初识 Redis
浏览目录
什么是Redis?
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
用于操作内存的软件。
redis是一个软件,帮助开发者对一台机器的内存进行操作。
要与mysql区分开。
mysql是一个软件,帮助开发者对一台机器的硬盘进行操作。
Redis的特点
- 可以做持久化
- AOF
- RDB
- 相当于是大字典
- 单进程单线程
- 五大数据类型
redis={
k1:'123', 字符串
k2:[1,2,3,4,4,2,1], 列表
k3:{1,2,3,4}, 集合
k4:{name:123,age:666}, 字典
k5:{('alex',60),('eva-j',80),('rt',70),},有序集合
}
Redis安装和基本使用:
下载安装包
wget http://download.redis.io/releases/redis-3.0.6.tar.gz
解压及安装
tar xzf redis-3.0.6.tar.gz
cd redis-3.0.6
make
启动服务端
cd redis-4.0.6
redis-server ./redis.conf
启动客户端
src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
记得关闭防火墙
firewall-cmd --state # 查看防火墙 (关闭后显示not running,开启后显示running)
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
python连接redis的模块
在终端输入:
pip3 install redis
API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print r.get('foo')
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
本质:维护一个已经和服务端连接成功的socket。以后再次发送数据时,直接获取一个socket,直接send数据。
#!/usr/bin/env python
# -*- coding:utf-8 -*- import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
3、操作
string操作
redis中的String在在内存中按照一个name对应一个value来存储。如图:

set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
Hash操作
redis中Hash在内存中的存储格式如下图:
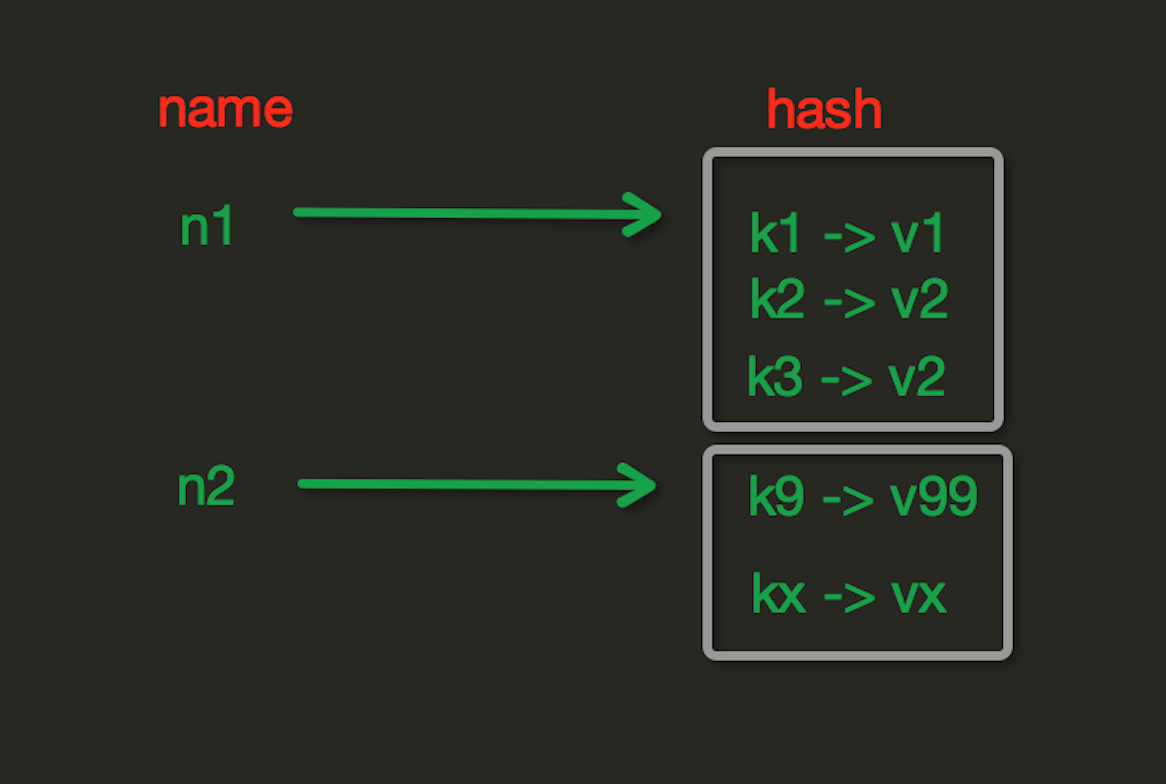
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value # 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 # 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3 # 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name)
获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数) # 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如:
# for item in r.hscan_iter('xx'):
# print item
使用字典:
- 基本操作
- 慎重使用hgetall, 优先使用 hscan_iter
- 计数器
注意事项:redis操作时,只有第一层value支持:list,dict ....
List操作
redis中的List在在内存中按照一个name对应一个List来存储。如图:

lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 # 如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11 # 扩展:
# rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 # 更多:
# rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值 # 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值 # 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值 # 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 # 更多:
# rpop(name) 表示从右向左操作
lindex(name, index)
在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素 # 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞 # 更多:
# r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧 # 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
# 1、获取name对应的所有列表
# 2、循环列表
# 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能: def list_iter(name):
"""
自定义redis列表增量迭代
:param name: redis中的name,即:迭代name对应的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in xrange(list_count):
yield r.lindex(name, index) # 使用
for item in list_iter('pp'):
print item
初识 Redis的更多相关文章
- 初识redis数据类型
初识redis数据类型 1.String(字符串) string是redis最基本的类型,一个key对应一个value. string类型是二进制安全的.意思是redis的string可以包含任何数据 ...
- Redis——学习之路三(初识redis config配置)
我们先看看config 默认情况下系统是怎么配置的.在命令行中输入 config get *(如图) 默认情况下有61配置信息,每一个命令占两行,第一行为配置名称信息,第二行为配置的具体信息. ...
- Redis——学习之路二(初识redis服务器命令)
上一章我们已经知道了如果启动redis服务器,现在我们来学习一下,以及如何用客户端连接服务器.接下来我们来学习一下查看操作服务器的命令. 服务器命令: 1.info——当前redis服务器信息 s ...
- 01:初识Redis
付磊和张益军两位大咖写的葵花宝典(Redis开发和运维)学习笔记. 一.初识Redis 1.redis简介 Redis是一种基于键值对(key-value)的NoSQL数据库,与很多键值对数据库不同的 ...
- redis实战笔记(1)-第1章 初识Redis
第1章 初识Redis 注:本书在redis3.0版本的,比如redis3.0以后支持服务端集群.3.0之前只能客户端分片. 本章主要内容 1.Redis与其他软件的相同之处和不同之处 2.Re ...
- Linux(5)- MariaDB、mysql主从复制、初识redis
一.MYSQL(mariadb) MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可. 开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL ...
- 分布式数据存储 之 Redis(一) —— 初识Redis
分布式数据存储 之 Redis(一) -- 初识Redis 为什么要学习并运用Redis?Redis有什么好处?我们步入Redis的海洋,初识Redis. 一.Redis是什么 Redis 是一个 ...
- [转]Redis之(一)初识Redis
原文地址:http://blog.csdn.net/u012152619/article/details/52550315 Redis之(一)初识Redis 标签: Redisredis-server ...
- 1.初识Redis
作者 微信:tangy8080 电子邮箱:914661180@qq.com 更新时间:2019-08-14 20:35:36 星期三 欢迎您订阅和分享我的订阅号,订阅号内会不定期分享一些我自己学习过程 ...
- Redis——学习之路一(初识redis)
在接下来的一段时间里面我要将自己学习的redis整理一遍,下面是我整理的一些资料: Redis是一款依据BSD开源协议发行的高性能Key-Value存储系统(cache and store),所以re ...
随机推荐
- 网络编程基础--多线程---concurrent.futures 模块---事件Event---信号量Semaphore---定时器Timer---死锁现象 递归锁----线程队列queue
1 concurrent.futures 模块: # from abc import abstractmethod,ABCMeta # # class A(metaclass=ABCMeta): # ...
- fastCGI模块
这个模块允许nginx同FastCGI协同工作,并且控制哪些参数将被安全传递.例: location / { fastcgi_pass localhost:9000; fastcgi_index in ...
- POJ2985 The k-th Largest Group (并查集+treap)
Newman likes playing with cats. He possesses lots of cats in his home. Because the number of cats is ...
- IP地址的基础划分
1.基础知识 1.1 IP地址是由网络号(net ID)与主机号(host ID)两部分组成的. 1.2 IP地址的分类 IP地址长度为32位,点分十进制(dotted decimal)地址: 采 ...
- AtCoder Beginner Contest 087 B - Coins
Time limit : 2sec / Memory limit : 256MB Score : 200 points Problem Statement You have A 500-yen coi ...
- Codeforces 786B. Legacy 线段树+spfa
题目大意: 给定一个\(n\)的点的图.求\(s\)到所有点的最短路 边的给定方式有三种: \(u \to v\) \(u \to [l,r]\) \([l,r] \to v\) 设\(q\)为给定边 ...
- spark 单机版安装
jdk-8u73-linux-x64.tar.gz hadoop-2.6.0.tar.gz scala-2.10.6.tgz spark-1.6.0-bin-hadoop2.6.tgz 1.安装jdk ...
- linux开发核心理解
目录 授权 致谢 序言 更新纪录 导读 如何写作科技文档 I. 气候 1. GUI? CLI? 2. UNIX 缩写风格 3. 版本号的迷雾 4. Vim 还是 Emacs 5. DocBoo ...
- 宝塔中的 base_opendir chattr
宝塔中的 base_opendir chattr base_opendir 目的是限制一些函数将手乱伸. 而宝塔中的自动配置的是 .user.ini,这个是文件是 +i ............ 这个 ...
- linux kernel menuconfig【转载】
原文网址:http://www.cnblogs.com/kulin/archive/2013/01/04/linux-core.html Linux内核裁减 (1)安装新内核: i)将新内核copy到 ...