over partition by与group by
over partition by与group by 的区别
http://www.cnblogs.com/scottpei/archive/2012/02/16/2353718.html
今天看到一个老兄的问题,
大概如下:
查询出部门的最低工资的userid 号
表结构: D号 工资 部门
userid salary dept 有一个高人给出了一种答案:
SELECT MIN (salary) OVER (PARTITION BY dept ) salary, dept
FROM ss 运行后得到: 楼主那位老兄一看觉得很高深。大叹真是高人阿~
我也觉得这位老兄实在是高啊。 但我仔细研究一下发现那位老兄对PARTITION BY的用法理解并不深刻。并没有解决楼主的问题。
大家请看我修改后的语句
SELECT userid,salary,dept,MIN (salary) OVER (PARTITION BY dept ) salary
FROM ss 运行后的结果:
userid salary dept MIN (salary) OVER (PARTITION BY dept ) 大家看出端倪了吧。
高深的未必适合。 一下是我给出的答案:
SELECT * FROM SS
INNER JOIN (SELECT MIN(SALARY) AS SALARY, DEPT FROM SS GROUP BY DEPT) SS2
USING(SALARY,DEPT) 运行后的结果:
salary dept userid 由此我想到总结一下group by和partition by的用法
group by是对检索结果的保留行进行单纯分组,一般总爱和聚合函数一块用例如AVG(),COUNT(),max(),main()等一块用。 partition by虽然也具有分组功能,但同时也具有其他的功能。
它属于oracle的分析用函数。
借用一个勤快人的数据说明一下: sum() over (PARTITION BY ...) 是一个分析函数。 他执行的效果跟普通的sum ...group by ...不一样,它计算组中表达式的累积和,而不是简单的和。 表a,内容如下:
B C D select b,c,sum(d) e from a group by b,c
得到:
B C E 而使用分析函数得到的结果是:
SELECT b, c, d, SUM(d) OVER(PARTITION BY b,c ORDER BY d) e FROM a
B C E 结果不一样,这样看还不是很清楚,我们把d的内容也显示出来就更清楚了:
SELECT b, c, d,SUM(d) OVER(PARTITION BY b,c ORDER BY d) e FROM a
B C D E
d=,sum(d)=
d=,sum(d)=
d=,sum(d)=
c值不同,重新累计
http://www.cnblogs.com/lanzi/archive/2010/10/26/1861338.html
OVER(PARTITION BY)函数介绍
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化,举例如下:
1:over后的写法:
over(order by salary) 按照salary排序进行累计,order by是个默认的开窗函数 over(partition by deptno)按照部门分区
2:开窗的窗口范围: over(order by salary range between 5 preceding and 5 following):窗口范围为当前行数据幅度减5加5后的范围内的。
举例:
--sum(s)over(order by s range between 2 preceding and 2 following) 表示加2或2的范围内的求和
select name,class,s, sum(s)over(order by s range between 2 preceding and 2 following) mm from t2 adf 3 45 45 --45加2减2即43到47,但是s在这个范围内只有45 asdf 3 55 55 cfe 2 74 74 3dd 3 78 158 --78在76到80范围内有78,80,求和得158 fda 1 80 158 gds 2 92 92 ffd 1 95 190 dss 1 95 190 ddd 3 99 198
gf 3 99 198
举例:
3、与over函数结合的几个函数介绍
下面以班级成绩表t2来说明其应用
t2表信息如下: cfe 2 74 dss 1 95 ffd 1 95 fda 1 80 gds 2 92 gf 3 99 ddd 3 99 adf 3 45 asdf 3 55 3dd 3 78
select * from ( select name,class,s,rank()over(partition by class order by s desc) mm from t2 ) where mm=1; 得到的结果是: dss 1 95 1 ffd 1 95 1 gds 2 92 1 gf 3 99 1 ddd 3 99 1
注意: 1.在求第一名成绩的时候,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果; select * from ( select name,class,s,row_number()over(partition by class order by s desc) mm from t2 ) where mm=1; 1 95 1 --95有两名但是只显示一个 2 92 1 3 99 1 --99有两名但也只显示一个
2.rank()和dense_rank()可以将所有的都查找出来: 如上可以看到采用rank可以将并列第一名的都查找出来; rank()和dense_rank()区别: --rank()是跳跃排序,有两个第二名时接下来就是第四名; select name,class,s,rank()over(partition by class order by s desc) mm from t2 dss 1 95 1 ffd 1 95 1 fda 1 80 3 --直接就跳到了第三 gds 2 92 1 cfe 2 74 2 gf 3 99 1 ddd 3 99 1 3dd 3 78 3 asdf 3 55 4 adf 3 45 5 --dense_rank()l是连续排序,有两个第二名时仍然跟着第三名 select name,class,s,dense_rank()over(partition by class order by s desc) mm from t2 dss 1 95 1 ffd 1 95 1 fda 1 80 2 --连续排序(仍为2) gds 2 92 1 cfe 2 74 2 gf 3 99 1 ddd 3 99 1 3dd 3 78 2 asdf 3 55 3 adf 3 45 4
--sum()over()的使用
select name,class,s, sum(s)over(partition by class order by s desc) mm from t2 --根据班级进行分数求和 dss 1 95 190 --由于两个95都是第一名,所以累加时是两个第一名的相加 ffd 1 95 190 fda 1 80 270 --第一名加上第二名的 gds 2 92 92 cfe 2 74 166 gf 3 99 198 ddd 3 99 198 3dd 3 78 276 asdf 3 55 331 adf 3 45 376
first_value() over()和last_value() over()的使用
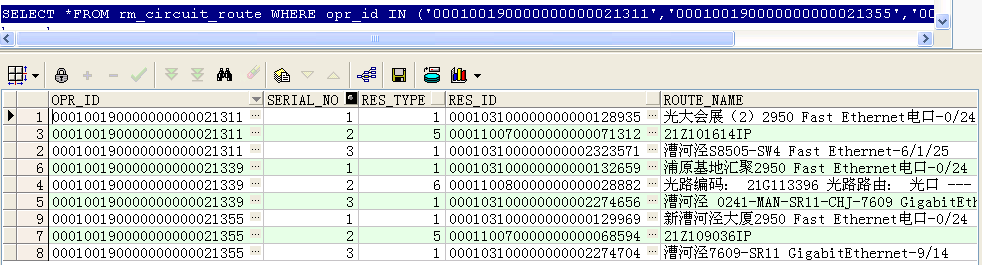
--找出这三条电路每条电路的第一条记录类型和最后一条记录类型
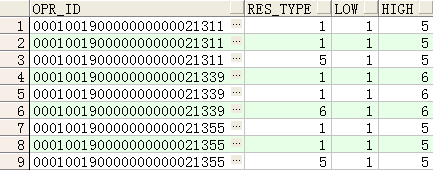
注:rows BETWEEN unbounded preceding AND unbounded following 的使用
--取last_value时不使用rows BETWEEN unbounded preceding AND unbounded following的结果
如下图可以看到,如果不使用

数据如下:

取出该电路的第一条记录,加上ignore nulls后,如果第一条是判断的那个字段是空的,则默认取下一条,结果如下所示:

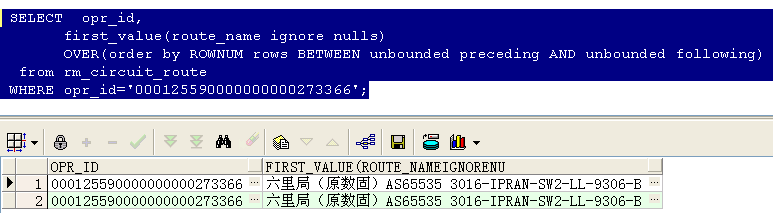
--lead() over()函数用法(取出后N行数据)
lead(expresstion,<offset>,<default>) with a as (select 1 id,'a' name from dual union select 2 id,'b' name from dual union select 3 id,'c' name from dual union select 4 id,'d' name from dual union select 5 id,'e' name from dual ) select id,name,lead(id,1,'')over(order by name) from a;
--ratio_to_report(a)函数用法 Ratio_to_report() 括号中就是分子,over() 括号中就是分母
with a as (select 1 a from dual union all select 1 a from dual union all select 1 a from dual union all select 2 a from dual union all select 3 a from dual union all select 4 a from dual union all select 4 a from dual union all select 5 a from dual ) select a, ratio_to_report(a)over(partition by a) b from a order by a;
with a as (select 1 a from dual union all select 1 a from dual union all select 1 a from dual union all select 2 a from dual union all select 3 a from dual union all select 4 a from dual union all select 4 a from dual union all select 5 a from dual ) select a, ratio_to_report(a)over() b from a --分母缺省就是整个占比 order by a;
with a as (select 1 a from dual union all select 1 a from dual union all select 1 a from dual union all select 2 a from dual union all select 3 a from dual union all select 4 a from dual union all select 4 a from dual union all select 5 a from dual ) select a, ratio_to_report(a)over() b from a group by a order by a;--分组后的占比
![]()



SAMPLE:下例中0.7的分布值在部门30中没有对应的Cume_Dist值,所以就取下一个分布值0.83333333所对应的SALARY来替代
SELECT ename, sal, deptno, percentile_disc(0.7) within GROUP(ORDER BY sal) over(PARTITION BY deptno) "Percentile_Disc", cume_dist() over(PARTITION BY deptno ORDER BY sal) "Cume_Dist" FROM emp WHERE deptno IN (30, 60);

over partition by与group by的更多相关文章
- over partition by与group by 的区别
(本文摘自scottpei的博客) over partition by与group by 的区别 今天看到一个老兄的问题, 大概如下: 查询出部门的最低工资的userid 号 表结构: D号 ...
- SQL Server - Partition by 和 Group by对比
参考:https://www.cnblogs.com/hello-yz/p/9962356.html —————————————————— 今天大概弄懂了partition by和group by的区 ...
- sqlserver中分区函数 partition by与 group by 区别 删除关键字段重复列
partition by关键字是分析性函数的一部分,它和聚合函数(如group by)不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录, partition by ...
- partition by和group by对比
今天大概弄懂了partition by和group by的区别联系. 1. group by是分组函数,partition by是分析函数(然后像sum()等是聚合函数): 2. 在执行顺序上, 以下 ...
- SQL:over partition by与group by 的区别
group by是对检索结果的保留行进行单纯分组,一般总爱和聚合函数一块用例如AVG(),COUNT(),max(),main()等一块用. partition by虽然也具有分组功能,但同时也具有其 ...
- PARTITION BY 和 group by
sum() over (PARTITION BY ...) 是一个分析函数. 他执行的效果跟普通的sum ...group by ...不一样,它计算组中表达式的累 ...
- sql server partition分区与group by 分组
例子:在一个StudentScore表中,有序号ID,班级ClassId,学生姓名Name,性别Sex,语文成绩ChineseScore,数学成绩MathScore,平均成绩AverageScore等 ...
- MSSQL Server中partition by与group by的区别
在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by(但此排序顺序优先级是最高的)”的执行. ①group by 列名 合并(列值相同的并作一 ...
- SQL Server: Difference between PARTITION BY and GROUP BY
https://stackoverflow.com/questions/2404565/sql-server-difference-between-partition-by-and-group-by ...
随机推荐
- oracle--存储过程2--bk
oracle存储过程demo1---无返回值的存储过程: /* 写一个过程,可以向book表添加书 */ create table book( id number(4), book_name varc ...
- Python模块-requests(二)
会话对象 会话对象能够跨请求保持某些参数. 它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 urllib3 的 connection pooling 功能. 所以 ...
- iconv字符转换
iconv是linux下的编码转换的工具,它提供命令行的使用和函数接口支持 函数接口 iconv函数族的头文件是iconv.h,使用前需包含之.#include <iconv.h> ico ...
- Shrio00 Shiro认证登录、权限管理环境搭建
基础环境准备: JDK -> java version "1.8.0_101" MAVEN -> Apache Maven 3.5.0 1 导入依赖 mysql驱动 m ...
- Leetcode: 67. Add Binary
二进制加法 https://discuss.leetcode.com/topic/33693/another-simple-java public String addBinary(String a, ...
- 【机器学习】分类器组合——AdaBoost
AdaBoost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器). AdaBoost其实只是boost的一个特 ...
- 5.docker的疑难杂症
根据官方文档:https://docs.docker.com/install/linux/docker-ce/centos/搭建docker 1.卸载docker旧版本: sudo yum remov ...
- 关于java中的编码问题
ok,今天搞了一天都在探索java字符的编码问题.十分头疼.最后终于得出几点: 1.网上有很多博客说判断一个String的编码的方法是通过如下代码;但其实这个代码完全是错的,用一种编码decode后, ...
- Saving output of a grep into a file with colors
19 down vote favorite 7 I need to save the result of a grep command into a file, but I also want the ...
- 【msyql_获取时间的前后几天函数date_sub】
select now()-- 2017-05-16 16:48:02select curdate() -- 2017-05-16 select curdate() + 1 -- 20170517 s ...