LinkedList的源码分析(基于jdk1.8)
1.初始化
public LinkedList() {
}
并未开辟任何类似于数组一样的存储空间,那么链表是如何存储元素的呢?
2.Node类型
存储到链表中的元素会被封装为一个Node类型的结点。并且链表只需记录第一个结点的位置和最后一个结点的位置。然后每一个结点,前后连接,就可以串起来变成一整个链表。
transient Node<E> first;//指向链表的第一个结点 transient Node<E> last;//指向链表的最后一个结点
//LinkedList中有一个内部类Node类型
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev; Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}

3.添加元素
public boolean add(E e) {
//默认链接到链表末尾
linkLast(e);
return true;
}
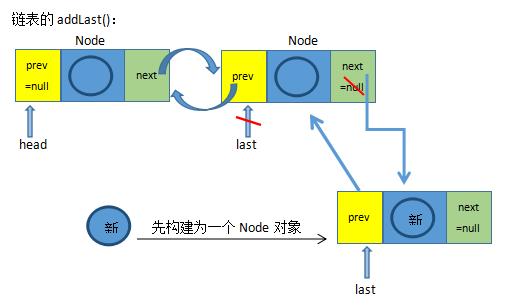
void linkLast(E e) {
//用l记录当前链表的最后一个结点对象
final Node<E> l = last;
//创建一个新结点对象,并且指定当前新结点的前一个结点为l
final Node<E> newNode = new Node<>(l, e, null);
//当前新结点就变成了链表的最后一个结点
last = newNode;
if (l == null)
//如果当前链表是空的,那么新结点对象,同时也是链表的第一个结点
first = newNode;
else
//如果当前链表不是空的,那么最后一个结点的next就指向当前新结点
l.next = newNode;
//元素个数增加
size++;
//修改次数增加
modCount++;
}
4.删除元素
public boolean remove(Object o) {
//分o是否是null讨论,从头到尾找到要删除的元素o对应的Node结点对象,然后删除
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
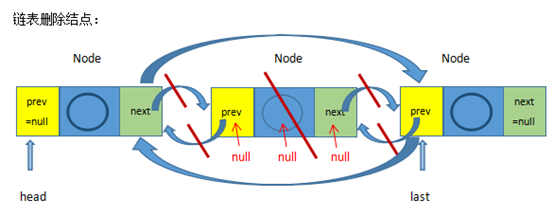
E unlink(Node<E> x) {
final E element = x.item;
//用next记录被删除结点的后一个结点
final Node<E> next = x.next;
//用prev记录被删除结点的前一个结点
final Node<E> prev = x.prev;
if (prev == null) {
//如果删除的是第一个结点,那么被删除的结点的后一个结点将成为第一个结点
first = next;
} else {
//否则被删除结点的前一个结点的next应该指向被删除结点的后一个结点
prev.next = next;
//断开被删除结点与前一个结点的关系
x.prev = null;
}
if (next == null) {
//如果删除的是最后一个结点,那么被删除结点的前一个结点将变成最后一个结点
last = prev;
} else {
//否则被删除结点的后一个结点的prev应该指向被删除结点的额前一个结点
next.prev = prev;
//断开被删除结点与后一个结点的关系
x.next = null;
}
//彻底把被删除结点变成垃圾对象
x.item = null;
//元素个数减少
size--;
//修改次数增加
modCount++;
return element;
}
5.指定位置插入元素
public void add(int index, E element) {
//检查索引位置的合理性
checkPositionIndex(index);
if (index == size)
//如果位置是在最后,那么链接到链表的最后
linkLast(element);
else
//否则在链表中间插入
//node(index)表示找到index位置的Node对象
linkBefore(element, node(index));
}
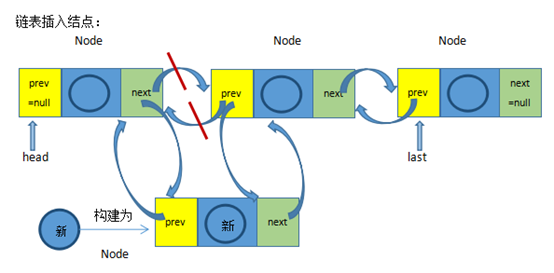
void linkBefore(E e, Node<E> succ) {
// pred记录被插入位置的前一个结点
final Node<E> pred = succ.prev;
//构建一个新结点
final Node<E> newNode = new Node<>(pred, e, succ);
//把新结点插入到succ的前面
succ.prev = newNode;
//如果被插入点是链表的开头,那么新结点变成了链表头
if (pred == null)
first = newNode;
else
//否则pred的next就变成了新结点
pred.next = newNode;
//元素个数增加
size++;
//修改次数增加
modCount++;
}
6.总结
对于频繁的插入或删除元素的操作,建议使用LinkedList类,效率较高。因为不涉及到移动元素,只需要修改前后结点的关系。也不需要涉及到扩容
此类虽然提供按照索引查找与操作的方法,但是效率不高,如果需要按索引操作,那么建议使用动态数组
LinkedList的源码分析(基于jdk1.8)的更多相关文章
- HashMap 源码分析 基于jdk1.8分析
HashMap 源码分析 基于jdk1.8分析 1:数据结构: transient Node<K,V>[] table; //这里维护了一个 Node的数组结构: 下面看看Node的数 ...
- CopyOnWriteArrayList 源码分析 基于jdk1.8
CopyOnWriteArrayList 源码分析: 1:成员属性: final transient ReentrantLock lock = new ReentrantLock(); //内部是 ...
- HashMap源码分析-基于JDK1.8
hashMap数据结构 类注释 HashMap的几个重要的字段 hash和tableSizeFor方法 HashMap的数据结构 由上图可知,HashMap的基本数据结构是数组和单向链表或红黑树. 以 ...
- ArrayList 源码分析 基于jdk1.8:
1:数据结构: transient Object[] elementData; //说明内部维护的数据结构是一个Object[] 数组 成员属性: private static final int ...
- ArrayList的源码分析(基于jdk1.8)
1.初始化 transient Object[] elementData; //实际存储元素的数组 private static final Object[] DEFAULTCAPACITY_EMPT ...
- AtomicInteger源码分析——基于CAS的乐观锁实现
AtomicInteger源码分析——基于CAS的乐观锁实现 1. 悲观锁与乐观锁 我们都知道,cpu是时分复用的,也就是把cpu的时间片,分配给不同的thread/process轮流执行,时间片与时 ...
- LinkedList 的源码分析
LinkedList是基于双向链表数据结构来存储数据的,以下是对LinkedList 的 属性,构造器 ,add(E e),remove(index),get(Index),set(inde,e)进 ...
- 并发-AtomicInteger源码分析—基于CAS的乐观锁实现
AtomicInteger源码分析—基于CAS的乐观锁实现 参考: http://www.importnew.com/22078.html https://www.cnblogs.com/mantu/ ...
- Spring IoC 源码分析 (基于注解) 之 包扫描
在上篇文章Spring IoC 源码分析 (基于注解) 一我们分析到,我们通过AnnotationConfigApplicationContext类传入一个包路径启动Spring之后,会首先初始化包扫 ...
随机推荐
- 关于windows server 里Let's Encrypt续订的问题
引言 Let's Encrypt是什么就不详细说了,它是免费的https证书,优点就是免费,缺点就是每三个月就要自己续上.今天主要介绍的是续上有效期的环节. 1.安装certify 下载地址: htt ...
- C#中的多线程 - 高级多线程 z
原文:http://www.albahari.com/threading/part4.aspx 专题:C#中的多线程 1非阻塞同步Permalink 之前,我们描述了即使是很简单的赋值或更新一个字段也 ...
- shell单引号双引号详解
linux shell中的单引号与双引号的区别(看完就不会有引号的疑问了) " "(双引号)与 ' '(单引号)的区别 你在shell prompt(shell 提示)后面敲 ...
- MQ--API总结
研究MQ很长时间了, 每个类,方法,都查了很长时间,在此总结一下! Java编写访问MQ的程序 1.MQQueueManager―――队列管理器访问类 常用方法: public MQQueueMan ...
- Intellij IDEA 修改编辑器背景颜色
对眼睛有益的RGB数值分别是(199,237,204)
- 通俗易懂的来讲讲DOM——科普性质的DOM入门教程
DOM这个东西很重要,不过初学的时候很容易蒙,什么Document.Element.Node用官方语言来解释根本就不是人话,只能在实践中硬着头皮一点一点尝试.今天要推荐的是一篇关于DOM的博客.说是教 ...
- UIView的多重属性
1)几何属性: 2)位图属性:
- Yii: 扩展CGridView增加导出CSV功能
Yii提供的CGridView组件没有内置数据导出功能,不过我们可以通过扩展该组件来添加该功能. 具体方法如下: 1.首先派生一个子类,添加一个action成员,在该视图的init函数中判断是浏览动作 ...
- PAT——1012. 数字分类
给定一系列正整数,请按要求对数字进行分类,并输出以下5个数字: A1 = 能被5整除的数字中所有偶数的和: A2 = 将被5除后余1的数字按给出顺序进行交错求和,即计算n1-n2+n3-n4...: ...
- asp.net mvc5 step by step(一)——CURD增删查改Demo
1. 新建一个项目: