Java高并发--CPU多级缓存与Java内存模型
Java高并发--CPU多级缓存与Java内存模型
主要是学习慕课网实战视频《Java并发编程入门与高并发面试》的笔记
CPU多级缓存
为什么需要CPU缓存:CPU的频率太快,以至于主存跟不上,这样在处理器时钟周期内,CPU常常需要等待主存,浪费了资源。所有缓存的出现是为了缓解CPU和主存之间速度不匹配的问题——将运算所需数据复制到缓存中,使得运算能快速进行;当运算结束后再将缓存同步回内存中,这样处理器无需等待缓慢的内存读写。
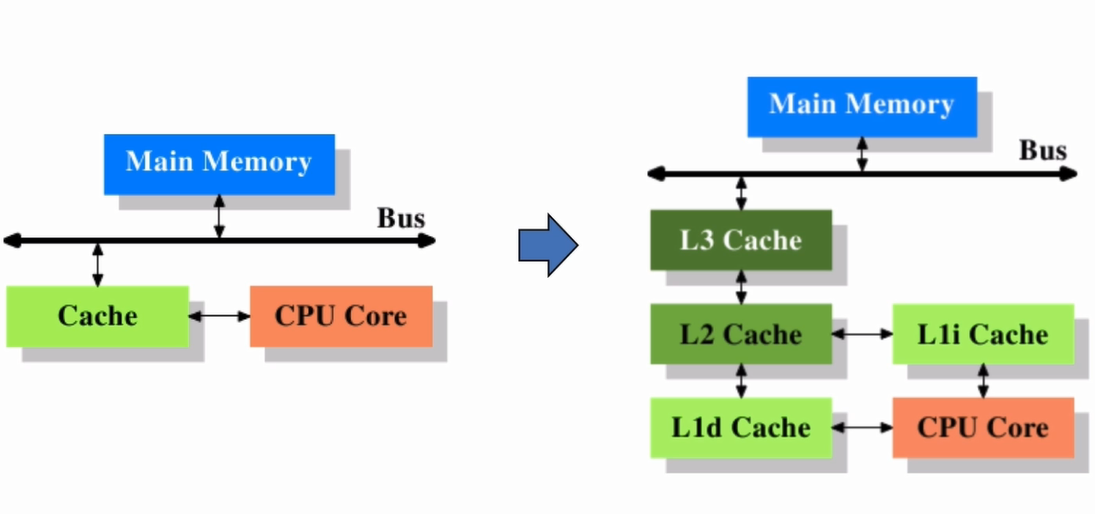
缓存并非存储了所有的数据,那么它存在的意义是什么?
- 时间局部性:如果某个数据被访问,那么它在不久的将来有可能被再次访问
- 空间局部性:如果某个数据被访问,那么与它相邻的数据很快可能被访问
Java内存模型
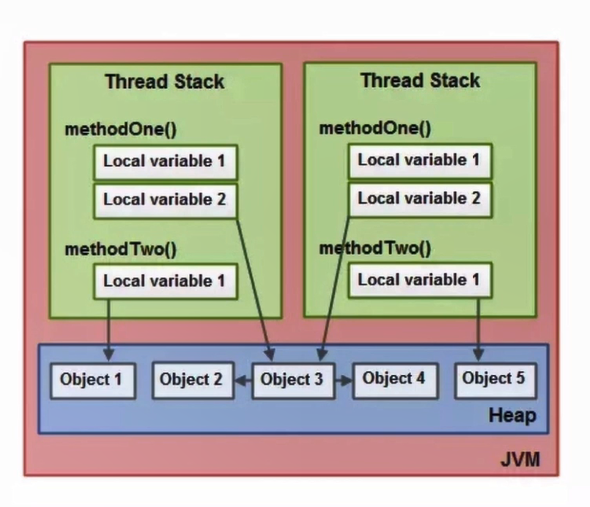
下图中是JVM中堆和栈的关系,在不同的线程中,可能有多个变量,它们指向的是堆上的同一个对象,这些变量都是该对象的“私有拷贝”。私有表示仅在当前线程可访问,拷贝是说这是该对象的一个引用。
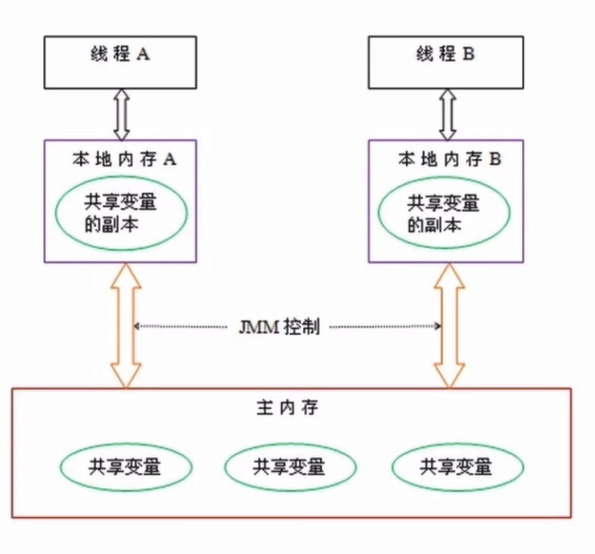
线程A和线程B之间如果要通信的话,必须经历以下两个步骤:
- 线程A将本地内存(工作内存)中的变量刷新到主内存中
- 主内存将变量复制到本地内存B中,使得线程B在读取变量时更快
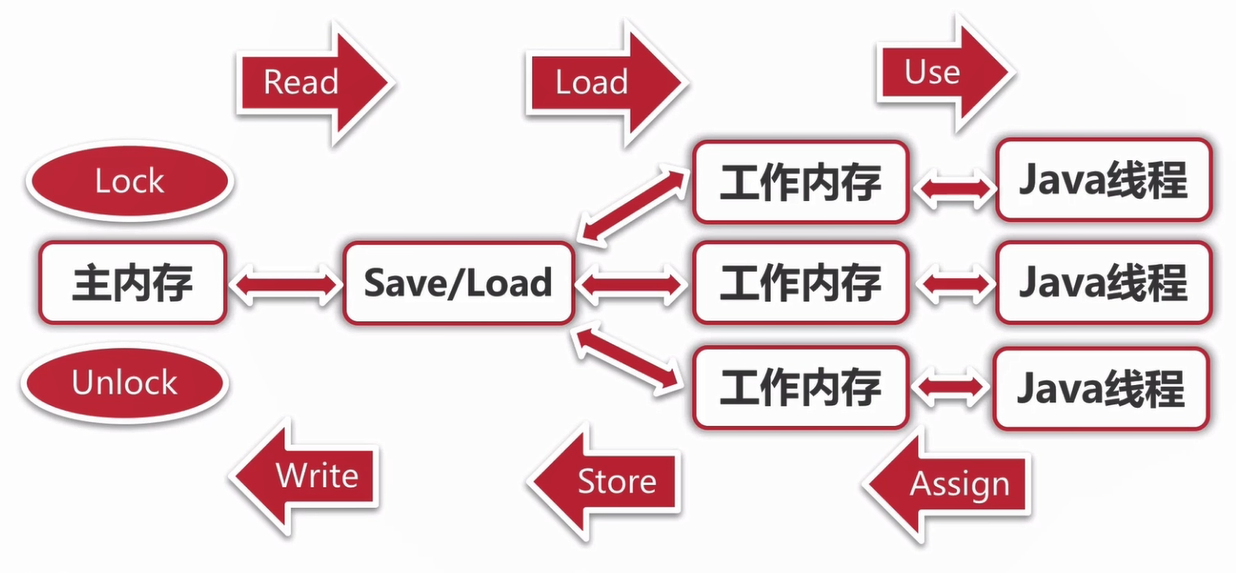
Java内存模型中,所有的变量都存储在主内存中,每条线程还有自己的工作内存(与高速缓存类比),线程对变量的所有操作都必须在工作内存中进行,不能直接读写主内存中的变量;不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需通过主内存完成。
如果将Java内存模型和Java堆、栈比较,主内存对应Java堆中的对象实例部分,工作内存对应虚拟机栈中的部分。
主内存和工作内存之间需要交互,Java内存模型中有8种原子操作:
- lock:作用于主内存变量,将其标识为线程独占。
- unlock:作用于主内存变量,将其从锁定状态释放,释放后才可被其他线程锁定。
- read:作用于主内存的变量,将一个变量从主内存中传输到工作内存中,以便随后的load动作使用。
- load:作用于工作内存中的变量,把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use:作用于工作内存的变量,把工作内存中的一个变量的值传递给执行引擎,当虚拟机需要使用到变量的值的字节码指令时会执行这个操作。
- assign:作用于工作内存的变量,把一个从执行引擎接受到的值赋给工作内存中的变量。当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store:作用于工作内存中的变量,把工作内存中的一个变量的值传送到主内存中,以便之后write操作使用。
- write:作用于主内存中的变量,把store操作从工作内存中得到的变量值放入主内存的变量中。
如果一个变量从主内存复制到工作内存,必须先执行read然后执行load操作(read和load之间允许插入其他操作,只要保证这个顺序即可);如果要把变量从工作内存同步回主内存中,需要先执行store操作然后执行write操作(store和write之间允许插入其他操作,只要保证这个顺序即可)。
最后来看一个线程不安全的例子
package com.shy.concurrency;
import com.shy.concurrency.annotations.NotThreadSafe;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* @author Haiyu
* @date 2018/12/16 16:08
*/
@Slf4j
@NotThreadSafe
public class ConcurrencyTest {
// 请求总数
public static int requestTotal = 5000;
// 并发量,同时进入临界区的线程数量
public static int concurrentTotal = 20;
// 计数器
public static int count = 0;
@NotThreadSafe
private static void add() {
count++;
}
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newCachedThreadPool();
// 信号量,控制并发数
final Semaphore semaphore = new Semaphore(concurrentTotal);
// 倒计数器,在这里用来阻塞主线程直到计数器为0
final CountDownLatch countDownLatch = new CountDownLatch(requestTotal);
// requestTotal次请求,每一次请求自增1,按理说最后count的值是requestTotal
// 但是在并发下,多个线程同时执行了add()使得多次自增值只增加了1,导致最后的结果比requestTotal小
for (int i = 0; i < requestTotal; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
// 最多可同时concurrentTotal个线程同时执行
add();
semaphore.release();
} catch (InterruptedException e) {
log.error("exception", e);
}
// 每自增一次,计数器减1
countDownLatch.countDown();
});
}
// 主线程在countdownLatch上等待,等计数器为0后才能执行
countDownLatch.await();
log.info("count:{}", count);
executorService.shutdown();
}
}
总共发起5000次请求(5000个线程),每次请求对count变量做自增操作。显然在并发下,主线程等5000个线程执行完毕后count一般是小于5000的。原因如下:
以两个线程为例,它们在同一时刻从主内存中读取count的值并装载到各自的工作内存中,此时count的值是一样的,假设都是10。此时线程A先自增,将自增后的值更新到工作内存,最后刷回主内存,count变成了11;而在线程B也进行同样的自增操作,注意之前线程B已经读取过count的值了,此时在B的工作内存中的count还是等于10的,接着B也更新count,最后刷回主内存中,count变成11。也就是说明明执行了两次自增,最后count只增大了1。因此在并发下,多次add可能只会有一次自增。
semaphore信号量用于控制并发量,即同时进入临界区的操作同一个共享资源的线程数。
semaphore.acquire(); // 可以认为是获得锁
// other code
semaphore.release(); // 可以认为是释放了锁semaphore.acquire()和semaphore.release()之间的代码可以认为是临界区,这里指定了可以同时20个线程进入临界区,换种说法就是并发量是20。
如果将semaphore允许的并发量改成1,那么就相当于任意时刻只能有一个线程执行add操作,5000个线程井然有序的按照先后顺序执行add,不存在同时执行的情况,这种情况下最后的结果总是5000,某种意义上变成了串行。
解决上面的线程不安全问题,除了可以将semaphore的并发量控制为1;还可以使用重入锁,synchronized关键字,原子变量AtomicInteger等。
Java高并发--CPU多级缓存与Java内存模型的更多相关文章
- java高并发实战(三)——Java内存模型和线程安全
转自:https://blog.csdn.net/gududedabai/article/details/80816488
- Java高并发系列——检视阅读
Java高并发系列--检视阅读 参考 java高并发系列 liaoxuefeng Java教程 CompletableFuture AQS原理没讲,需要找资料补充. JUC中常见的集合原来没讲,比如C ...
- Java高并发--缓存
Java高并发--缓存 主要是学习慕课网实战视频<Java并发编程入门与高并发面试>的笔记 在下图中每一个部分都可以使用缓存的技术. 缓存的特征 缓存命中:直接通过缓存获取到数据 命中率: ...
- JAVA系统架构高并发解决方案 分布式缓存 分布式事务解决方案
JAVA系统架构高并发解决方案 分布式缓存 分布式事务解决方案
- 并发与高并发(三)-CPU多级缓存の乱序执行优化
一.CPU多级缓存-乱序执行优化 处理器或编译器为提高运算速度而做出违背代码原有顺序的优化. 重排序遵循原则as-if-serial as-if-serial语义:不管怎么重排序(编译器和处理器为了提 ...
- 并发编程二、CPU多级缓存架构与MESI协议的诞生
前言: 文章内容:线程与进程.线程生命周期.线程中断.线程常见问题总结 本文章内容来源于笔者学习笔记,内容可能与相关书籍内容重合 偏向于知识核心总结,非零基础学习文章,可用于知识的体系建立,核心内容 ...
- Java高并发--原子性可见性有序性
Java高并发--原子性可见性有序性 主要是学习慕课网实战视频<Java并发编程入门与高并发面试>的笔记 原子性:指一个操作不可中断,一个线程一旦开始,直到执行完成都不会被其他线程干扰.换 ...
- java高并发编程(一)
读马士兵java高并发编程,引用他的代码,做个记录. 一.分析下面程序输出: /** * 分析一下这个程序的输出 * @author mashibing */ package yxxy.c_005; ...
- 《实战Java高并发程序设计》读书笔记
文章目录 第二章 Java并行程序基础 2.1 线程的基本操作 2.1.1 线程中断 2.1.2 等待(wait)和通知(notify) 2.1.3 等待线程结束(join)和谦让(yield) 2. ...
随机推荐
- mysql5.6版本的优化
1. 目标 l 了解什么是优化 l 掌握优化查询的方法 l 掌握优化数据库结构的方法 l 掌握优化MySQL服务器的方法 2. 什么是优化? l 合理安排资源.调整系统参数使MySQL运行更快.更节省 ...
- 了不起的WebRTC:生态日趋完善,或将实时音视频技术白菜化
本文原文由声网WebRTC技术专家毛玉杰分享. 1.前言 有人说 2017 年是 WebRTC 的转折之年,2018 年将是 WebRTC 的爆发之年,这并非没有根据.就在去年(2017年),WebR ...
- 第68节:Java中的MYSQL运用从小白到大牛
第68节:Java中的MYSQL运用从小白到大牛 前言 学习java必备要求,学会运用!!! 常见关系化数据库 BootStrap是轻量级开发响应式页面的框架,全局css组件,js插件.栅格系统是将页 ...
- 第33节:Java面向对象中的异常
Java中的异常和错误 Java中的异常机制,更好地提升程序的健壮性 throwable为顶级,Error和Exception Error:虚拟机错误,内存溢出,线程死锁 Exception:Runt ...
- 向github提交代码不用输入帐号密码
解决方案:方案一: 在你的用户目录下新建一个文本文件.git-credentials Windows:C:/Users/username Mac OS X: /Users/username Linux ...
- GDB dump mem example和命令
使用方法: You can use the commands dump, append, and restore to copy data between target memory and a fi ...
- pycharm中配置启动Django项目
1.先打开mange.py,然后再运行,会提示一堆东西,表示没有配置参数.在pycharm中点击edit configurations 编辑配置参数. 2.点开之后弹出如下对话框,在scrip par ...
- Jade —— 源于 Node.js 的 HTML 模板引擎
2013-12-11 发布 Jade —— 源于 Node.js 的 HTML 模板引擎 开源项目介绍 web 模板引擎 node.js jade 207.8k 次阅读 · 读完需要 69 分钟 ...
- 使用FormData格式在前后端传递数据
为什么一定要使用formdata格式……很大原因是因为当时我犯蠢…… 前端肯定是JS了,具体不写了,使用Postman测试,后端语言是Java,框架Spring Boot,使用IntelliJ IDE ...
- MapReduce中的Join
一. MR中的join的两种方式: 1.reduce side join(面试题) reduce side join是一种最简单的join方式,其主要思想如下: 在map阶段,map函数同时读取两个文 ...