.0)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60 ",
"Opera/8.0 (Windows NT 5.1; U; en) ",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50 ",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400) ",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
]
- 直接将这段代码拷贝到 Settings 文件中就可以
Settings 中配置 PROXIES
- 关于 proxy 代理 IP 的详细介绍,查看:Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
- 获取代理IP 的网站:
- www.goubanjia.com
- www.xicidaili.com
- 从网站上找可用的 IP,直接拷贝就行,然后在Settings 中拷贝下面这段代码:
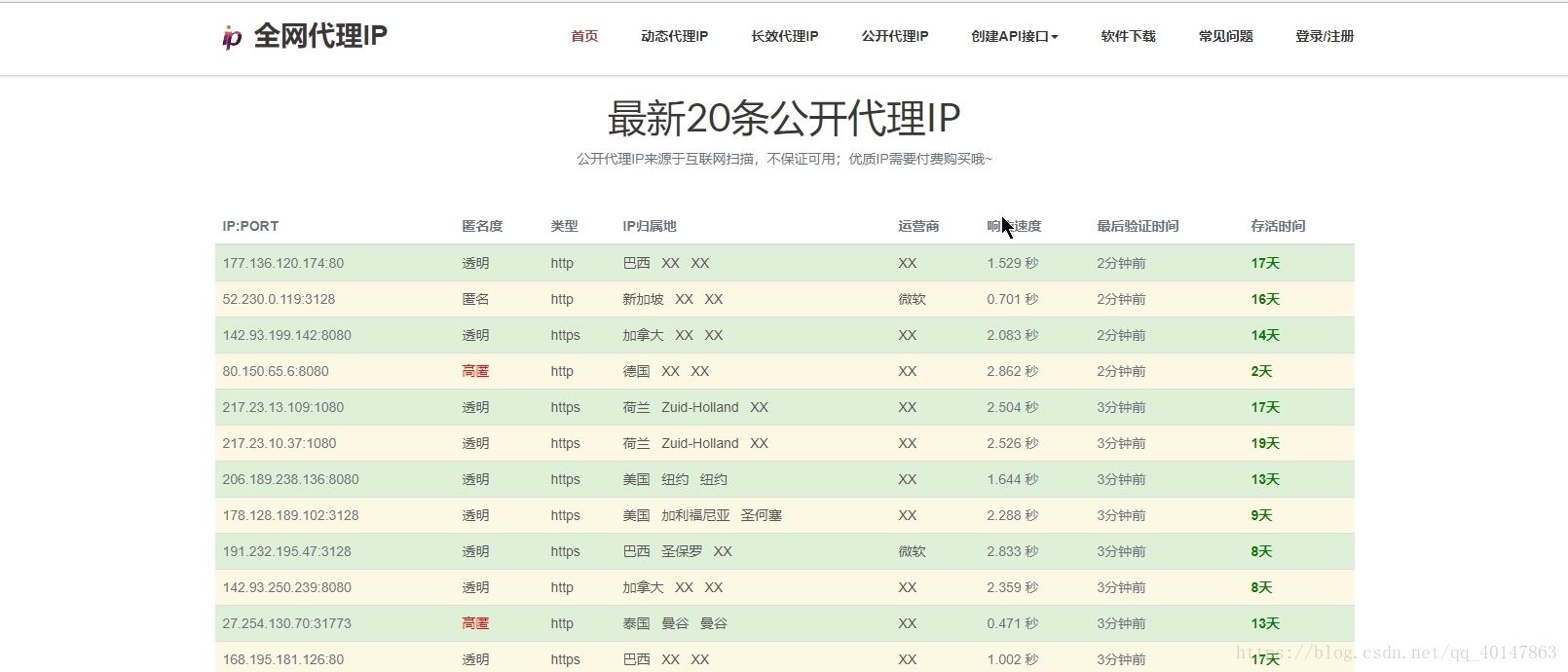
# IP 有效期一般20天,请自行到上述网站获取最新 IP
PROXIES = [
{'ip_port': '177.136.120.174:80', 'user_passwd': 'user1:pass1'},
{'ip_port': '218.60.8.99:3129', 'user_passwd': 'user2:pass2'},
{'ip_port': '206.189.204.62:8080', 'user_passwd': 'user3:pass3'},
{'ip_port': '125.62.26.197:3128', 'user_passwd': 'user4:pass4'}
]
- 这些类似的设置都是一次设置,就可以重复使用了
关于去重
- 很多网站都是相同的内容,比如介绍 python 爬虫的,很多很多,假设爬取到这些的时候,我们就值需要一个,利用 scrapy 的去重功能,防止它对重复网站无限制爬下去
- 为了防止爬虫陷入死循环,需要去重
- 即在 spider 中 parse 函数中,返回 Request 的时候加上 dont_filter = False 参数
myspider(scrapy.Spider):
def parse (...):
...
yield scrapy.Request(url = url, callback = self.parse, dont_filter = False)
- 如何在 scrapy 使用 selenium
- 可以放入中间件中的 process _request 函数中
- 在函数中调用 selenium,完成爬取后返回 Response
class MyMiddleWare(object):
def process_request(...):
driver = webdriver.Chrome()
html = driver.page_source
driver.quit()
return HtmlResponse(url = request.url, encoding = 'utf-8', body = html ,request = requeset
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍的更多相关文章
- iOS 9应用开发教程之创建iOS 9项目与模拟器介绍
iOS 9应用开发教程之创建iOS 9项目与模拟器介绍 编写第一个iOS 9应用 本节将以一个iOS 9应用程序为例,为开发者讲解如何使用Xcode 7.0去创建项目,以及iOS模拟器的一些功能.编辑 ...
- Python爬虫教程-新浪微博分布式爬虫分享
爬虫功能: 此项目实现将单机的新浪微博爬虫重构成分布式爬虫. Master机只管任务调度,不管爬数据:Slaver机只管将Request抛给Master机,需要Request的时候再从Master机拿 ...
- Django框架中settings.py注释
1 # coding:utf8 2 """ 3 Django settings for DjangoTest project. 4 5 Generated by 'dja ...
- django项目settings.py的基础配置
一个新的django项目初始需要配置settings.py文件: 1. 项目路径配置 新建一个apps文件夹,把所有的项目都放在apps文件夹下,比如apps下有一个message项目,如果不进行此项 ...
- 大爽Python入门教程 3-2 条件判断: if...elif..else
大爽Python入门公开课教案 点击查看教程总目录 简单回顾if 回顾下第一章的代码 >>> x = 5 >>> if x > 0: ... print(&q ...
- python基础教程2第20章 项目1:即时标记
simple_markup.py import sys, re from util import * print('<html><head><title>...&l ...
- Python基础教程(016)--Python2和Python3的介绍
前言 Python2和Python3的区别 内容 Python3是现在和未来的主要版本 Python3没有考虑向下兼容. 官方提供了一个Python过度版本Python2.6 Python2.6及支持 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
随机推荐
- 洛谷 P3201 [HNOI2009]梦幻布丁(启发式合并)
题面 luogu 题解 什么是启发式合并? 小的合并到大的上面 复杂度\(O(nlogn)\) 这题颜色的修改,即是两个序列的合并 考虑记录每个序列的\(size\) 小的合并到大的 存序列用链表 但 ...
- 解决php -v查看到版本于phpinfo()打印的版本不一致问题
https://blog.csdn.net/haif_city/article/details/81315372 整个事件的起因是这样的 通过git拉取laraevl项目发现缺少.env文件,打算使用 ...
- centos 7 设置开机启动服务
2018-12-25 Centos7下添加开机自启动脚本和服务的方法 以docker 服务为例 1.centos7自带命令设置 systemctl enable docker.service 2.设置 ...
- helloweblogic 官方qq群欢迎加入!
点击加入helloweblogic 官方qq群,大家一起进行中间件技术交流,问题交流,互相帮忙互相学习. 我的网易博客地址:http://fm928.blog.163.com 收到网易博客的邮件,以后 ...
- 如何获取select中的value、text、index相关值 && 如何获取单选框中radio值 && 触发事件 && radio 默认选中
如何获取select中的value.text.index相关值 select还是比较常用的一个标签,如何获取其中的内容呢? 如下所示: <select id="select" ...
- 自适应网页设计(Responsive Web Design)别名(响应式web设计)转载阮一峰
随着3G的普及,越来越多的人使用手机上网. 移动设备正超过桌面设备,成为访问互联网的最常见终端.于是,网页设计师不得不面对一个难题:如何才能在不同大小的设备上呈现同样的网页? 手机的屏幕比较小,宽度通 ...
- Git学习系列之集中式版本控制系统vs分布式版本控制系统
不多说,直接上干货! Linus一直痛恨的CVS及SVN都是集中式的版本控制系统,而Git是分布式版本控制系统,集中式和分布式版本控制系统有什么区别呢? 先说集中式版本控制系统,版本库是集中存放在中央 ...
- HTTP 状态代码之汇总+理解
这里有百度百科的介绍,还挺全的. 下面是在开发过程中遇到过的各种码,自己的问题自己的原因,同码不同错,贱笑贱笑. HTTP 406 Not Acceptable 这个错误的原因,是由于框架使用了`Sp ...
- 记一次走心One 2 One沟通
聊的比较零零碎碎,内容比较散,有些solution不错,记一些要点吧(1)要学会汇报,就是坐你身边的人,也未必知道你在干啥 三个人都在砌墙.当人们分别问他们在做什么,他们的答案却不一样:第一个人头也没 ...
- MdiContainer
/// <summary> /// 显示form /// </summary> /// <param name="form">要显示的form& ...