python进行机器学习(一)之数据预处理
一、加载数据
houseprice=pd.read_csv('../input/train.csv') #加载后放入dataframe里
all_data=pd.read_csv('a.csv', header=0,parse_dates=['time'],usecols=['time','LotArea','price']) #可以选择加载哪几列 houseprice.head() #显示前5行数据 houseprice.info() #查看各字段的信息
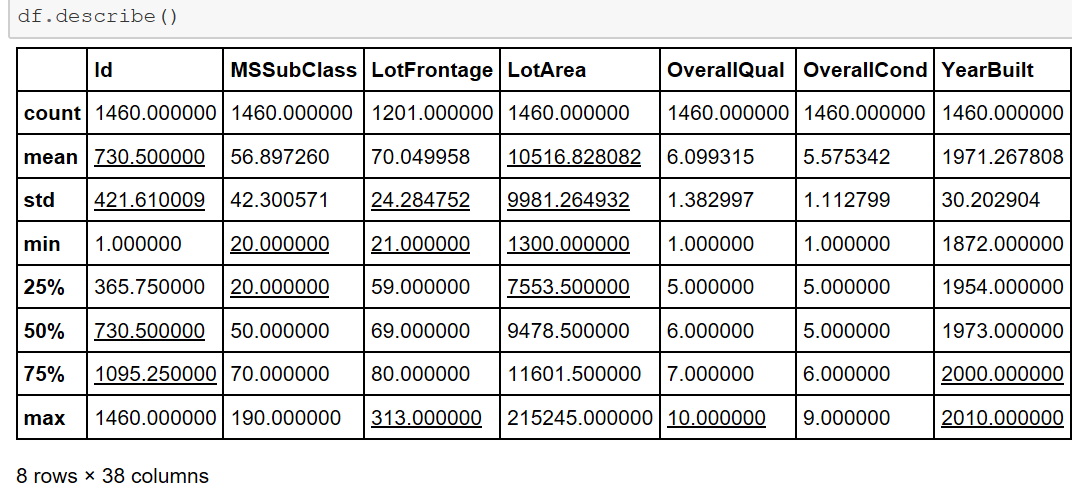
houseprice.shape #查看数据集行列分布,几行几列 houseprice.describe() #查看数据的大体情况
二、分析缺失数据
houseprice.isnull() #元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True,否则就是False
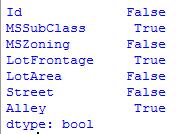
houseprice.isnull().any() #列级别的判断,只要该列有为空或者NA的元素,就为True,否则False
missing=houseprice.columns[houseprice.isnull().any()].tolist() #将为空或者NA的列找出来
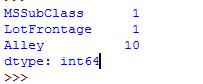
houseprice[missing].isnull().sum() #将列中为空或者NA的个数统计出来

# 将某一列中缺失元素的值,用value值进行填充。处理缺失数据时,比如该列都是字符串,不是数值,可以将出现次数最多的字符串填充缺失值。
def cat_imputation(column, value):
houseprice.loc[houseprice[column].isnull(),column] = value
houseprice[['LotFrontage','Alley']][houseprice['Alley'].isnull()==True] #从LotFrontage 和Alley 列中进行选择行,选择Alley中数据为空的行。主要用来看两个列的关联程度,是不是大多同时为空。
houseprice['Fireplaces'][houseprice['FireplaceQu'].isnull()==True].describe() #对筛选出来的数据做一个描述,比如一共多少行,均值、方差、最小值、最大值等等。
三、统计分析
houseprice['MSSubClass'].value_counts() #统计某一列中各个元素值出现的次数
print("Skewness: %f" % houseprice['MSSubClass'].skew()) #列出数据的偏斜度
print("Kurtosis: %f" % houseprice['MSSubClass'].kurt()) #列出数据的峰度
houseprice['LotFrontage'].corr(houseprice['LotArea']) #计算两个列的相关度
houseprice['SqrtLotArea']=np.sqrt(houseprice['LotArea']) #将列的数值求根,并赋予一个新列 houseprice[['MSSubClass', 'LotFrontage']].groupby(['MSSubClass'], as_index=False).mean() #跟MSSubClass进行分组,并求分组后的平均值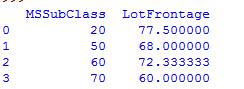
四、数据处理
1)删除相关 del houseprice['SqrtLotArea'] #删除列
houseprice['LotFrontage'].dropna() #去掉为空值或者NA的元素 houseprice.drop(['Alley'],axis=1) #去掉Alley列,不管空值与否 df.drop(df.columns[[0,1]],axis=1,inplace=True) #删除第1,2列,inplace=True表示直接就在内存中替换了,不用二次赋值生效。
houseprice.dropna(axis=0) #删除带有空值的行
houseprice.dropna(axis=1) #删除带有空值的列 2)缺失值填充处理
houseprice['LotFrontage']=houseprice['LotFrontage'].fillna(0) #将该列中的空值或者NA填充为0
all_data.product_type[all_data.product_type.isnull()]=all_data.product_type.dropna().mode().values #如果该列是字符串的,就将该列中出现次数最多的字符串赋予空值,mode()函数就是取出现次数最多的元素。
houseprice['LotFrontage'].fillna(method='pad') #使用前一个数值替代空值或者NA,就是NA前面最近的非空数值替换
houseprice['LotFrontage'].fillna(method='bfill',limit=1) #使用后一个数值替代空值或者NA,limit=1就是限制如果几个连续的空值,只能最近的一个空值可以被填充。
houseprice['LotFrontage'].fillna(houseprice['LotFrontage'].mean()) #使用平均值进行填充
houseprice['LotFrontage'].interpolate() # 使用插值来估计NaN 如果index是数字,可以设置参数method='value' ,如果是时间,可以设置method='time'
houseprice= houseprice.fillna(houseprice.mean()) #将缺失值全部用该列的平均值代替,这个时候一般已经提前将字符串特征转换成了数值。
注:在kaggle中有人这样处理缺失数据,如果数据的缺失达到15%,且并没有发现该变量有多大作用,就删除该变量! 3)字符串替换
houseprice['MSZoning']=houseprice['MSZoning'].map({'RL':1,'RM':2,'RR':3,}).astype(int) #将MSZoning中的字符串变成对应的数字表示
4)数据连接
merge_data=pd.concat([new_train,df_test]) #讲训练数据与测试数据连接起来,以便一起进行数据清洗
all_data = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'], test.loc[:,'MSSubClass':'SaleCondition'])) #另一种合并方式,按列名字进行合并。
res = pd.merge(df1, df2,on=['time']) #将df1,df2按照time字段进行合并,两个df中都含有time字段
5)数据保存
merge_data.to_csv('merge_data.csv',index=False) #index=False,写入的时候不写入列的索引序号
6)数据转换
houseprice["Alley"] = np.log1p(houseprice["Alley"]) #采用log(1+x)方式对原数据进行处理,改变原数据的偏斜度,使数据更加符合正态曲线分布。
numeric_feats =houseprice.dtypes[houseprice.dtypes != "object"].index #把内容为数值的特征列找出来
#下面几行代码将偏斜度大于0.75的数值列做一个log转换,使之尽量符合正态分布,因为很多模型的假设数据是服从正态分布的
skewed_feats = train[numeric_feats].apply(lambda x: skew(x.dropna())) #compute skewness
skewed_feats = skewed_feats[skewed_feats > 0.75]
skewed_feats = skewed_feats.index
all_data[skewed_feats] = np.log1p(all_data[skewed_feats])
houseprice= pd.get_dummies(houseprice) #另外一种形式数据转换,将字符串特征列中的内容分别提出来作为新的特征出现,这样就省去了将字符串内容转化为数值特征内容的步骤了。

6)数据标准化
我们都知道大多数的梯度方法(几乎所有的机器学习算法都基于此)对于数据的缩放很敏感。因此,在运行算法之前,我们应该进行标准化,或所谓的规格化。标准化包括替换所有特征的名义值,让它们每一个的值在0和1之间。而对于规格化,它包括数据的预处理,使得每个特征的值有0和1的离差。Scikit-Learn库已经为其提供了相应的函数。
from sklearn import preprocessing
# normalize the data attributes
normalized_X = preprocessing.normalize(X)
# standardize the data attributes
standardized_X = preprocessing.scale(X)
python进行机器学习(一)之数据预处理的更多相关文章
- 用python+sklearn(机器学习)实现天气预报数据 模型和使用
用python+sklearn机器学习实现天气预报 模型和使用 项目地址 系列教程 0.前言 1.建立模型 a.准备 引入所需要的头文件 选择模型 选择评估方法 获取数据集 b.建立模型 c.获取模型 ...
- 用python+sklearn(机器学习)实现天气预报数据 数据
用python+sklearn机器学习实现天气预报 数据 项目地址 系列教程 勘误表 0.前言 1.爬虫 a.确认要被爬取的网页网址 b.爬虫部分 c.网页内容匹配取出部分 d.写入csv文件格式化 ...
- Python初探——sklearn库中数据预处理函数fit_transform()和transform()的区别
敲<Python机器学习及实践>上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下: ...
- Python的工具包[1] -> pandas数据预处理 -> pandas 库及使用总结
pandas数据预处理 / pandas data pre-processing 目录 关于 pandas pandas 库 pandas 基本操作 pandas 计算 pandas 的 Series ...
- 机器学习实战:数据预处理之独热编码(One-Hot Encoding)
问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. 例如,考虑一下的三个特征: ["male", "female"] ["from ...
- 机器学习——Day 1 数据预处理
写在开头 由于某些原因开始了机器学习,为了更好的理解和深入的思考(记录)所以开始写博客. 学习教程来源于github的Avik-Jain的100-Days-Of-MLCode 英文版:https:// ...
- 第一章:AI人工智能 の 数据预处理编程实战 Numpy, Pandas, Matplotlib, Scikit-Learn
本课主题 数据中 Independent 变量和 Dependent 变量 Python 数据预处理的三大神器:Numpy.Pandas.Matplotlib Scikit-Learn 的机器学习实战 ...
- 用python+sklearn(机器学习)实现天气预报 准备
用python+sklearn机器学习实现天气预报 准备 项目地址 系列教程 0.流程介绍 1. 环境搭建 a.python b.涉及到的机器学习相关库 sklearn panda seaborn j ...
- python实现机器学习笔记
#课程链接 https://www.imooc.com/video/20165 一.机器学习介绍以及环境部署 1.机器学习介绍及其原理 1)什么是人工智能 人工智能就其本质而言,是机器对人的思维信息过 ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
随机推荐
- try catch finally 与continue的使用
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- java得到当前时间
SimpleDateFormat timeformat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); java.util.Date ...
- 查询MySQL某字段相同值得重复数据
1.先查询重复的id: SELECT book_id,COUNT(*) AS COUNT FROM xs_book_source WHERE site_id=5 GROUP BY book_id HA ...
- 【转】Jsp自定义标签详解
一.前言 原本是打算研究EXtremeComponents这个jsp标签插件,因为这个是自定义的标签,且自身对jsp的自定义标签并不是非常熟悉,所以就打算继续进行扫盲,开始学习并且整理Jsp自定义标签 ...
- [C/C++] C++类对象创建问题
CSomething a();// 没有创建对象,这里不是使用默认构造函数,而是定义了一个函数,在C++ Primer393页中有说明. CSomething b(2);//使用一个参数的构造函数,创 ...
- Codeforces633H-Fibonacci-ish II
题目 斐波那契数列\(f\),\(f\_1=f\_2=1,\ f\_n=f\_{n-1}+f\_{n-2}\ (n>2)\). 给定长度为\(n\ (n\le 30000)\)的数列\(a\), ...
- kaptcha验证码在windows下正常,在linux下无法显示
有几种情况,记录备忘: 1.两个环境字体不一样,linux环境下可能没有字体,重新安装字体即可. 2.tomcat等容器下没有temp目录,手动建立即可. 3.如果报找不到类的错误,检查JDK是否正确 ...
- HDOJ(HDU).3466 Dividing coins ( DP 01背包 无后效性的理解)
HDOJ(HDU).3466 Dividing coins ( DP 01背包 无后效性的理解) 题意分析 要先排序,在做01背包,否则不满足无后效性,为什么呢? 等我理解了再补上. 代码总览 #in ...
- bzoj4552: [Tjoi2016&Heoi2016]排序(二分+线段树)
又是久违的1A哇... 好喵喵的题!二分a[p],把大于mid的数改为1,小于等于mid的数改为0,变成01串后就可以用线段树进行那一连串排序了,排序后如果p的位置上的数为0,说明答案比mid小,如果 ...
- Change FZU - 2277 毒瘤啊 毒瘤题目
There is a rooted tree with n nodes, number from 1-n. Root’s number is 1.Each node has a value ai. I ...