【Spark篇】---SparkSQL on Hive的配置和使用
一、前述
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
二、具体配置
1、在Spark客户端配置Hive On Spark
在Spark客户端安装包下spark-1.6.0/conf中创建文件hive-site.xml:
配置hive的metastore路径
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>
2、启动Hive的metastore服务
hive --service metastore
3、启动zookeeper集群,启动HDFS集群。
4、启动SparkShell 读取Hive中的表总数,对比hive中查询同一表查询总数测试时间。
./spark-shell
--master spark://node1:7077,node2:7077
--executor-cores 1
--executor-memory 1g
--total-executor-cores 1
import org.apache.spark.sql.hive.HiveContext
val hc = new HiveContext(sc)
hc.sql("show databases").show
hc.sql("user default").show
hc.sql("select count(*) from jizhan").show
可以发现性能明显提升!!!
注意:
如果使用Spark on Hive 查询数据时,出现错误:

找不到HDFS集群路径,要在客户端机器conf/spark-env.sh中设置HDFS的路径:
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
三、读取Hive中的数据加载成DataFrame
1、HiveContext是SQLContext的子类,连接Hive建议使用HiveContext。
2、由于本地没有Hive环境,要提交到集群运行,提交命令:
/spark-submit
--master spark://node1:7077,node2:7077
--executor-cores 1
--executor-memory 2G
--total-executor-cores 1
--class com.bjsxt.sparksql.dataframe.CreateDFFromHive
/root/test/HiveTest.jar
java代码:
SparkConf conf = new SparkConf();
conf.setAppName("hive");
JavaSparkContext sc = new JavaSparkContext(conf);
//HiveContext是SQLContext的子类。
HiveContext hiveContext = new HiveContext(sc);
hiveContext.sql("USE spark");
hiveContext.sql("DROP TABLE IF EXISTS student_infos");
//在hive中创建student_infos表
hiveContext.sql("CREATE TABLE IF NOT EXISTS student_infos (name STRING,age INT) row format delimited fields terminated by '\t' ");
hiveContext.sql("load data local inpath '/root/test/student_infos' into table student_infos"); hiveContext.sql("DROP TABLE IF EXISTS student_scores");
hiveContext.sql("CREATE TABLE IF NOT EXISTS student_scores (name STRING, score INT) row format delimited fields terminated by '\t'");
hiveContext.sql("LOAD DATA "
+ "LOCAL INPATH '/root/test/student_scores'"
+ "INTO TABLE student_scores");
/**
* 查询表生成DataFrame
*/
DataFrame goodStudentsDF = hiveContext.sql("SELECT si.name, si.age, ss.score "
+ "FROM student_infos si "
+ "JOIN student_scores ss "
+ "ON si.name=ss.name "
+ "WHERE ss.score>=80"); hiveContext.sql("DROP TABLE IF EXISTS good_student_infos"); goodStudentsDF.registerTempTable("goodstudent");
DataFrame result = hiveContext.sql("select * from goodstudent");
result.show(); /**
* 将结果保存到hive表 good_student_infos
*/
goodStudentsDF.write().mode(SaveMode.Overwrite).saveAsTable("good_student_infos"); Row[] goodStudentRows = hiveContext.table("good_student_infos").collect();
for(Row goodStudentRow : goodStudentRows) {
System.out.println(goodStudentRow);
}
sc.stop();
scala代码:
val conf = new SparkConf()
conf.setAppName("HiveSource")
val sc = new SparkContext(conf)
/**
* HiveContext是SQLContext的子类。
*/
val hiveContext = new HiveContext(sc)
hiveContext.sql("use spark")
hiveContext.sql("drop table if exists student_infos")
hiveContext.sql("create table if not exists student_infos (name string,age int) row format delimited fields terminated by '\t'")
hiveContext.sql("load data local inpath '/root/test/student_infos' into table student_infos") hiveContext.sql("drop table if exists student_scores")
hiveContext.sql("create table if not exists student_scores (name string,score int) row format delimited fields terminated by '\t'")
hiveContext.sql("load data local inpath '/root/test/student_scores' into table student_scores") val df = hiveContext.sql("select si.name,si.age,ss.score from student_infos si,student_scores ss where si.name = ss.name")
hiveContext.sql("drop table if exists good_student_infos")
/**
* 将结果写入到hive表中
*/
df.write.mode(SaveMode.Overwrite).saveAsTable("good_student_infos") sc.stop()
结果:
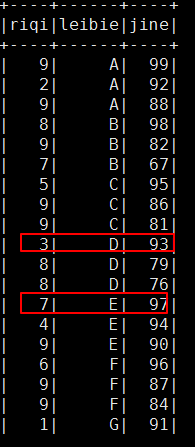
可以看到分组内有序,组间并不是有序的!!!!
【Spark篇】---SparkSQL on Hive的配置和使用的更多相关文章
- hive on spark VS SparkSQL VS hive on tez
http://blog.csdn.net/wtq1993/article/details/52435563 http://blog.csdn.net/yeruby/article/details/51 ...
- [Spark]Spark-sql与hive连接配置
一.在Mysql中配置hive数据库 创建hive数据库,刷新root用户权限 create database hive; grant all on *.* to root@'; flush priv ...
- Spark之 SparkSql整合hive
整合: 1,需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置. 2,如果Hive的元数据存放在Mysql中,我们还需 ...
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- SparkSQL和hive on Spark
SparkSQL简介 SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-h ...
- Hive On Spark和SparkSQL
SparkSQL和Hive On Spark都是在Spark上实现SQL的解决方案.Spark早先有Shark项目用来实现SQL层,不过后来推翻重做了,就变成了SparkSQL.这是Spark官方Da ...
- 【Spark篇】---SparkSQL初始和创建DataFrame的几种方式
一.前述 1.SparkSQL介绍 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制. SparkSQL支持查询原 ...
- SparkSQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- SparkSQL与Hive on Spark
SparkSQL与Hive on Spark的比较 简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapR ...
随机推荐
- Thread类和Runnable接口实现多线程--2019-4-18
1.通过Thread实现 public class TestThread extends Thread{ public TestThread(String name) { super(name); } ...
- 吻逗死(windows)系统下自动部署脚本(for java spring*)及linux命令行工具
转载请注明出处:https://www.cnblogs.com/funnyzpc/p/10051647.html (^^)(^^)自動部署腳本原本在上個公司就在使用,由於近期同事需要手動部署一個Spr ...
- asp.net 跨域请求
微软官方文档 https://docs.microsoft.com/zh-cn/aspnet/core/security/cors?view=aspnetcore-2.2
- toLatin1 qt
Latin1是ISO-8859-1的别名,有些环境下写作Latin-1.ISO-8859-1ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F ...
- Windows下Flume的安装
flume(日志收集系统) Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flum ...
- Reveal : Xcode辅助界面调试工具
Reveal简介: Reveal是一款iOS界面调试工具,辅助Xcode进行界面调试,使用它可以在iOS开发的时候动态的查看和修改应用程序的界面. 软件下载 首先去官网下载Reveal,下载地址:ht ...
- angular.js学习笔记(一)
1.angular单项数据绑定 2.不要使用控制器的时候: 任何形式的DOM操作:控制器只应该包含业务逻辑.DOM操作则属于应用程序的表现层逻辑操作,向来以测试难度之高闻名于业界.把任何表现层的逻辑放 ...
- 判断以xx开头的字符串
public static void main(String[] args) { String str = "EAN_13,1534651"; String strHttp = & ...
- win10常用详细快捷键大全
• 贴靠窗口:Win +左/右> Win +上/下>窗口可以变为1/4大小放置在屏幕4个角落• 切换窗口:Alt + Tab(不是新的,但任务切换界面改进)• 任务视图:Win + Tab ...
- 初学Socket通信
1.Socket:Socket就是套接字.客户端与服务器之间通信用的.Socket接口是TCP/IP网络的API. 2.SYN是TCP/IP建立连接时使用的握手信号.在客户端和服务器之间建立正常的TC ...