Solr7.1--- 高亮查询
由于测试数据比较少,昨天用Java爬了简书的几百篇文章,唉,又特么两点多睡的。如果你需要这些测试文件GitHub。
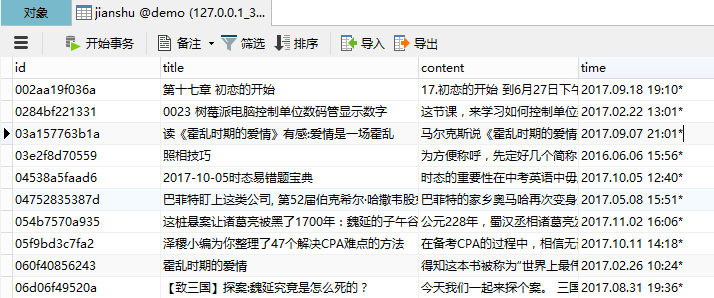
如果你看过我前面的文章,直接打开db-data-config.xml文件,添加一个entity
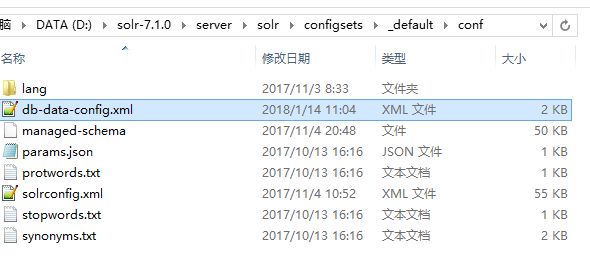
<entity name="jianshu" pk="a_id"
query="select * from jianshu"
deltaImportQuery="SELECT * FROM jianshu where a_id='${dataimporter.delta.a_id}'">
<field column="A_ID" name="aId" />
<field column="A_TITLE" name="aTitle" />
<field column="A_CONTENT" name="aContent" />
<field column="A_TIME" name="aTime" />
</entity>
效果:
启动solr集群,然后添加一个名字为jianshu的Collection
D:\solr-7.1.>.\bin\solr start -c -p -s example/cloud/node1/solr
Waiting up to to see Solr running on port
Started Solr server on port . Happy searching! D:\solr-7.1.>.\bin\solr start -c -p -s example/cloud/node2/solr -z localho
st:
Waiting up to to see Solr running on port
Started Solr server on port . Happy searching! D:\solr-7.1.>.\bin\solr create -c jianshu -s -rf
WARNING: Using _default configset. Data driven schema functionality is enabled b
y default, which is
NOT RECOMMENDED for production use.
To turn it off:
curl http://localhost:8983/solr/jianshu/config -d '{"set-user-proper
ty": {"update.autoCreateFields":"false"}}'
Created collection 'jianshu' with shard(s), replica(s) with config-set 'jian
shu'
打开控制台:多了一个jianshu的集合
选择jianshu

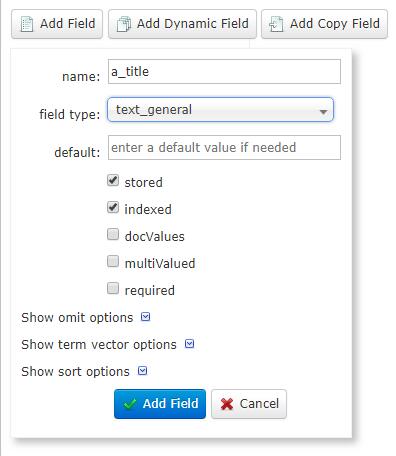
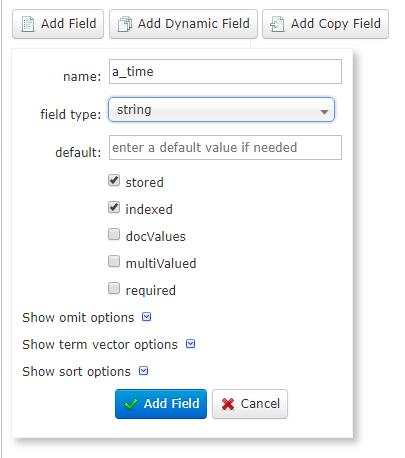
点击Schema,添加字段


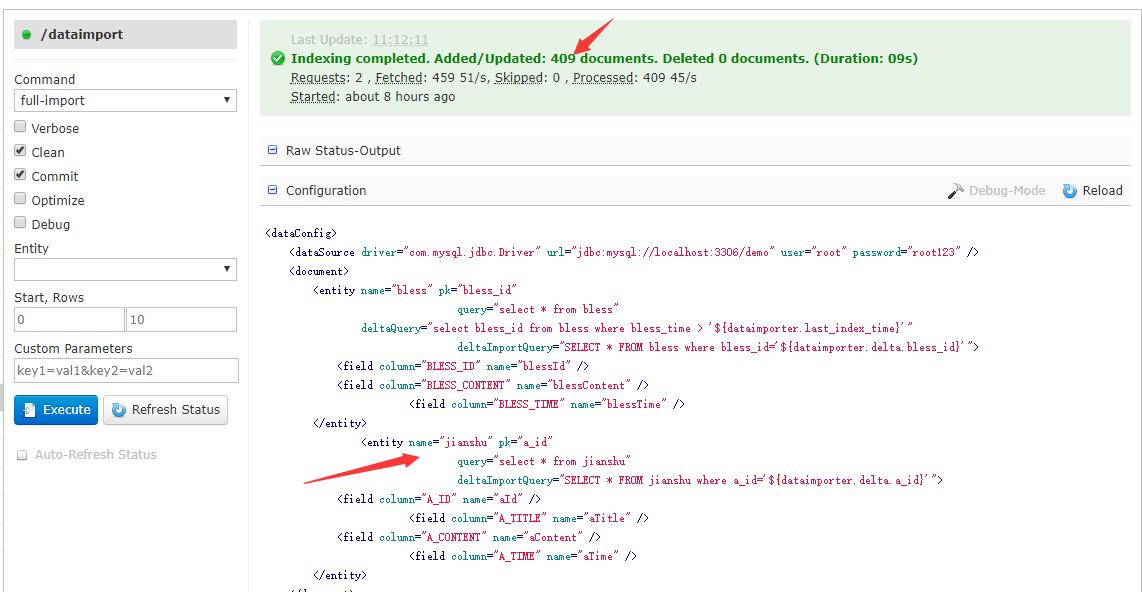
完毕之后,点击DataImport
点击Query,看看数据是否到位

进行高亮查询--控制台操作
q:查询带有(爱情)的标题和内容

开启高亮,涉及的字段为标题和内容
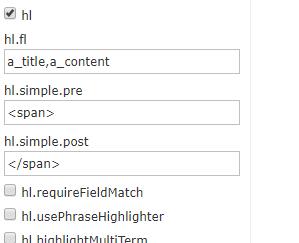
看高亮结果

高亮查询--Java
实际中大多是用solrJ的API来完成。
// 单机--core,集群--Collection
// 指向特定核心或集合的路径(例如,http://hostname:8983/solr/core1)的URL 。当在基本URL中指定核心或集合时,使用该客户端的后续请求不需要重新指定受影响的集合。但是,客户端仅限于向该核心/集合发送请求,而不能将请求发送给其他任何人。
// 指向根Solr路径的URL(例如,http://hostname:8983/solr)。如果在基本URL中未指定核心或集合,则可以向任何核心/集合发出请求,但是必须在所有请求上指定受影响的核心/集合。 public static SolrClient getClient(){
final String solrUrl = "http://localhost:8983/solr";
// final String solrUrl = "http://localhost:8983/solr/bless";
return new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
}
上面是用来获取客户端的,下面是高亮查询
/* 高亮样式
.search-key{
color: #d60e3c;
font-size: 18px;
font-weight: 600;
}
*/
public static void queryOfHighlight() throws SolrServerException, IOException{
final SolrClient client = getClient(); final SolrQuery query = new SolrQuery("a_title:爱情 a_content:爱情");
query.addField("a_id");
query.addField("a_title");
query.addField("a_content");
query.addField("a_time");
query.setHighlight(true)
.setHighlightSimplePre("<span class='search-key'>")
.setHighlightSimplePost("</span>");
query.setParam("hl.fl", "a_title,a_content"); final QueryResponse response = client.query("jianshu", query);
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting(); // 高亮查询的结果集
Set<String> set = highlighting.keySet();
for (String key : set) {
System.out.println("++" + key); // id
Map<String, List<String>> map = highlighting.get(key); // id对应的查询结果,可能有多个字段,所以是map结构
Set<String> set2 = map.keySet(); // 字段名集合
// 遍历字段
for (String key2 : set2) {
System.out.println("--" + key2); // 字段名
List<String> list = map.get(key2); // 字段对应的值,因为分词了,所以是一个String列表
for (String s : list) {
System.out.print(s + " "); // 输出高亮的文本
}
System.out.println();
}
} // 这段代码获取的是不加处理的结构
// SolrDocumentList results = response.getResults();
// System.out.println("查询到的:" + results.getNumFound());
// for (SolrDocument sd : results) {
// Collection<String> names = sd.getFieldNames();
// for (String s : names) {
// Object value = sd.getFieldValue(s);
// System.out.println("名字?:" + s + ",值:" + value);
// }
// } }
运行结果:
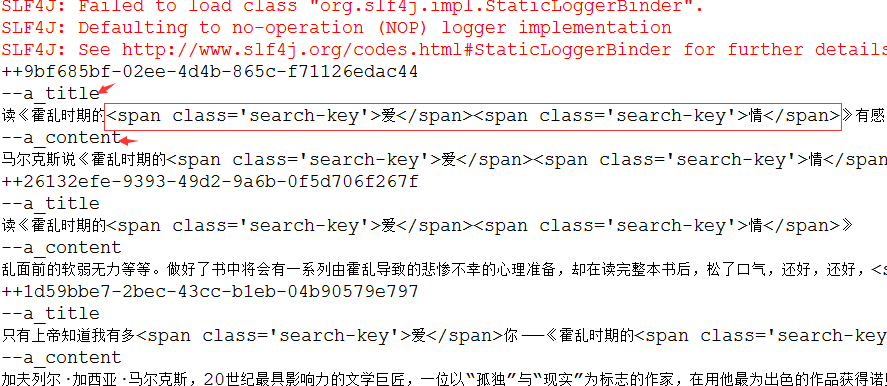
如果放在前台大概是这样的:

细心会发现,通过高亮获得的文本只是一部分,想一下也是情理之中。当我们使用搜索功能的时候,每条信息显示的只是摘要。

Solr7.1--- 高亮查询的更多相关文章
- ElasticSearch(十三):Spring Data ElasticSearch 的使用(三)——NativeSearchQuery 高亮查询
在Elasticsearch的实际应用中,经常需要将匹配到的结果字符进行高亮显示,此处采取NativeSearchQuery原生查询的方法,实现查询结果的高亮显示. /** * 高亮查询 */ @Te ...
- es的查询、排序查询、分页查询、布尔查询、查询结果过滤、高亮查询、聚合函数、python操作es
今日内容概要 es的查询 Elasticsearch之排序查询 Elasticsearch之分页查询 Elasticsearch之布尔查询 Elasticsearch之查询结果过滤 Elasticse ...
- Lucene的多域查询、结果中查询、查询结果分页、高亮查询结果和结果评分
1.针对多个域的一次性查询 1.1.三种方案 使用lucene构造搜索引擎的时候,如果要针对多个域进行一次性查询,一般来说有三种方法: 第一种实现方法是创建多值的全包含域的文本进行索引 ...
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- Elasticsearch实现复合查询,高亮结果等技巧
一.Es的配置 实现es的全文检索功能的第一步,首先从与es进行连接开始,这里我使用的是es的5.x java api语法. public TransportClient esClient() thr ...
- Presto 来自Facebook的开源分布式查询引擎
Presto是一个分布式SQL查询引擎, 它被设计为用来专门进行高速.实时的数据分析.它支持标准的ANSI SQL,包括复杂查询.聚合(aggregation).连接(join)和窗口函数(windo ...
- Lucene实现索引和查询
0引言 随着万维网的发展和大数据时代的到来,每天都有大量的数字化信息在生产.存储.传递和转化,如何从大量的信息中以一定的方式找到满足自己需求的信息,使之有序化并加以利用成为一大难题.全文检索技术是现如 ...
- Solr 08 - 在Solr Web管理页面中查询索引数据 (Solr中各类查询参数的使用方法)
目录 1 Solr管理页面的查询入口 2 Solr查询输入框简介 3 Solr管理页面的查询方案 1 Solr管理页面的查询入口 选中需要查询的SolrCore, 然后在菜单栏选择[Query]: 2 ...
- es crul查询(一)
C:\Users\Administrator>elasticdump --input=D:\test --output=http://localhost:9200/logs_apipki_201 ...
随机推荐
- Prism框架研究(二)
首先在介绍本节内容之前,首先来看看官方文档来如何描述Prism 应用的初始化吧!A Prism application requires registration and configuration ...
- 使用Guava cache构建本地缓存
前言 最近在一个项目中需要用到本地缓存,在网上调研后,发现谷歌的Guva提供的cache模块非常的不错.简单易上手的api:灵活强大的功能,再加上谷歌这块金字招牌,让我毫不犹豫的选择了它.仅以此博客记 ...
- python绝对路径和相对路径
转自https://blog.csdn.net/databatman/article/details/49453953 下面的路径介绍针对windows,其他平台的暂时不是很了解. 在编写的py文件中 ...
- powerdesigner 16.5 不允许有扩展属性,或对象不存在
创建完之后这边会出现 选择刚创建的用户 这样就可以了
- github---无命令可视化界面操作
最近工作需要,研究了一下git,这个东西挺实用,给我的感觉并不是那么简单使用,我认为还可以再深入的研究一下,挺好玩的~ 说一下我的学习路线: 1.先看的廖老师的博客:https://www.liaox ...
- org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.mybatis.spring.mapper.MapperScannerConfigurer#0'
七月 05, 2018 10:26:54 上午 org.apache.tomcat.util.digester.SetPropertiesRule begin警告: [SetPropertiesRul ...
- 三星 SCX-4521NS 网络打印机 在XP 下 强行 设置 安装
添加打印机加上之后,图标是半虚的,状态脱机,网上找了很多方法都不好使. 包括官方的:http://www.samsung.com/cn/support/skp/faq/442292 然后死马当活马医, ...
- Django-urls路由系统
Django的路由系统 Django 1.11版本 URLConf官方文档 URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表. ...
- Windows server 2012 卸载iis 黑屏
转载:https://jingyan.baidu.com/article/ff42efa9fb6f16c19e2202dc.html 1 按 ctrl+alt+end 键,新建运行任务 ,输入cmd ...
- 为何在新线程中使用注解获取不到Spring管理的Bean
新建的线程类NewThread,在这个类中国使用Spring的注解获取Service,为null 网上已有这种问题的解决方案,但是为何在新线程中使用注解获取不到Spring管理的Bean? 问了老大, ...