Trident继承kafka
1.Kafka涉及的类
上一个类是不透明事务
后一个是完全事务
2.启动服务
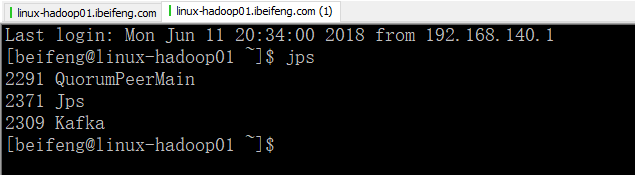
3..驱动类
重要的地方是修改了两个部分:
1.数据的来源是kafka
2.第二个是字段的Fields是str
package com.jun.tridentWithKafka; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.kafka.BrokerHosts;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import storm.kafka.trident.OpaqueTridentKafkaSpout;
import storm.kafka.trident.TridentKafkaConfig;
import storm.trident.Stream;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.MemoryMapState; public class TridentWithKafka {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
TridentTopology tridentTopology=new TridentTopology();
//使用Kafka中的数据
BrokerHosts hosts = new ZkHosts("linux-hadoop01.ibeifeng.com:2181");
String topic = "nginxlog";
TridentKafkaConfig conf = new TridentKafkaConfig(hosts, topic); conf.scheme = new SchemeAsMultiScheme(new StringScheme());
conf.forceFromStart = true; OpaqueTridentKafkaSpout spout = new OpaqueTridentKafkaSpout(conf); //流处理
Stream stream=tridentTopology.newStream("orderAnalyse",spout)
//过滤
.each(new Fields("str"),new ValidLogFilter())
//解析
.each(new Fields("str"), new LogParserFunction(),new Fields("orderId","orderTime","orderAmtStr","memberId"))
//投影
.project(new Fields("orderId","orderTime","orderAmtStr","memberId"))
//时间解析
.each(new Fields("orderTime"),new DateTransFormerFunction(),new Fields("day","hour","minter"))
;
//分流
//1.基于minter统计订单数量,分组统计
TridentState state=stream.groupBy(new Fields("minter"))
//全局聚合,使用内存存储状态信息
.persistentAggregate(new MemoryMapState.Factory(),new Count(),new Fields("orderNumByMinter"));
// state.newValuesStream().each(new Fields("minter","orderNumByMinter"),new PrintFilter()); //2.另一个流,基于分钟的订单金额,局部聚合
Stream partitionStream=stream.each(new Fields("orderAmtStr"),new TransforAmtToDoubleFunction(),new Fields("orderAmt"))
.groupBy(new Fields("minter"))
//局部聚合
.chainedAgg() //聚合链
.partitionAggregate(new Fields("orderAmt"),new LocalSum(),new Fields("orderAmtSumOfLocal"))
.chainEnd(); //聚合链
// partitionStream.each(new Fields("minter","orderAmtSumOfLocal"),new PrintFilter());
//做一次全局聚合
TridentState partitionState=partitionStream.groupBy(new Fields("minter"))
//全局聚合
.persistentAggregate(new MemoryMapState.Factory(),new Fields("orderAmtSumOfLocal"),new Sum(),new Fields("totalOrderAmt"));
partitionState.newValuesStream().each(new Fields("minter","totalOrderAmt"),new PrintFilter()); //提交
Config config=new Config();
if(args==null || args.length<=0){
LocalCluster localCluster=new LocalCluster();
localCluster.submitTopology("tridentDemo",config,tridentTopology.build());
}else {
config.setNumWorkers(2);
StormSubmitter.submitTopology(args[0],config,tridentTopology.build());
}
}
}
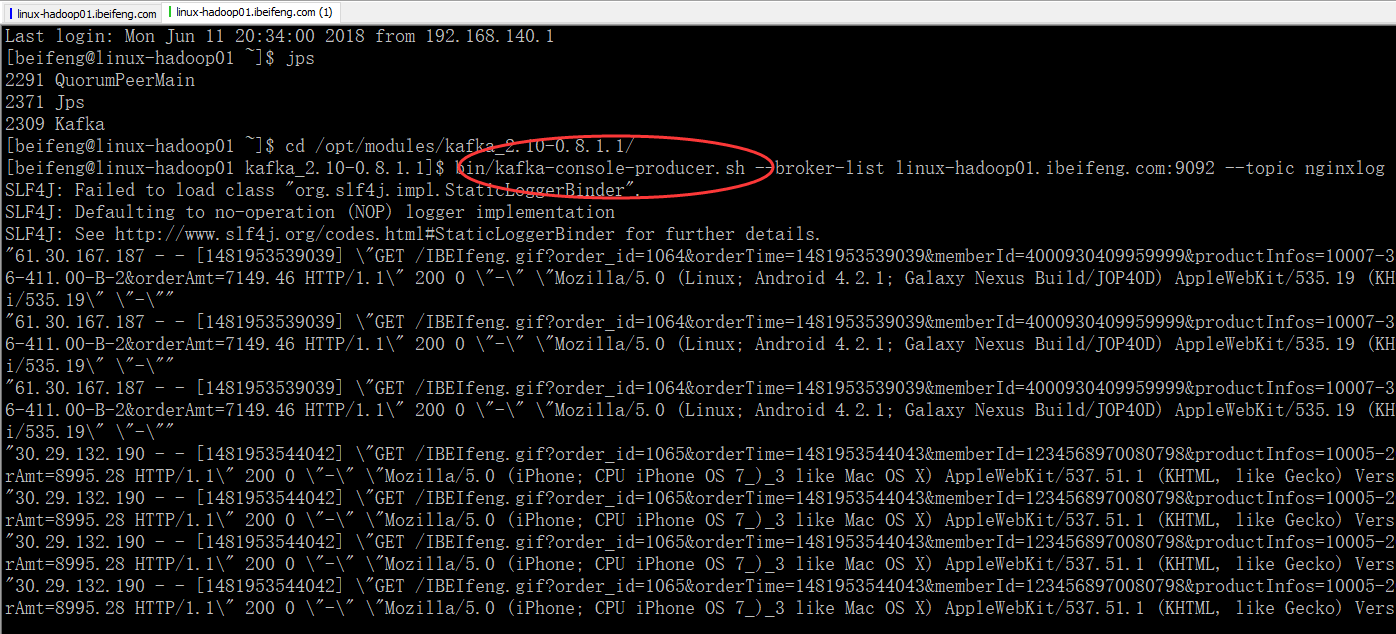
4.输入数据
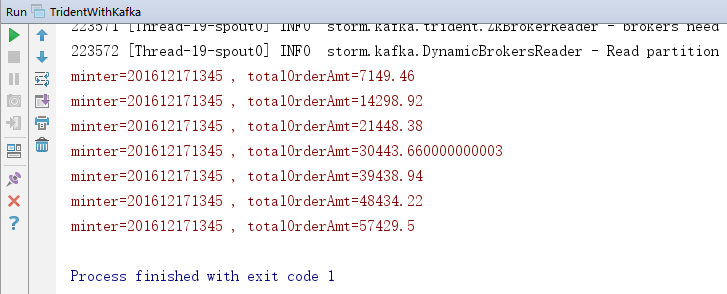
5.控制台
Trident继承kafka的更多相关文章
- Trident整合Kafka
首先编写一个打印函数KafkaPrintFunction import org.apache.storm.trident.operation.BaseFunction; import org.apac ...
- Java操作Kafka执行不成功的解决方法,Kafka Broker Advertised.Listeners属性的设置
创建Spring Boot项目继承Kafka,向Kafka发送消息始终不成功.具体项目配置如下: <?xml version="1.0" encoding="UTF ...
- storm-kafka教程
一.原理介绍 本文内容参考:https://github.com/apache/storm/tree/master/external/storm-kafka#brokerhosts (一)使用st ...
- storm-kafka编程指南
目录 storm-kafka编程指南 一.原理及关键步骤介绍 (一)使用storm-kafka的关键步骤 1.创建ZkHosts 2.创建KafkaConfig 3.设置MultiScheme 4.创 ...
- Apache Storm
作者:jiangzz 电话:15652034180 微信:jiangzz_wx 微信公众账号:jiangzz_wy 背景介绍 流计算:将大规模流动数据在不断变化的运动过程中实现数据的实时分析,捕捉到可 ...
- 认识Linux文件系统的架构
本文主要研究一下storm的OpaquePartitionedTridentSpoutExecutor TridentTopology.newStream storm-core-1.2.2-sourc ...
- Storm集成Kafka的Trident实现
原本打算将storm直接与flume直连,发现相应组件支持比较弱,topology任务对应的supervisor也不一定在哪个节点上,只能采用统一的分布式消息服务Kafka. 原本打算将结构设 ...
- 学好Spark/Kafka必须要掌握的Scala技术点(二)类、单例/伴生对象、继承和trait,模式匹配、样例类(case class)
3. 类.对象.继承和trait 3.1 类 3.1.1 类的定义 Scala中,可以在类中定义类.以在函数中定义函数.可以在类中定义object:可以在函数中定义类,类成员的缺省访问级别是:publ ...
- Flume+Kafka+Storm+Redis 大数据在线实时分析
1.实时处理框架 即从上面的架构中我们可以看出,其由下面的几部分构成: Flume集群 Kafka集群 Storm集群 从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间 ...
随机推荐
- 接口签名进行key排序,并MD5加密
import org.apache.commons.codec.digest.DigestUtils; import java.io.UnsupportedEncodingException; imp ...
- C#一元二次方程
- swift 实践- 09 -- UIImageVIew
import UIKit class ViewController: UIViewController { override func viewDidLoad() { super.viewDidLoa ...
- Socket通讯成功案例
Socket通讯案例 #region 服务端 //int port = 1234; //string host = "127.0.0.1"; //IPAddress ip = IP ...
- nginx代理跨域(mac)
首先找到nginx.conf文件,修改并添加如下配置 html 文件 <!DOCTYPE html> <html lang="en"> <head&g ...
- mysql视图的作用
测试表:user有id,name,age,sex字段 测试表:goods有id,name,price字段 测试表:ug有id,userid,goodsid字段 视图的作用实在是太强大了,以下是我体验过 ...
- Mybaits动态Sql
什么是动态SQL? MyBatis的强大之处便是它的动态SQL,如果你使用JDBC那么在根据不同条件查询时,拼接SQL语句是多么的痛苦. 比如查询一个学生信息,可以根据学生的姓名,性别,班级,年龄,学 ...
- Python中的构造方法
在Java等语言中都有构造方法[进行对象的创建及初始化]这个东东,示例代码如下: public class Student { //成员变量 private String name; private ...
- Wowza 相关
下载: 1.https://www.wowza.com/pricing/installer 安装: https://www.wowza.com/docs/how-to-install-and-conf ...
- 沈阳润才教育CRM
一.CRM初始 CRM,客户关系管理系统(Customer Relationship Management).企业用CRM技术来管理与客户之间的关系,以求提升企业成功的管理方式,其目的是协助企业管理销 ...