yarn查询/cluster/nodes均返回localhost
背景:
1、已禁用ipv6。
2、所有节点的/etc/hosts正确配置,任务在ResourceManager提交。
3、yarn-site.xml中指定了
yarn.resourcemanager.hostname=Master
yarn.nodemanager.aux-services=mapreduce_shuffle
并在各NodeManager配置了相应的yarn.nodemanager.hostname 4、mapred-site.xml中指定了mapreduce.framework.name=yarn
现象:
提交MR任务的连接拒绝的堆栈,其中连接的container地址为localhost,与实际需要的不一致。
| ser: | root |
|---|---|
| Name: | Bigdata-Hadoop-1.0-SNAPSHOT.jar |
| Application Type: | MAPREDUCE |
| Application Tags: | |
| YarnApplicationState: | FAILED |
| Queue: | default |
| FinalStatus Reported by AM: | FAILED |
| Started: | Thu Nov 22 21:59:31 +0800 2018 |
| Elapsed: | 6mins, 1sec |
| Tracking URL: | History |
| Diagnostics: |
Application application_1542889591013_0006 failed 2 times due to Error launching appattempt_1542889591013_0006_000002. Got exception: java.net.ConnectException: Call From localhost/127.0.0.1 to localhost:33070 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.GeneratedConstructorAccessor59.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:732)
at org.apache.hadoop.ipc.Client.call(Client.java:1480)
at org.apache.hadoop.ipc.Client.call(Client.java:1413)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy83.startContainers(Unknown Source)
at org.apache.hadoop.yarn.api.impl.pb.client.ContainerManagementProtocolPBClientImpl.startContainers(ContainerManagementProtocolPBClientImpl.java:96)
at sun.reflect.GeneratedMethodAccessor19.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy84.startContainers(Unknown Source)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.launch(AMLauncher.java:119)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.run(AMLauncher.java:250)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:495)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:615)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:713)
at org.apache.hadoop.ipc.Client$Connection.access$2900(Client.java:376)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1529)
at org.apache.hadoop.ipc.Client.call(Client.java:1452)
... 15 more
. Failing the application.
|
同时在底部的两次尝试时,driver地址也为localhost

通过查询发现yarn返回的集群节点信息中,所有的NodeManager地址均为localhost。
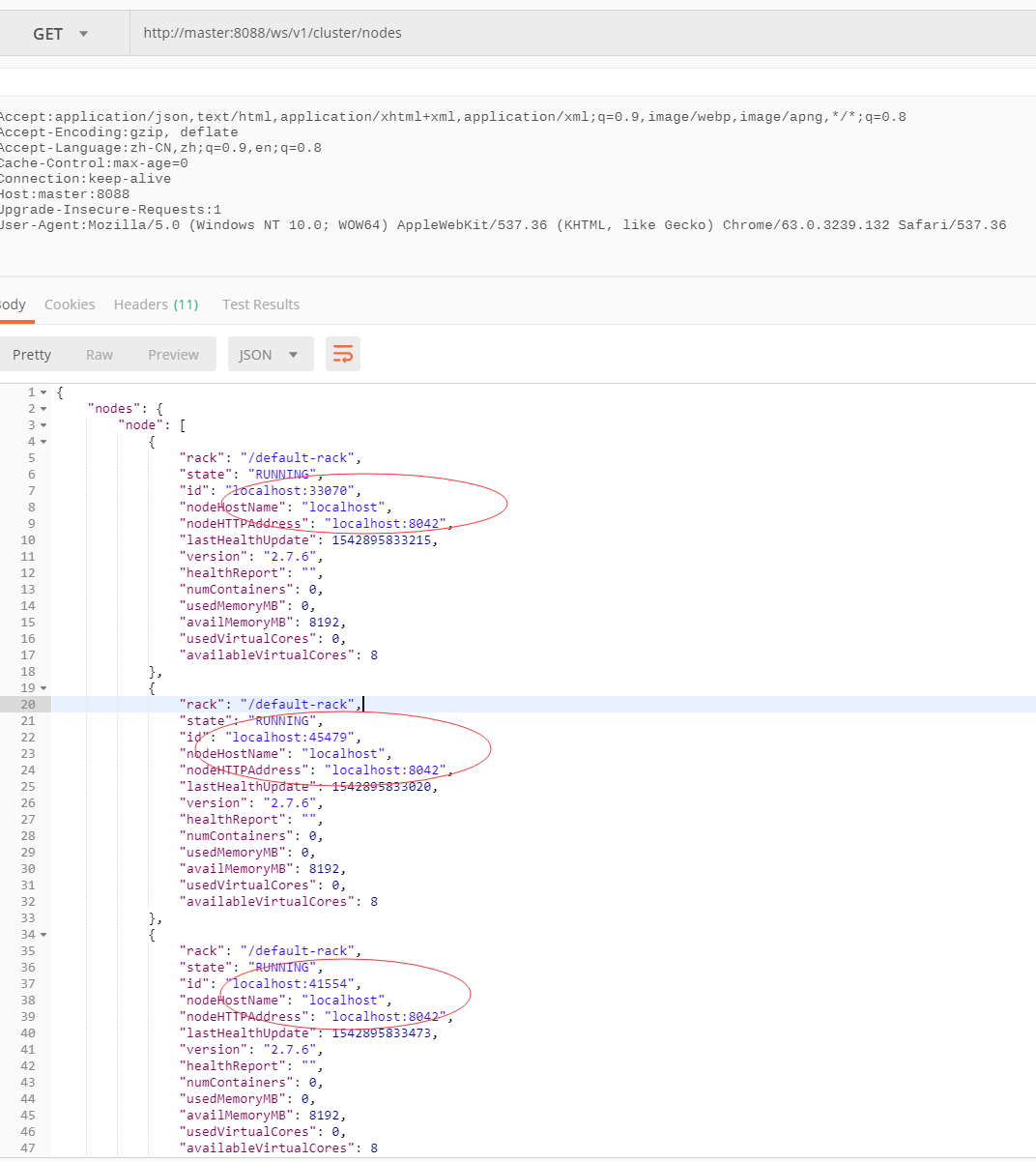
以上均证实通过yarn查询到的NodeManager地址异常,无法远程调用NodeManager来启动Container,直接导致MR任务失败。
方案:
1、四方博客,撸遍全网,无果。
2、游走各群,虚心请教,无果。
3、自力更生,强撸源码,待续 ... ...
源码:
找不到入口就别看了。
org/apache/hadoop/yarn/server/resourcemanager/webapp/RMWebServices.java:252
@GET
@Path("/nodes")
@Produces({ MediaType.APPLICATION_JSON, MediaType.APPLICATION_XML })
public NodesInfo getNodes(@QueryParam("states") String states) {
init();
ResourceScheduler sched = this.rm.getResourceScheduler();
if (sched == null) {
throw new NotFoundException("Null ResourceScheduler instance");
} EnumSet<NodeState> acceptedStates;
if (states == null) {
acceptedStates = EnumSet.allOf(NodeState.class);
} else {
acceptedStates = EnumSet.noneOf(NodeState.class);
for (String stateStr : states.split(",")) {
acceptedStates.add(
NodeState.valueOf(StringUtils.toUpperCase(stateStr)));
}
} Collection<RMNode> rmNodes = RMServerUtils.queryRMNodes(this.rm.getRMContext(),
acceptedStates);
NodesInfo nodesInfo = new NodesInfo();
for (RMNode rmNode : rmNodes) {
NodeInfo nodeInfo = new NodeInfo(rmNode, sched);
if (EnumSet.of(NodeState.LOST, NodeState.DECOMMISSIONED, NodeState.REBOOTED)
.contains(rmNode.getState())) {
nodeInfo.setNodeHTTPAddress(EMPTY);
}
nodesInfo.add(nodeInfo);
} return nodesInfo;
}
这里在生成的节点信息。
org/apache/hadoop/yarn/server/resourcemanager/webapp/dao/NodeInfo.java:57
public NodeInfo(RMNode ni, ResourceScheduler sched) {
NodeId id = ni.getNodeID();
SchedulerNodeReport report = sched.getNodeReport(id);
this.numContainers = 0;
this.usedMemoryMB = 0;
this.availMemoryMB = 0;
if (report != null) {
this.numContainers = report.getNumContainers();
this.usedMemoryMB = report.getUsedResource().getMemory();
this.availMemoryMB = report.getAvailableResource().getMemory();
this.usedVirtualCores = report.getUsedResource().getVirtualCores();
this.availableVirtualCores = report.getAvailableResource().getVirtualCores();
}
this.id = id.toString();
this.rack = ni.getRackName();
this.nodeHostName = ni.getHostName();
this.state = ni.getState();
this.nodeHTTPAddress = ni.getHttpAddress();
this.lastHealthUpdate = ni.getLastHealthReportTime();
this.healthReport = String.valueOf(ni.getHealthReport());
三个关键信息全是ni这个怪胎来的,那就看你怎么来的行不。
org/apache/hadoop/yarn/server/resourcemanager/RMServerUtils.java:63
public static List<RMNode> queryRMNodes(RMContext context,
EnumSet<NodeState> acceptedStates) {
// nodes contains nodes that are NEW, RUNNING OR UNHEALTHY
ArrayList<RMNode> results = new ArrayList<RMNode>();
if (acceptedStates.contains(NodeState.NEW) ||
acceptedStates.contains(NodeState.RUNNING) ||
acceptedStates.contains(NodeState.UNHEALTHY)) {
for (RMNode rmNode : context.getRMNodes().values()) {
if (acceptedStates.contains(rmNode.getState())) {
results.add(rmNode);
}
}
}
看来这个context里有点东西,具体怎么初始化这个context下回再研究,先看里面对RMNodes的操作。
接下的时间里就是在跟Yarn挣扎,但是事实证明并不能找到这个hostname究竟是怎么成了localhost,而不是期望的工作节的hostname。毕竟代码量不少,里面错综复杂,还需要点时间缕缕,那就下次接着看源码。不过在了解了一定原理后,搂一遍源码确实对理解原理还是蛮有效的。
虽然看源码没有得到想要的结果,但是有个大胆想法:通过IP解析hostname是取hosts文件里IP匹配上的第一个hostname(待确认)。因此就将工作节点的ip和hostname挪到第一行,重启yarn集群,MR任务瞬间畅通。



yarn查询/cluster/nodes均返回localhost的更多相关文章
- 查询oracle数据库,返回的数据是乱码。 PL/SQL正常。
查询oracle数据库,返回的数据是乱码. PL/SQL正常. 解决方案如下:
- Mybatis按SQL查询字段的顺序返回查询结果
在SpringMVC+Mybatis的开发过程中,可以通过指定resultType="hashmap"来获得查询结果,但其输出是没有顺序的.如果要按照SQL查询字段的顺序返回查询结 ...
- [ERR] Node 172.168.63.202:7001 is not empty. Either the nodealready knows other nodes (check with CLUSTER NODES) or contains some
关于启动redis集群时: [ERR] Node 172.168.63.202:7001 is not empty. Either the nodealready knows other nodes ...
- Node 192.168.248.12:7001 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
[root@node00 src]# ./redis-trib.rb add-node --slave --master-id4f6424e47a2275d2b7696bfbf8588e8c4c3a5 ...
- spark on yarn,cluster模式时,执行spark-submit命令后命令行日志和YARN AM日志
[root@linux-node1 bin]# ./spark-submit \> --class com.kou.List2Hive \> --master yarn \> --d ...
- [ERR] Node 172.16.6.154:7002 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
关于启动redis集群时: [ERR] Node 172.168.63.202:7001 is not empty. Either the nodealready knows other nodes ...
- 浏览器给openresty连接发送参数请求,查询数据库,并返回json数据
nginx.conf配置文件 #user nobody; worker_processes 1; error_log logs/error.log; #error_log logs/error.log ...
- ecshop后台根据条件查询后不填充table 返回的json数据,content为空?
做ecshop后台开发的时,根据条件查询后,利用ajax返回的content json数据内容为空,没有填充table 效果 预期效果 问题: make_json_result($smarty -&g ...
- Sql Server的艺术(六) SQL 子查询,创建使用返回多行的子查询,子查询创建视图
子查询或内部查询或嵌套查询在另一个SQL查询的查询和嵌入式WHERE子句中. 子查询用于返回将被用于在主查询作为条件的数据,以进一步限制要检索的数据. 子查询可以在SELECT,INSERT,UPDA ...
随机推荐
- vue+sass实现切换字体大小
接到领导指示,用户嫌我做的页面字体太小,15px的字体叫小?领导说用户多是上了年纪的人.没办法,改吧,谁让咱是个搬砖的呢..咳咳 我寻思着这次改大了,下次用户嫌大再让改小呢?干脆给他做个选择字号的功能 ...
- ajax的4个字母分别是什么意思
Asynchronous JavaScript and XML 的缩写,异步的JavaScript和XML.在不重新加载整个页面的情况下 ,AJAX 与服务器交换数据并更新部分网页.
- 正则简单操作cookie、url search
正则操作cookie.url getCookie function getCookie(key) { var cookies = window.document.cookie, reg = new R ...
- Delphi中Chrome Chromium、Cef3学习笔记(四)
原文 http://blog.csdn.net/xtfnpgy/article/details/48155323 一.遍历网页元素并点击JS: 下面代码为找到淘宝宝贝页面,成交记录元素的代码: ...
- SnowFlake学习
分布式系统中生成全局唯一且趋势递增ID UUID - 太长,无序,数据库插入分裂性能不行 利用数据库自增序列,等步长生成 - 依赖数据库 SnowFlake:使用见下图 抄代码 https://www ...
- 导入大数据量sql时候超时的问题
D:\Visual-NMP-x64\Bin\MySQL\bin这个是你mysql的路径 mysqldump.exe -h服务器信息 -umysql的用户名 -pmysql的密码 数据库名 > 要 ...
- [原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(四) -- 安装crowd 3.1.2
[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(四) -- 安装crowd 3.1.2 本来已经安装完毕, 并使用Jira集成的OAuth账户管理, ...
- 聊聊JMM
JMM是什么? JMM 全称 Java memory model ,直译过来就是Java内存模型,这里注意了,指到并不是JVM中的内存分布新生代.老年代.永久代这些,当然也不是 程序计数器(PC).j ...
- tensorflow 查看模型输入输出saved_model_cli show --dir ./xxxx --all
saved_model_cli show --dir ./xxxxxxxx --all 可以查看模型的输入输出,比如使用tensorflow export_model_inference.py 输出的 ...
- selenium使用技巧
标签(空格分隔): selenium 我们进行selenium的时候,就是通过webdriver,对浏览器做一些操作的: webdriver,除了find操作,之外还有哪些方法和属性呢? 1.获取当前 ...