spark streaming的应用
今天我们讲spark streaming的应用,这个是实时处理的,类似于Storm以及Flink相关的知识点,
说来也巧,今天的自己也去听了关于Flink的相关的讲座,可惜自己没有听得特别清楚,好像是
spark streaming与flink是竞争关系,好了,我们进入今天的主题吧
1.一般会做用户画像的差不多集中在两个行业,电商以及广告行业
一般根据现实给这个人打上一个标签,在根据标签来确定画像
2.如果一个人不登录,怎样确定这个人的详情
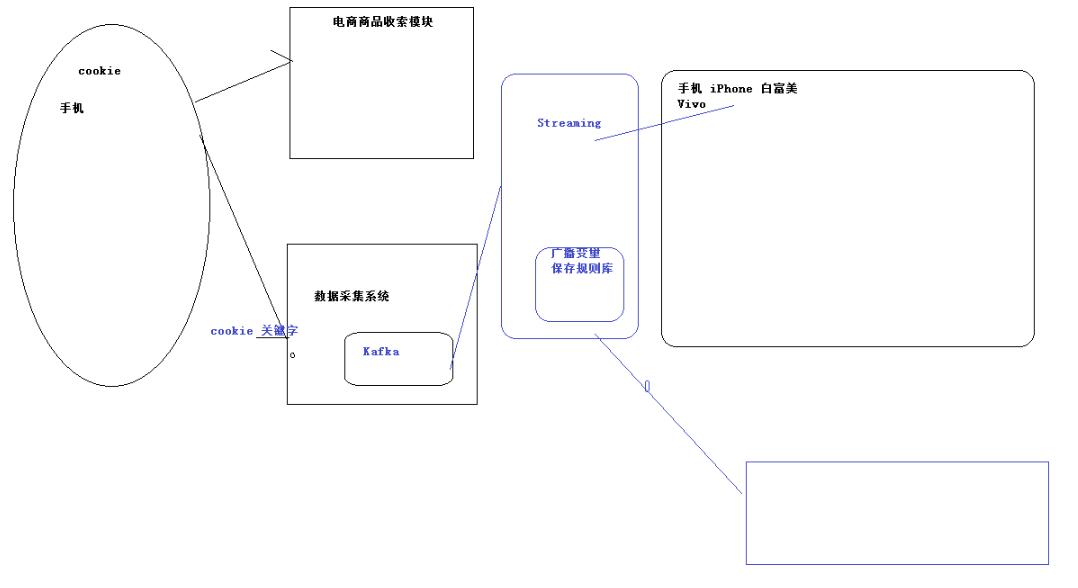
这个就是spark streaming的应用
nc -lk 8888 这个端口可以一直发送数据
请记住,spark中产生的rdd,可能会由于某种意外的原因,从而这个计算可能就要重新开始计算,
但是假如我们设置了checkpoint(如果多个进程同时开始的话,我们可以搞一个共享存储)的时候,
就可以保存这个值,当再一次出现意外的时候,就可以从恢复的这个值重新读取
对于map来说,可以map(),同时也可以map{},这样的两种表达形式,不过当我们写成了case()的
这种形式,则我们必须使用map的大括号的这种形式了,后文附带代码
package cn.wj.spark.day09
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* Created by WJ on 2017/1/18.
*/
object StateFulWordCount {
//Seq这个批次某个单词的次数
//Option[Int]:以前的结果
//(hello,1),(hello,1),(tom,1)
//(hello,Seq(1,1)),(tom,Seq(1))
//此时x=>String(Key的值),y=>Seq[Int](当前的这个value的值),z=>Option[Int],这个代表的是以前的value的值
val updateFunc = (iter:Iterator[(String,Seq[Int],Option[Int])]) =>{
iter.flatMap{case(x,y,z) => Some(y.sum+z.getOrElse()).map(m =>(x,m))}
}
def main(args: Array[String]): Unit = {
LoggerLevels.setStreamingLogLevels()
//StreamingContext
val conf = new SparkConf().setAppName("StreamingContext").setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setCheckpointDir("/tmp/ck")
// sc.setCheckpointDir("hdfs://192.168.109.136:9000/person/myfile")
val ssc = new StreamingContext(sc,Seconds())
val ds = ssc.socketTextStream("192.168.109.136",)
//updateStateByKey:这个方法的意思是说将每一次的partition都进行一次累计
val result = ds.flatMap(_.split(" ")).map((_,)).updateStateByKey(updateFunc,new HashPartitioner(sc.defaultParallelism),true)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
其中,LoggerLevels.setStreamingLogLevels()这个是设置日志文件的显示情况的,是让打出来的日志更清晰,
如果没必要,可以删除的。
首先我们在linux里面向8888端口发送信息:
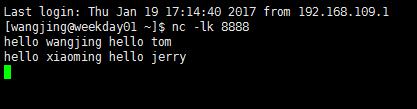
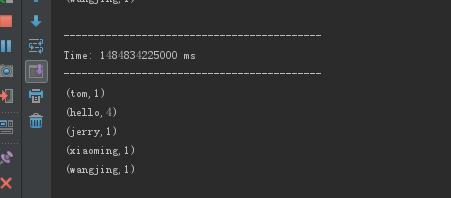
然后启动项目,这个时候就可以看见这个效果了(可以叠加的spark streaming)
spark streaming的应用的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- spark streaming kafka example
// scalastyle:off println package org.apache.spark.examples.streaming import kafka.serializer.String ...
- Spark Streaming中动态Batch Size实现初探
本期内容 : BatchDuration与 Process Time 动态Batch Size Spark Streaming中有很多算子,是否每一个算子都是预期中的类似线性规律的时间消耗呢? 例如: ...
- Spark Streaming源码解读之No Receivers彻底思考
本期内容 : Direct Acess Kafka Spark Streaming接收数据现在支持的两种方式: 01. Receiver的方式来接收数据,及输入数据的控制 02. No Receive ...
- Spark Streaming架构设计和运行机制总结
本期内容 : Spark Streaming中的架构设计和运行机制 Spark Streaming深度思考 Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行 ...
- Spark Streaming中空RDD处理及流处理程序优雅的停止
本期内容 : Spark Streaming中的空RDD处理 Spark Streaming程序的停止 由于Spark Streaming的每个BatchDuration都会不断的产生RDD,空RDD ...
- Spark Streaming源码解读之State管理之UpdataStateByKey和MapWithState解密
本期内容 : UpdateStateByKey解密 MapWithState解密 Spark Streaming是实现State状态管理因素: 01. Spark Streaming是按照整个Bach ...
随机推荐
- Unified Service Desk Overview
As we implement CRM in enterprise, we usually integrate with many other information system such as E ...
- 一、Dapper基本操作
参考资料:Cooper Liu 毒逆天 一.Dapper安装 添加引用-->NuGet管理-->搜索Dapper-->安装 二.新建表 --创建一个员工表 create table ...
- python3线程介绍01(如何启动和调用线程)
#!/usr/bin/env python# -*- coding:utf-8 -*- import osimport time,randomimport threading # 1-进程说明# 进程 ...
- 原生Js在各大浏览器上、火狐、ie、谷歌、360等出现的不兼容问题。
1 document.getElementsByName("name") 在Ie低版本,360普通版本,以及火狐低版本不支持. 2 element.innerText 在低版本的 ...
- java 中的Number类 Character类 String类 StringBuffer类 StringBuilder类
1. Number类 Java语言为每一个内置数据类型提供了对应的包装类.所有的包装类(Integer.Long.Byte.Double.Float.Short)都是抽象类Number的子类.这种由编 ...
- mysql全部基本数据类型
MySQL基本数据类型统计http://www.cnblogs.com/xuqiang/archive/2010/10/14/1953464.html 详细介绍http://www.cnblogs.c ...
- 创建 XXXXXXXX 的配置节处理程序时出错: 请求失败
今天碰到这个错误,之前的程序在测试的时候都没有问题,同样的程序打包通过QQ传给其他人,在XP下测试也没有问题,我的Win7系统从QQ信箱下载压缩包,解压之后执行程序就会出问题,本来还是考虑自己程序是不 ...
- Java 文件切割工具类
Story: 发送MongoDB 管理软件到公司邮箱,工作使用. 1.由于公司邮箱限制附件大小,大文件无法发送,故做此程序用于切割大文件成多个小文件,然后逐个发送. 2.收到小文件之后,再重新组合成原 ...
- 【洛谷P1962】斐波那契数列
斐波那契数列 题目链接:https://www.luogu.org/problemnew/show/P1962 矩阵A 1,1 1,0 用A^k即可求出feb(k). 矩阵快速幂 #include&l ...
- RHEL7.X安装12.2RAC时root.sh错误CLSRSC-400的解决方案
问题现象: [root@ora12c ghome]# /opt/oracle/ghome/root.sh Performing root user operation. The following e ...