大数据学习——关于hive中的各种join
准备数据
2,b
3,c
4,d
7,y
8,u 2,bb
3,cc
7,yy
9,pp
建表:
create table a(id int,name string)
row format delimited fields terminated by ','; create table b(id int,name string)
row format delimited fields terminated by ',';
导入数据:
load data local inpath '/root/hivedata/a.txt' into table a;
load data local inpath '/root/hivedata/b.txt' into table b;
inner join 只打印能匹配上的数据,没有匹配上的不输出
select * from a inner join b on a.id =b.id;
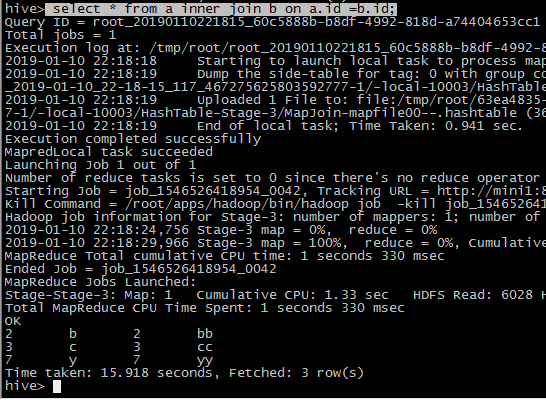
left join
select * from a left join b on a.id=b.id;
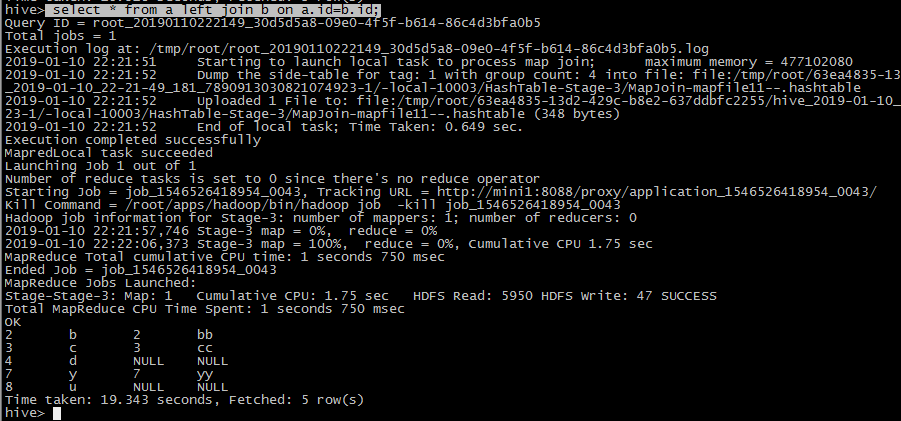
right join
select * from a right join b on a.id=b.id;

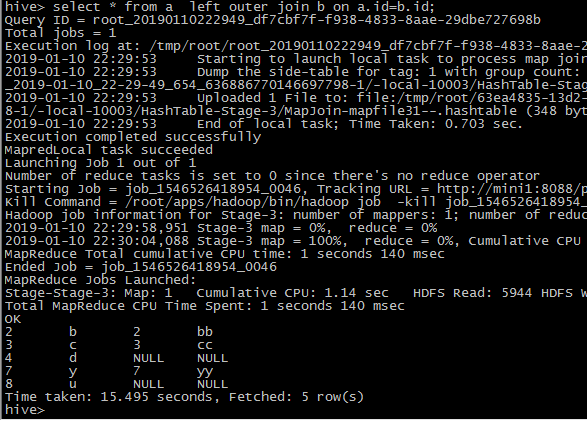
full outer join
select * from a full outer join b on a.id=b.id;

left outer join
left semi join
select * from a left semi join b on a.id=b.id;
相当于
select * from a where a.id exists(select b.id from b); 在hive中效率极低

大数据学习——关于hive中的各种join的更多相关文章
- 大数据学习之Scala中main函数的分析以及基本规则(2)
一.main函数的分析 首先来看我们在上一节最后看到的这个程序,我们先来简单的分析一下.有助于后面的学习 object HelloScala { def main(args: Array[String ...
- 大数据学习笔记——Hive完整部署流程
Hive详细部署教程 此篇博客承接上篇Hadoop和Zookeeper的部署教程,将会详细地对HIve的部署做一个整理,Hive相当于是封装在HDFS和Mapreduce上的一套sql引擎,只需要安装 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
随机推荐
- AtCoder Grand Contest 012 A
A - AtCoder Group Contest Time limit : 2sec / Memory limit : 256MB Score : 300 points Problem Statem ...
- luogu P3371 & P4779 单源最短路径spfa & 最大堆优化Dijkstra算法
P3371 [模板]单源最短路径(弱化版) 题目背景 本题测试数据为随机数据,在考试中可能会出现构造数据让SPFA不通过,如有需要请移步 P4779. 题目描述 如题,给出一个有向图,请输出从某一点出 ...
- IIR型高斯滤波的原理及实现
二.实现 GIMP中有IIR型高斯滤波的实现,代码位于contrast-retinex.c中,读者可自行查看.下面给出本人实现的核心代码: #include"stdafx.h" t ...
- C. Arcade dp二维费用背包 + 滚动数组 玄学
http://codeforces.com/gym/101257/problem/C 询问从左上角走到右下角,每次只能向右或者向左,捡起三种物品算作一个logo,求最多能得到多少个logo. 设dp[ ...
- shell expect
关键的action spawn 调用要执行的命令expect 捕捉用户输入的提示 send 发送需要交互的值,替代了用户手动输入内容set 设置变量值 ...
- Apache Kylin Cube 的存储
不多说,直接上干货! 简单的说Cuboid的维度会映射为HBase的Rowkey,Cuboid的指标会映射为HBase的Value. Cube映射成HBase存储 如上图原始表所示:Hive表有两个维 ...
- 分享几个自己喜欢的前端UI框架
http://www.layui.com/ http://element-cn.eleme.io/#/zh-CN/component/installation
- IOS文件下载
NSArray *documentPaths = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, ...
- vs2010 在函数级别设置优化
平时开发的时候,为了方便调试,visual studio 的Configuration 设置成Release. 同时为了事后调试,Optimization总是设置成Disabled.这样做是方便查看变 ...
- Android(java)学习笔记177: 服务(service)之音乐播放器
1.我们播放音乐,希望在后台长期运行,不希望因为内存不足等等原因,从而导致被gc回收,音乐播放终止,所以我们这里使用服务Service创建一个音乐播放器. 2.创建一个音乐播放器项目(使用服务) (1 ...