spark批量写写数据到Hbase中(bulkload方式)
1:为什么大批量数据集写入Hbase中,需要使用bulkload
- BulkLoad不会写WAL,也不会产生flush以及split。
- 如果我们大量调用PUT接口插入数据,可能会导致大量的GC操作。除了影响性能之外,严重时甚至可能会对HBase节点的稳定性造成影响。但是采用BulkLoad就不会有这个顾虑。
- 过程中没有大量的接口调用消耗性能
- 可以利用spark 强大的计算能力
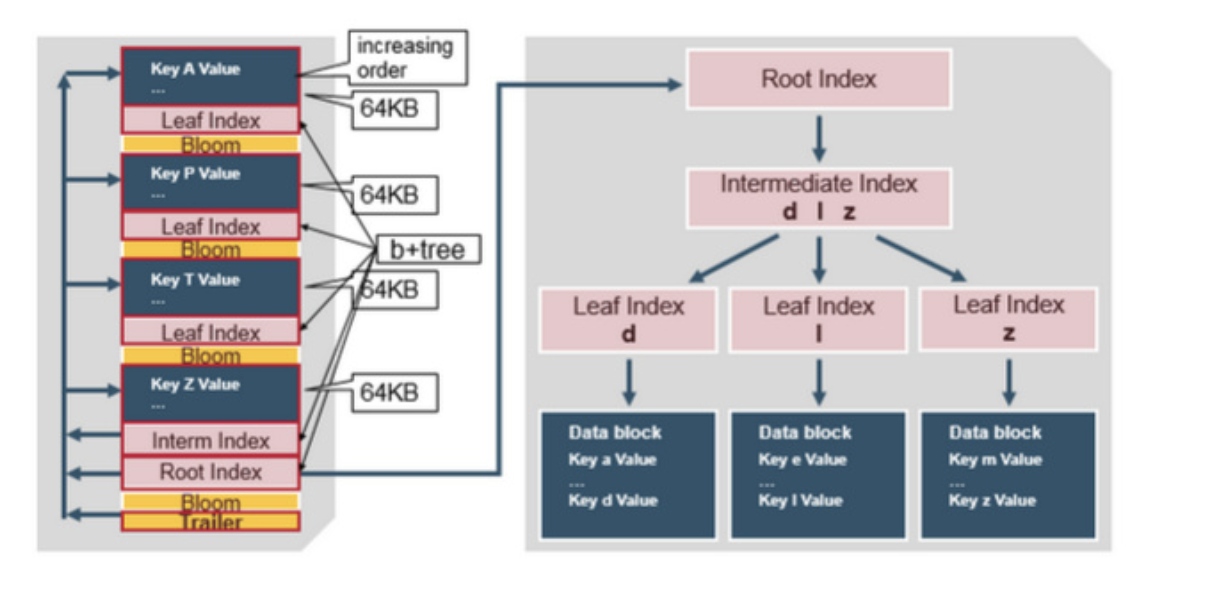
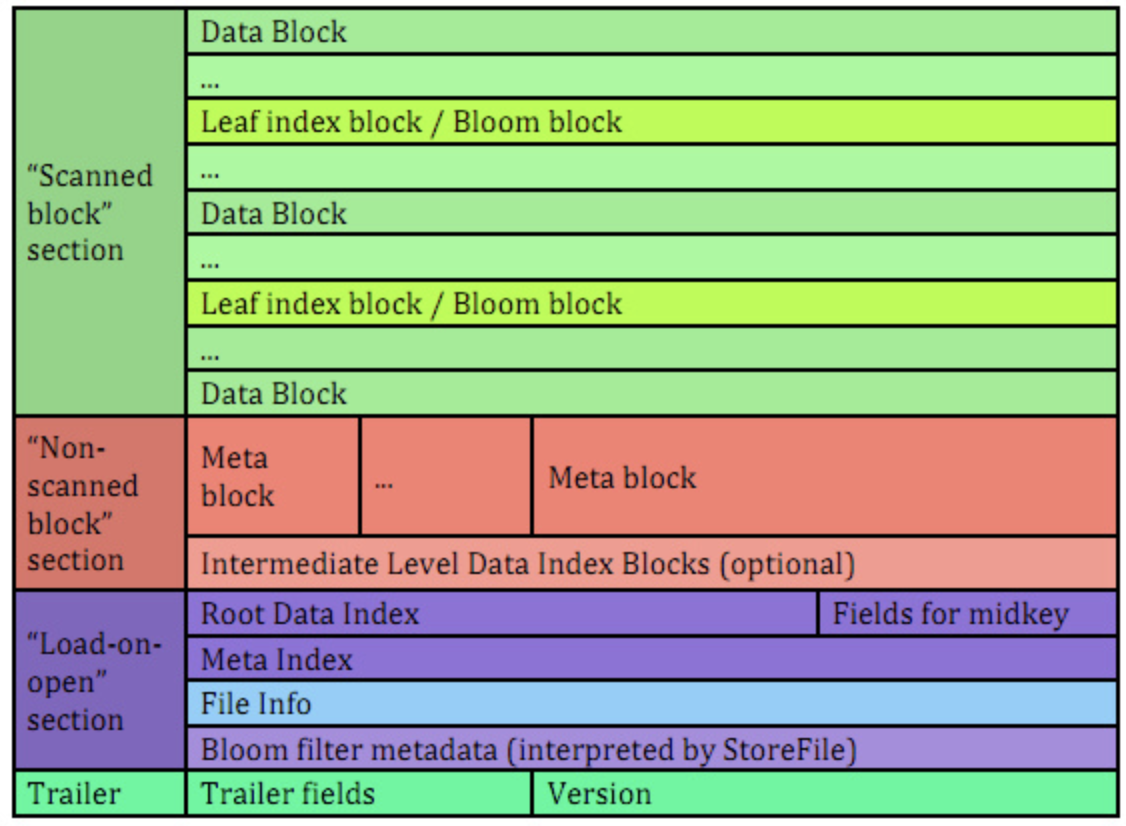
上面是一个总的执行流程图, 数据生成,HFile转换以及HFile加载, 下面是HFile 的格式, 就是个key value 存储结构,
key 是由行健column family 和限定符指定, 然后再加上key的索引


注意:
生成HFile要求Key有序。开始是以为只要行键有序,即map之后,sortByKey就ok,后来HFileOutputFormat一直报后值比前值小(即未排序)。翻了很多鬼佬网站,才发现,这里的行键有序,是要求rowKey+列族+列名整体有序!!!
package hbaseLoad.CommonLoad import java.io.IOException
import java.sql.Date
import java.util
import java.util.concurrent.{Executors, ScheduledExecutorService, TimeUnit} import org.apache.hadoop.fs.Path
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{HFileOutputFormat2, LoadIncrementalHFiles}
import org.apache.hadoop.hbase.{HBaseConfiguration, HColumnDescriptor, HTableDescriptor, KeyValue, TableName}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* Created by angel;
*/
object Hfile {
val zkCluster = "hadoop01,hadoop02,hadoop03"
val hbasePort = "2181"
val tableName = TableName.valueOf("hfile")
val columnFamily = Bytes.toBytes("info")
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Hfile").setMaster("local[*]")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
conf.registerKryoClasses(Array(classOf[D_class]))
val sc = new SparkContext(conf)
val fileData: RDD[String] = sc.textFile("data")
val rdd = fileData.map{
line =>
val dataArray = line.split("@")
val rowkey = dataArray(0)+dataArray(1)
val ik = new ImmutableBytesWritable(Bytes.toBytes(rowkey))
val kv = new KeyValue(Bytes.toBytes(rowkey) , columnFamily , Bytes.toBytes("info") , Bytes.toBytes(dataArray(2)+":"+dataArray(3)+":"+dataArray(4)+":"+dataArray(5)))
(ik , kv)
}
// val scheduledThreadPool = Executors.newScheduledThreadPool(4);
// scheduledThreadPool.scheduleWithFixedDelay(new Runnable() {
// override def run(): Unit = {
// println("=====================================")
// }
//
// }, 1, 3, TimeUnit.SECONDS);
hfile_load(rdd)
}
def hfile_load(rdd:RDD[Tuple2[ImmutableBytesWritable , KeyValue]]): Unit ={
val hconf = HBaseConfiguration.create()
hconf.set("hbase.zookeeper.quorum", zkCluster);
hconf.set("hbase.master", "hadoop01:60000");
hconf.set("hbase.zookeeper.property.clientPort", hbasePort);
hconf.setInt("hbase.rpc.timeout", 20000);
hconf.setInt("hbase.client.operation.timeout", 30000);
hconf.setInt("hbase.client.scanner.timeout.period", 200000);
//声明表的信息
var table: Table = null
var connection: Connection = null
try{
val startTime = System.currentTimeMillis()
println(s"开始时间:-------->${startTime}")
//生成的HFile的临时保存路径
val stagingFolder = "hdfs://hadoop01:9000/hfile"
//将日志保存到指定目录
rdd.saveAsNewAPIHadoopFile(stagingFolder,
classOf[ImmutableBytesWritable],
classOf[KeyValue],
classOf[HFileOutputFormat2],
hconf)
//开始即那个HFile导入到Hbase,此处都是hbase的api操作
val load = new LoadIncrementalHFiles(hconf) //创建hbase的链接,利用默认的配置文件,实际上读取的hbase的master地址
connection = ConnectionFactory.createConnection(hconf)
//根据表名获取表
table = connection.getTable(tableName)
val admin = connection.getAdmin
//构造表描述器
val hTableDescriptor = new HTableDescriptor(tableName)
//构造列族描述器
val hColumnDescriptor = new HColumnDescriptor(columnFamily)
hTableDescriptor.addFamily(hColumnDescriptor)
//如果表不存在,则创建表
if(!admin.tableExists(tableName)){
admin.createTable(hTableDescriptor)
}
//获取hbase表的region分布
val regionLocator = connection.getRegionLocator(tableName)
//创建一个hadoop的mapreduce的job
val job = Job.getInstance(hconf)
//设置job名称
job.setJobName("DumpFile")
//此处最重要,需要设置文件输出的key,因为我们要生成HFile,所以outkey要用ImmutableBytesWritable
job.setMapOutputKeyClass(classOf[ImmutableBytesWritable])
//输出文件的内容KeyValue
job.setMapOutputValueClass(classOf[KeyValue])
//配置HFileOutputFormat2的信息
HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator)
//开始导入
load.doBulkLoad(new Path(stagingFolder), table.asInstanceOf[HTable])
val endTime = System.currentTimeMillis()
println(s"结束时间:-------->${endTime}")
println(s"花费的时间:----------------->${(endTime - startTime)}")
}catch{
case e:IOException =>
e.printStackTrace()
}finally {
if (table != null) {
try {
// 关闭HTable对象 table.close();
} catch {
case e: IOException =>
e.printStackTrace();
}
}
if (connection != null) {
try { //关闭hbase连接. connection.close();
} catch {
case e: IOException =>
e.printStackTrace();
}
}
} } }
spark批量写写数据到Hbase中(bulkload方式)的更多相关文章
- java实现服务端守护进程来监听客户端通过上传json文件写数据到hbase中
1.项目介绍: 由于大数据部门涉及到其他部门将数据传到数据中心,大部分公司采用的方式是用json文件的方式传输,因此就需要编写服务端和客户端的小程序了.而我主要实现服务端的代码,也有相应的客户端的测试 ...
- 简单通过java的socket&serversocket以及多线程技术实现多客户端的数据的传输,并将数据写入hbase中
业务需求说明,由于公司数据中心处于刚开始部署的阶段,这需要涉及其它部分将数据全部汇总到数据中心,这实现的方式是同上传json文件,通过采用socket&serversocket实现传输. 其中 ...
- 【转载】C#批量插入数据到Sqlserver中的三种方式
引用:https://m.jb51.net/show/99543 这篇文章主要为大家详细介绍了C#批量插入数据到Sqlserver中的三种方式,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 本篇, ...
- 大数据学习day20-----spark03-----RDD编程实战案例(1 计算订单分类成交金额,2 将订单信息关联分类信息,并将这些数据存入Hbase中,3 使用Spark读取日志文件,根据Ip地址,查询地址对应的位置信息
1 RDD编程实战案例一 数据样例 字段说明: 其中cid中1代表手机,2代表家具,3代表服装 1.1 计算订单分类成交金额 需求:在给定的订单数据,根据订单的分类ID进行聚合,然后管理订单分类名称, ...
- 批量导入数据到HBase
hbase一般用于大数据的批量分析,所以在很多情况下需要将大量数据从外部导入到hbase中,hbase提供了一种导入数据的方式,主要用于批量导入大量数据,即importtsv工具,用法如下: Us ...
- C#批量插入数据到Sqlserver中的四种方式
我的新书ASP.NET MVC企业级实战预计明年2月份出版,感谢大家关注! 本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的 ...
- C#批量插入数据到Sqlserver中的三种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生 成 ...
- C#_批量插入数据到Sqlserver中的四种方式
先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记 ...
- java批量插入数据进数据库中
方式1: for循环,每一次进行一次插入数据. 方式2: jdbc的preparedStatement的batch操作 PreparedStatement.addBatch(); ...... Pre ...
随机推荐
- android studio定时器
1.超时 CountDownTimer第一个参数超时时间,第二个参数多久执行一次onTick(), 到达设定的超时时间执行onFinsh(),cancel取消超时计数,start重新开始(从零开始). ...
- 使用python脚本批量删除阿里云oss中的mp4文件
#encoding:utf-8 ''' oss中有一些mp4文件需要删除,首先定位出这些文件放在txt文本中 然后通过python操作oss进行批量删除 ''' import oss2 auth = ...
- MYSQL 查看最大连接数和修改最大连接数
MySQL查看最大连接数和修改最大连接数 1.查看最大连接数show variables like '%max_connections%';2.修改最大连接数set GLOBAL max_connec ...
- js 测试性能
console.time('querySelector');for(var i=0; i<1000; i++){document.querySelector('body');}console.t ...
- 23)django-缓存
一:目录 1)简介 2)django缓存方式 3)django应用方式 二:简介 由于Django是动态网站,所有每次请求均会去数据进行相应的操作,当程序访问量大时,耗时必然会更加明显, 最简单解决方 ...
- 4)django-视图view
视图是django功能函数,结合url使用 1.视图方式 视图方式经常用的有两种 用户GET获取数据 用户POST提交数据 用户第一次访问页面是GET 用户 ...
- 图解Metrics, tracing, and logging
Logging,Metrics 和 Tracing 最近在看Gophercon大会PPT的时候无意中看到了关于Metrics,Tracing和Logging相关的一篇文章,凑巧这些我基本都接触过, ...
- windows下如何安装pip以及如何查看pip是否已经安装成功
最近刚学习python,发现很多关于安装以及查看pip是否安装成的例子都比较老,不太适合于现在(python 3.6 )因此,下一个入门级别的教程. 0:首先如何安装python我就不做介绍了. 1: ...
- mysql服务器没有响应
第一步删除c:\windowns下面的my.ini(可以先改成其它的名字也行) 第二步打开对应安装目录下\mysql\bin\winmysqladmin.exe 输入用户名 和密码(也可以忽略此步) ...
- Python继承、方法重写
继承 在编写类时,并不是每次都要从空白开始.当要编写的类和另一个已经存在的类之间存在一定的继承关系时,就可以通过继承来达到代码重用的目的,提高开发效率. class one(): "&quo ...