SpringBoot项目整合Druid进行统计监控
0、druid介绍,参考官网
1、在项目的POM文件中添加alibaba的druid依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.27</version>
</dependency>
2、在属性配置文件
# 数据库访问配置 # 主数据源,默认的 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.driver-class-name=com.MySQL.jdbc.Driver spring.datasource.url=jdbc:MySQL://localhost:3306/XXX spring.datasource.username=xxx spring.datasource.password=xxxx # 下面为连接池的补充设置,应用到上面所有数据源中 # 初始化大小,最小,最大 spring.datasource.initialSize=5 spring.datasource.minIdle=5 spring.datasource.maxActive=20 # 配置获取连接等待超时的时间 spring.datasource.maxWait=60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 spring.datasource.timeBetweenEvictionRunsMillis=60000 # 配置一个连接在池中最小生存的时间,单位是毫秒 spring.datasource.minEvictableIdleTimeMillis=300000 spring.datasource.validationQuery=SELECT 1 FROM DUAL spring.datasource.testWhileIdle=true spring.datasource.testOnBorrow=false spring.datasource.testOnReturn=false # 打开PSCache,并且指定每个连接上PSCache的大小 spring.datasource.poolPreparedStatements=true spring.datasource.maxPoolPreparedStatementPerConnectionSize=20 # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 spring.datasource.filters=stat,wall,log4j # 通过connectProperties属性来打开mergeSql功能;慢SQL记录 spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 # 合并多个DruidDataSource的监控数据 #spring.datasource.useGlobalDataSourceStat=true
需要注意的是:spring.datasource.type旧的spring boot版本是不能识别的。
3、引入WebServlet
import com.alibaba.druid.support.http.StatViewServlet;
import javax.servlet.annotation.WebInitParam;
import javax.servlet.annotation.WebServlet; /**
* Created by hao on 2017/6/20.
*/
@SuppressWarnings("serial")
@WebServlet(urlPatterns = "/druid/*",
initParams={
@WebInitParam(name="allow",value=""),// IP白名单 (没有配置或者为空,则允许所有访问)
//@WebInitParam(name="deny",value=""),// IP黑名单 (存在共同时,deny优先于allow)
//@WebInitParam(name="loginUsername",value=""),// 用户名
//@WebInitParam(name="loginPassword",value=""),// 密码
@WebInitParam(name="resetEnable",value="false")// 禁用HTML页面上的“Reset All”功能
})
public class DruidStatViewServlet extends StatViewServlet{
}
4、引入Filter
import com.alibaba.druid.support.http.WebStatFilter;
import javax.servlet.annotation.WebFilter;
import javax.servlet.annotation.WebInitParam; /**
* Created by hao on 2017/6/20.
*/
@WebFilter(filterName="druidWebStatFilter",urlPatterns="/*",
initParams={
@WebInitParam(name="exclusions",value="*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*")// 忽略资源
})
public class DruidStatFilter extends WebStatFilter{
}
5、切记在启动类加入
@ServletComponentScan
6、在需要进行显示监控统计的地方,插入URL /druid,即可访问。
7、效果图如下:
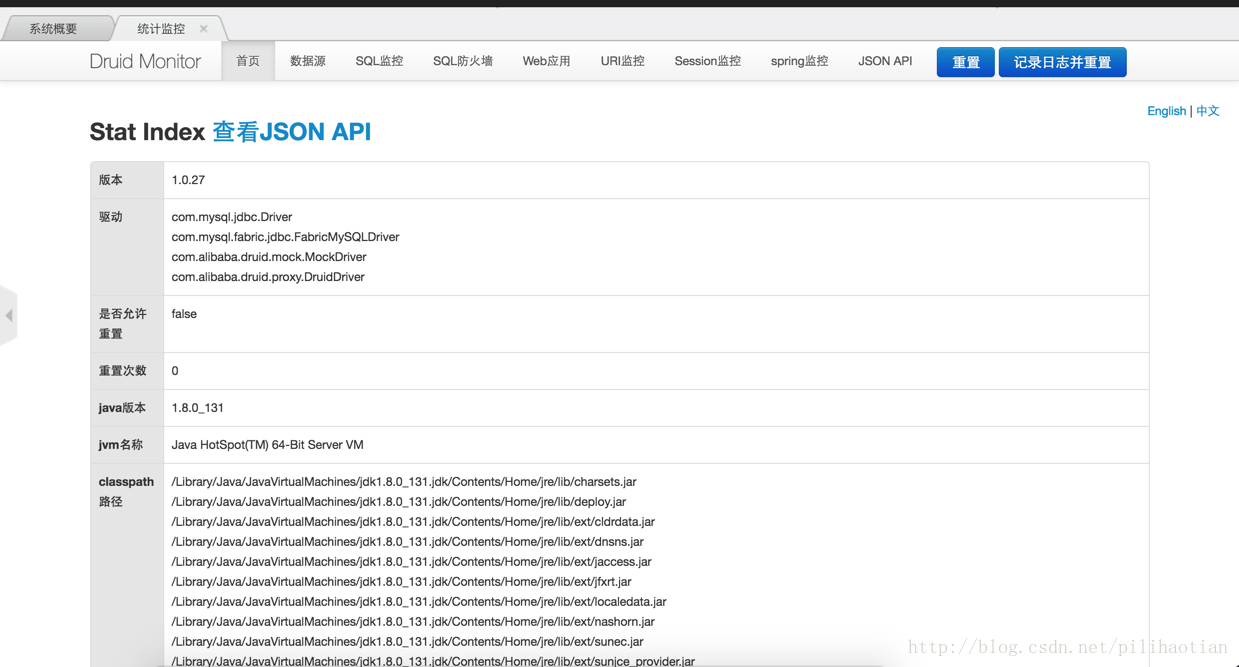
SpringBoot项目整合Druid进行统计监控的更多相关文章
- springboot项目整合druid数据库连接池
Druid连接池是阿里巴巴开源的数据库连接池项目,后来贡献给Apache开源: Druid的作用是负责分配.管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个: D ...
- SpringBoot ---yml 整合 Druid(1.1.23) 数据源
SpringBoot ---yml 整合 Druid(1.1.23) 数据源 搜了一下,网络上有在配置类写 @Bean 配置的,也有 yml 配置的. 笔者尝试过用配置类配置 @Bean 的方法,结果 ...
- Flowable与springBoot项目整合及出现的问题
Flowable与springBoot项目整合及出现的问题 单纯地将Flowable和springBoot整合,使用mysql作为数据库,整合中踩了两个坑,见文末. 在pom中添加依赖 <?xm ...
- springBoot(13)---整合Druid实现多数据源和可视化监控
SpringBoot整合Druid实现多数据源和可视化监控 先献上github代码地址:https://github.com/yudiandemingzi/springboot-manydatasou ...
- SpringBoot:整合Druid、MyBatis
目录 简介 JDBC 导入依赖 连接数据库 CRUD操作 自定义数据源 DruidDataSource Druid 简介 配置数据源 配置 Druid 数据源监控 配置 Druid web 监控 fi ...
- 170628、springboot编程之Druid数据源和监控配置一
Spring Boot默认的数据源是:org.apache.tomcat.jdbc.pool.DataSource,那么如何修改数据源呢?我已目前使用比较多的阿里数据源Druid为例,如果使用其他的数 ...
- Vue-cli3与springboot项目整合打包
一.需求 使用前后端分离编写了个小程序,前端使用的是vue-cli3创建的项目,后端使用的是springboot创建的项目,部署的时候一起打包部署,本文对一些细节部分进行了说明. 二 ...
- SpringBoot项目整合Retrofit最佳实践,这才是最优雅的HTTP客户端工具!
大家都知道okhttp是一款由square公司开源的java版本http客户端工具.实际上,square公司还开源了基于okhttp进一步封装的retrofit工具,用来支持通过接口的方式发起http ...
- spring-boot 项目整合logback
使用spring-boot项目中添加日志输出,java的日志输出一共有两个大的方案log4j/log4j2 ,logback.log4j2算是对log4j的一个升级版本. 常规做法是引入slf4j作为 ...
随机推荐
- 推荐一个yaml文件转json文件的在线工具
YAML的全称是YAML Ain't Markup Language,是一种简洁的非标记语言,以数据为中心,使用空白,缩进,和分行组织数据,从而使得表示更加简洁易读. YAML如今广泛应用于微服务开发 ...
- OpenCascade:屏闪问题。
1.在OnDraw中同时调用用V3d_View::Redaw()和 V3d_View::FitAll();可暂时解决. 2.在OnDraw中同时调用用V3d_View::Update();
- shell脚本自动部署及监控
一.shell脚本部署nginx反向代理和三个web服务 1 对反向代理服务器进行配置 #!/bin/bash #修改用户交互页面 用户输入参数执行相应的参数 #安装epel扩展包和nginx fun ...
- shell脚本,100以内的质数有哪些?
[root@localhost wyb]# cat 9zhishu.sh #!/bin/bash ` do ;j<=i-;j++)) do [ $((i%j)) -eq ] && ...
- 安装ruby开发环境
如何快速正确的安装 Ruby, Rails 运行环境 对于新入门的开发者,如何安装 Ruby, Ruby Gems 和 Rails 的运行环境可能会是个问题,本页主要介绍如何用一条靠谱的路子快速安装 ...
- 有趣的this以及apply,call,bind方法
看this指向谁,要看执行时而非定义时(箭头函数除外).函数没有绑定在对象上调用,非'strict'模式下,this指向window,否则为undefined 改变this指向的方法 1. apply ...
- [九省联考2018] IIIDX 线段树+贪心
题目: 给出 k 和 n 个数,构造一个序列使得 d[i]>=d[i/k] ,并且字典序最大. 分析: 听说,当年省选的时候,这道题挡住了大批的高手,看上去十分简单,实际上那道弯段时间内是转不过 ...
- (61)zabbix网络发现规则配置实战/详解
开始配置.首先,我们需要定义发现规则,用于扫描.步骤如下 第一步 Configuration >>Discovery>>Create rule,编辑网络发现规则 如上配置,za ...
- (转)Duplicate Symbol链接错的原因总结和解决方法
duplicate symbol是一种常见的链接错误,不像编译错误那样可以直接定位到问题的所在.但是经过一段时间的总结,发现这种错误总是有一些规律可以找的.例如,我们有如下的最简单的两个类代码: // ...
- errno的定义
./include/asm-generic/errno-base.h -->包含errno=~ ./arch/arm/include/asm/errno.h -->包含/include/a ...