数据挖掘-关联分析 Apriori算法和FP-growth 算法
•1.关联分析概念
关联分析是从大量数据中发现项集之间有趣的关联和相关联系。

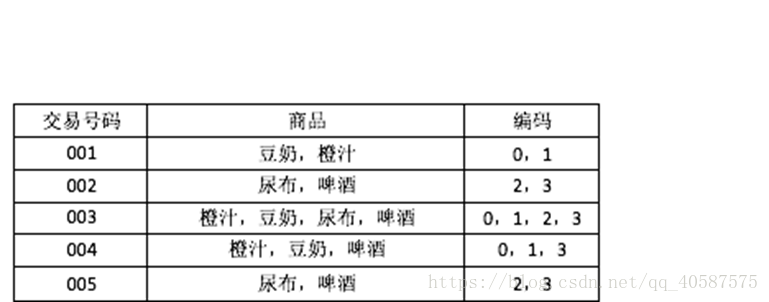
•定义:
1、事务:每一条交易称为一个事务,如上图包含5个事务。
2、项:交易的每一个物品称为一个项,例如豆奶,啤酒等。
3、项集:包含零个或多个项的集合叫做项集,例如{尿布,啤酒}。
4、k−项集:包含k个项的项集叫做k-项集,例如 {豆奶,橙汁}叫做2-项集。
5、支持度计数:一个项集出现在几个事务当中,它的支持度计数就是几。例如{尿布, 啤酒}出现在事务002、003和005中,所以 它的支持度计数是3。
6、支持度:支持度计数除于总的事务数。例如上例中总的事务数为5,{尿布, 啤酒}的支持度计数为3,所以它的支持度是 3÷5=60%,说明有60%的人同时买了尿布, 啤酒。
7、频繁项集:支持度大于或等于某个阈值的项集就叫做频繁项集。例如阈值设为50%时,因为{尿布,啤酒}的支持度是60%,所以 它是频繁项集。
8、前件和后件:对于规则{尿布}→{啤酒},{Diaper}叫做前件,{啤酒}叫做后件。
9、置信度:对于规则{尿布}→{啤酒},{尿布,啤酒}的支持度计数除于{尿布}的支持度计数,为这个规则的置信度。
例如规则{尿布}→{啤酒}的置信度为3÷3=100%。说明买了尿布的人100%也买了 啤酒。
10、强关联规则:大于或等于最小支持度阈值和最小置信度阈值的规则叫做强关联规则。
•频繁项集(frequent item sets)是经常出现在一块儿的物品的集合.
•关联规则(association rules)暗示两种物品之间可能存在很强的关系。
•1)支持度
•Surpport(A->B)= P(AB) ,支持度表示事件A 和事件B 同时出现的概率。
•2)置信度
•Confidence(A->B) = P(B/A) = P(AB)/ P(A) ,置信度表示 A 事件出现时,B 事件出现的概率。
•关联分析的最终目标就是要找出强关联规则。
•2.Apriori算法原理
•Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。算法的名字基于这样的事实:算法使用频繁项集性质的先验知识,正如我们将看到的。Apriori使用一种称作逐层搜索的迭代方法,k-项集用于探索(k+1)-项集。首先,找出频繁1-项集的集合。该集合记作L1。L1 用于找频繁2-项集的集合L2,而L2 用于找L3,如此下去,直到不能找到频繁k-项集。找每个Lk需要一次数据库扫描。
先验定理:如果一个项集是频繁的,则它的所有子集一定也是频繁的。
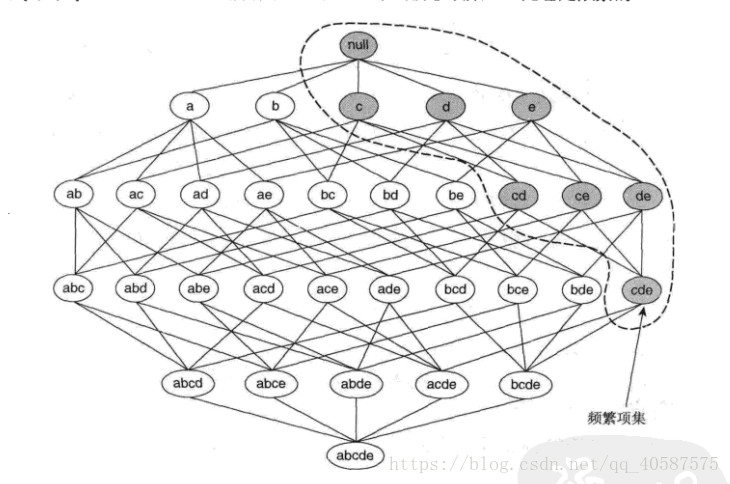
如图所示,假定{c,d,e}是频繁项集。显而易见,任何包含项集{c,d,e}的事务一定包含它的子集{c,d},{c,e},{d,e},{c},{d}和{e}。这样,如果{c,d,e}是频繁的,则它的所有子集一定也是频繁的。
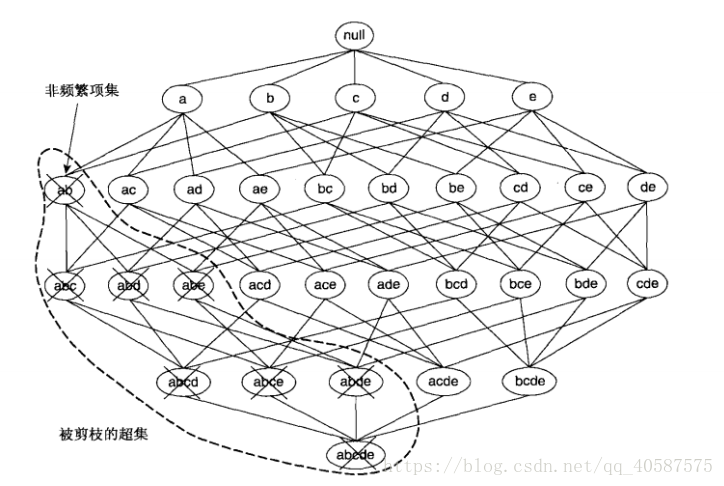
如果项集{a,b}是非频繁的,则它的所有超集也一定是非频繁的。即一旦发现{a,b}是非频繁的,则整个包含{a,b}超集的子图可以被立即剪枝。这种基于支持度度量修剪指数搜索空间的策略称为基于支持度的剪枝。
这种剪枝策略依赖于支持度度量的一个关键性质,即一个项集的支持度绝不会超过它的子集的支持度。这个性质也称支持度度量的反单调性。

Apriori算法
优点:易编码实现。’
缺点:在大数据集上可能较慢。
适用数据类型:数值型或者标称型数据。
3.算法实现:
#coding=gbk
# apriori算法的实现
def load_dataset(): #定义数据集
return [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]
def create_C1(dataSet): #得到数据集中的每个数据,且进行排序
C1 =[]
for transantion in dataSet:
for item in transantion:
if not [item] in C1:
C1.append([item]) #储存 I1, I2,。。需要使其不重复
C1.sort()
#use frozen set so we can use it as a key in a dict
#应该输出 1,2,3,4,5
return list(map(frozenset, C1)) # 将C1中的每个集合映射为frozenset,之后可以作为字典的键,
dataSet = load_dataset()
ck = create_C1(dataSet)
print(ck) # 输出:[frozenset({1}), frozenset({2}), frozenset({3}), frozenset({4}), frozenset({5})]
#测试代码
# # map(function, sequence)
# c2 = [[2,4],[5,8],[3]]
# c2.sort()
# a = list(map(frozenset, c2))
# print(a) #[frozenset({2, 4}), frozenset({3}), frozenset({8, 5})]
# print(a[0]) # frozenset({2, 4})
# Apriori算法首先构建集合 C1 ,然后扫描数据集判断这些只有一个元素的项集是否满足最小支持度的要求。那些满足最低要求的项集构成集合 L1 。
# 而 L1 中的元素相互组合构成 C2 , C2 再进一步过滤变为 L2 。
#该函数使 C1 生成L1,ck为全部的数据项
def scanD(D, Ck, minSupport): #参数D 为数据集, Ck为候选项列表, 最小支持度
ssCnt= {} #存储数据项1,2,。。及其出现的次数
for tid in D: #遍历数据集
for can in Ck: #遍历候选项 1,2,3,4,5,
if can.issubset(tid): #判断候选项是否含数据集中的各项
if not can in ssCnt:
ssCnt[can] =1
else:
ssCnt[can]+=1 #有则进行加一操作, 1,2,3,4,5 的数据项的个数, 为了计算支持度
numItems = float(len(D)) #计算数据集大小
retList = [] #使L1 初始化, 保存大于最小支持度的数据项
supportData = {} #使用字典记录支持度
for key in ssCnt:
support = ssCnt[key]/ numItems #求得支持度
if support >= minSupport: #如果支持度大于用户给的最小支持度, 对小于的数据项进行去除。
retList.insert(0, key) #保存到列表中
else:
supportData[key]= support #输出去除项的支持度
return retList, supportData
#测试:
r, s = scanD(dataSet, ck, 0.5)
print(r) #[frozenset({1}), frozenset({3}), frozenset({2}), frozenset({5})]
print(s) #{frozenset({4}): 0.25}
数据集为:总共有4 分
| 1, 3, 4 |
| 2, 3, 5 |
| 1, 2, 3, 5 |
| 2, 5 |
| C1 | 出现次数 |
| 1) | 2 |
| 2) | 3 |
| 3) | 3 |
| 4) | 1 |
| 5) | 3 |
4)的支持度为 1/4 为 0.25 < 0.5 = minSupport ,所以将其舍去
整个Apriori算法的伪代码如下:
当集合中项的个数大于0时:
构建一个k个项组成的候选项集的列表
检查数据以确认每个项集都是频繁的
保留频繁项集并构建k+1项组成的候选项集的列表(向上合并)
#Apriori 算法实现
# 输入参数为 频繁项集列表 Lk 与 项集元素个数 k , 输出为 Ck
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk): #两两组合遍历 (1,2,3,5)
L1 = list(Lk[i])[:k-2]
L2 = list(Lk[j])[:k-2] #用列表储存 k-2 项的项集
L1.sort(); L2.sort()
if L1 == L2:
retList.append(Lk[i] | Lk[j]) #若2个集合的前 k-2 个项相同时, 则将两个集合合并
return retList
def apriori(dataSet, minSupport =0.5):
C1 = create_C1(dataSet)
D = list(map(set, dataSet))
L1, supportData = scanD(D, C1, minSupport) #生成L1
L =[L1]
k =2
while (len(L[k-2]) > 0): #创建 包含更多的项集的列表, 直到下一个项集为空 ,终止循环。
Ck = aprioriGen(L[k-2], k)
Lk, supk = scanD(D, Ck, minSupport) #再次在数据库上扫描一遍
supportData.update(supk)
L.append(Lk) #在1 -项集上增加 2-项集
k +=1
return L, supportData
a= [1,2,3]
a.append([[12],[13],[16]])
print(a) #[1, 2, 3, [[12], [13], [16]]]
#apriori 测试
print('------apriori test -------')
dataSet = load_dataset()
L, supportData = apriori(dataSet)
print(L)#[[frozenset({1}), frozenset({3}), frozenset({2}), frozenset({5})], [frozenset({3, 5}), frozenset({1, 3}),
# frozenset({2, 5}), frozenset({2, 3})], [frozenset({2, 3, 5})], []]
print(L[0]) # [frozenset({1}), frozenset({3}), frozenset({2}), frozenset({5})]
print(L[1]) # [frozenset({3, 5}), frozenset({1, 3}), frozenset({2, 5}), frozenset({2, 3})]
print(L[2]) #[frozenset({2, 3, 5})]
print(L[3]) # [] 频繁项集为空, 所以的出频繁项集 为{2,3,5}
#查看全部项集的支持度
print(supportData) # 部分输出:{frozenset({5}): 0.75, frozenset({3}): 0.75, frozenset({2, 3, 5}): 0.5,
函数 aprioriGen() 的输入参数为频繁项集列表 Lk 与项集元素个数 k ,输出为 Ck 。举例来说,该函数以{0}、{1}、{2}作为输入,会生成{0,1}、{0,2}以及{1,2}。要完成这一点,首先创建一个空列表,然后计算 Lk 中的元素数目。通过循环来比较 Lk 中的每一个元素与其他元素,紧接着,取列表中的两个集合进行比较。如果这两个集合的前面 k-2 个元素都相等,那么就将这两个集合合成一个大小为 k 的集合 。这里使用集合的并操作来完成。
apriori函数首先创建 C1 然后读入数据集将其转化为 D (集合列表)来完
成。程序中使用 map 函数将 set() 映射到 dataSet 列表中的每一项。scanD() 函数来创建 L1 ,并将 L1 放入列表 L 中。 L 会包含 L1 、 L2 、 L3 …。现在有了 L1 ,后面会继续找 L2 , L3 …,这可以通过 while 循环来完成,它创建包含更大项集的更大列表,直到下一个大的项集为空。Lk 列表被添加到 L ,同时增加 k 的值,增大项集个数,重复上述过程。最后,当 Lk 为空时,程序返回 L 并退出。
从频繁项中挖掘关联规则
#从频繁项集中挖掘关联规则
#产生关联规则
#参数为 L 为频繁项集, supportData 为全部项集的支持度, mincof 设置最小的置信度为 0.7
def generateRules(L, supportData, minconf = 0.7):
bigRuleList = [] #存储所有的关联规则
for i in range(1,len(L)): #只获取2 个或更多项集
for freqSet in L[i]:
#遍历L 中每一个频繁项集,对每个项集创建值包含单个元素的 列表
H1 = [frozenset([item]) for item in freqSet]
#如果频繁项集数目超过2 个, 就对其进行进一步的合并
if (i>1 ):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minconf)
else:
#第一层时, 后件数为1
calcConf(freqSet, H1, supportData, bigRuleList, minconf)
return bigRuleList
#生成候选规则集合: 计算规则的置信度,以及找到满足最小置信度的规则
def calcConf(freqSet, H1, supportData, brl, minconf=0.7):
#针对项集只有2 个元素时, 计算置信度
prunedH = [] #返回一个满足最小置信度的规则列表
for conseq in H1: #遍历H 中的所有项集, 并计算它们的置信度
conf = supportData[freqSet] / supportData[freqSet-conseq] #计算置信度
if conf >= minconf: ##满足最小置信度要求, 则打印
print(freqSet-conseq, '-->', conseq,'conf:', conf)
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
#进行合并
def rulesFromConseq(freqSet, H1, supportData, brl, minconf = 0.7):
#参数:freqSet是频繁项, H 是可以出现在规则右边的列表
m = len(H1[0])
if (len(freqSet) > (m+1)): #如果 频繁项集元素数目大于单个集合的元素数
Hmp1 = aprioriGen(H1, m+1) # 合并具有相同部分的集合
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minconf) #计算置信度
if (len(Hmp1) > 1):
#使用递归进一步组合
rulesFromConseq(freqSet, Hmp1, supportData, brl, minconf)
#测试关联规则输出
print()
print('-------generateRules test-------')
rules = generateRules(L, supportData, minconf=0.5)
print(rules)
# -------generateRules test-------
# frozenset({5}) --> frozenset({3}) conf: 0.6666666666666666
# frozenset({3}) --> frozenset({5}) conf: 0.6666666666666666
# frozenset({3}) --> frozenset({1}) conf: 0.6666666666666666
# frozenset({1}) --> frozenset({3}) conf: 1.0
# frozenset({5}) --> frozenset({2}) conf: 1.0
# frozenset({2}) --> frozenset({5}) conf: 1.0
# frozenset({3}) --> frozenset({2}) conf: 0.6666666666666666
# frozenset({2}) --> frozenset({3}) conf: 0.6666666666666666
# frozenset({5}) --> frozenset({2, 3}) conf: 0.6666666666666666
# frozenset({3}) --> frozenset({2, 5}) conf: 0.6666666666666666
# frozenset({2}) --> frozenset({3, 5}) conf: 0.6666666666666666
# [(frozenset({5}), frozenset({3}), 0.6666666666666666),。。。。。。。
4.FP-growth 算法原理:
相比于apriori 算法, FP-growth 算法可高效发现 频繁项集 。
参考:https://blog.csdn.net/zhazhayaonuli/article/details/53322541
https://www.cnblogs.com/qwertWZ/p/4510857.html
数据挖掘-关联分析 Apriori算法和FP-growth 算法的更多相关文章
- 关联分析Apriori算法和FP-growth算法初探
1. 关联分析是什么? Apriori和FP-growth算法是一种关联算法,属于无监督算法的一种,它们可以自动从数据中挖掘出潜在的关联关系.例如经典的啤酒与尿布的故事.下面我们用一个例子来切入本文对 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- WordCount作业提交到FileInputFormat类中split切分算法和host选择算法过程源码分析
参考 FileInputFormat类中split切分算法和host选择算法介绍 以及 Hadoop2.6.0的FileInputFormat的任务切分原理分析(即如何控制FileInputForm ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
随机推荐
- javascript测试框架 Mocha 实例教程
http://www.ruanyifeng.com/blog/2015/12/a-mocha-tutorial-of-examples.html
- ASP------<iframe>标签如何去掉滚动条
代码: <iframe src="../Home/Thanks" width="100%" height="500" scrollin ...
- 超全面的JavaWeb笔记day22<文件上传>
文件上传概述 1 文件上传的作用 例如网络硬盘!就是用来上传下载文件的. 在智联招聘上填写一个完整的简历还需要上传照片呢. 2 文件上传对页面的要求 上传文件的要求比较多,需要记一下: 1. 必须使用 ...
- Ext3.4-EXT之嵌套表格的实现
其中使用到的"RowExpander.js"为extjs官方示例中自带的. 实现这个嵌套表格要注意两点技巧: 1 提供给外层表格的dataStore的数据源以嵌套数组的形式表示细节 ...
- 硬件日志:/var/log/dmesg
在 Linux 系统启动时,会在屏幕上显示许多与硬件有关的信息,这些信息记录在 /var/log/dmesg 文件中,也可以用 dmesg 命令来查看 [root@localhost]# head / ...
- STM32的操作过程,寄存器配置与调试过程(转载)
很多学习stm32的,为什么学习stm32他也不知道,我们所知道的就是各个论坛讨论stm32的很多,而我们很多人之所以学习stm32是很多的淘宝卖家做了大量的图片文字宣传,于是我们经不住诱惑就买了板子 ...
- lua垃圾回收机制
一.检测lua内存泄漏: 注:使用“collectgarbage("collect")”,局部变量v被回收,my_list没有被回收. 注:局部变量v占用的内存被回收. 注:将my ...
- 使用vim-pathogen 进行插件管理
使用vim的插件管理器 pathogen进行vim的插件管理. 1. pathogen 管理插件 pathogen让每个插件占有一个单独的目录,解决了文件分散的问题.安装完 pathogen之后,只需 ...
- JS-提取字符串—>>普通方法VS正则表达式
如下:“23nr qreq2 34fq4 4454gsr 45” [将这一串字符中的数字挑出来,当然人家作伴的不能被分开]. 一.普通方法: <script type="text/ja ...
- linux下一些常用命令和访问目录
1. 目录 ls 列出目录文件名 ll 列出所有目录文件的访问权限等相关信息,包括 . .. ls -a 列出所有目录文件名,包括 . .. ls - ...