Feature Extractor[inception v2 v3]
0 - 背景
在经过了inception v1的基础上,google的人员还是觉得有维度约间的空间,在《Rethinking the Inception Architecture for Computer Vision》一文中,通过卷积分解、网格约间等方式来修改inception模块。当然了在BN那篇论文的附录部分也多少涉及到v2的设计方向。
因为第一篇论文并没有详细说明设计inception v1的一些具体原理,而其主要是从如何减小模型的参数量上下手,所以v3上对这部分做了个简单的原则说明:
- principle 1 - 从模型的输入到输出,不要让网络的特征维度变化太快,最好如金字塔一样,慢慢的减少维度;
- principle 2 - 更大维度的表征可以更容易的在网络内部的局部进行处理,所以,如在卷积网络中增加更多的激活神经元那么可以解耦合更多的特征,从而网络就会训练的更快(因为特征解耦了)(参考figure 7);
- principle 3 - 空间聚合可以进行低维嵌入,这样并不会导致网络表示能力降低太多。例如在3*3的卷积之前,可以先对输入信息进行降维。我们假设降维后的数据用在空间聚合上,那么在维度约简过程中相毗邻的单元之间具有很强的相关性会导致信息的减少不明显。而且假如数据本身很容易被降维,那么还能加速训练;如3*3前面加个1*1的卷积
- principle 4 - 在扩增模型的时候,深度和广度需要相适应,不要畸形扩展,即做好两者的平衡关系。
ps:其实上面几点都还是需要去验证的,这里都只是大致的原则,大致的指导方针吧,主要还是为了说明Inception v2的改进是有理可依的。
v1的网络得益于维度约间。这可以被看成是一种特殊的卷积分解从而减少计算量的需要。在视觉网络中我们都期望相邻的神经元激活值都是高度相关的,因此期望在空间聚合之前可以进行约间,从而生成相似的局部表征。所以任何计算量上的减少就意味着参数量的减少。这也就是说如果有合适的分解方式,那么可以得到更多解耦和的参数,因而能够加速训练了。同样可以将多出的计算和内存用来多增加一些卷积核的数量,并且还能保证单机上多模型的稳定性。
1 - inception v2
1.1 分解卷积
因为是建立视觉网络,所以可以用平移不变性这个特点。而对于一个5*5的卷积,其本身的感受野大小和两个3*3的卷积是一样的,可是所需的计算量是不同的,所以很自然的由此进行替换。而更狠一点,如果考虑不重复的感受野计算,那么还能将一个\(n*n\)的卷积分解成一个\(n*1\)的卷积和一个\(1*n\)的卷积的叠加。如下图所示:
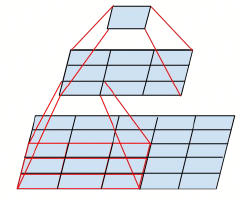
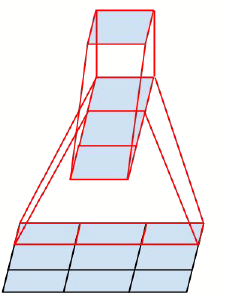
图1.1.1 左:用两个\(3*3\)的代替一个\(5*5\);右:用一个\(3*1\)的和一个\(1*3\)的代替一个\(3*3\)的
所以结果如下:
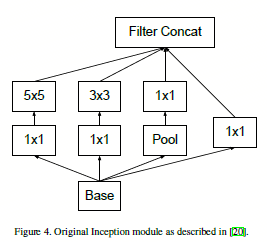
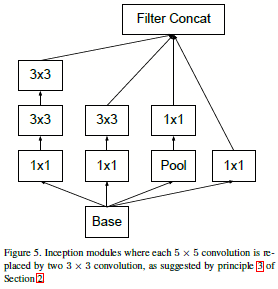
图1.1.2 v1中\(5*5\)的卷积核的替换
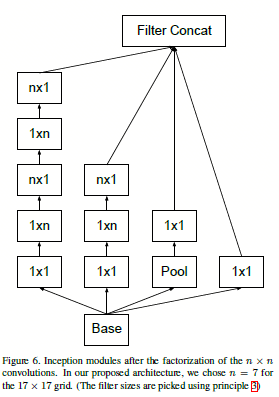
图1.1.3 v1中\(n*n\)的卷积核的替换
不过对于将\(n*n\)的卷积分解成\(n*1\)和\(1*n\)的卷积的时候,发现在网络的前层这样进行卷积分解起不到多大作用,不过在网络的网格为\(m*m\)(m在[12,20]之间)的时候有个较好的结果。在这个层级,如使用\(1*7\)然后使用\(7*1\)的到的结果还是不错的。
1.2 辅助分类器
v1中的辅助分类器是为了将有用的梯度能够立即传递给更低的层,从而改善收敛情况和保证在训练中能够稳定收敛。Lee也主张辅助分类器可以让模型更稳定的训练和更好的收敛。不过本文发现,在训练的早期其实是没有改善收敛情况的;假定一个有辅助分类器,一个没有,那么在两个模型中,最开始都是表现一样的,只有在训练的最后,辅助分类器才有帮助提升效果。将v1中两个辅助分类器中更低的辅助分类器去掉,网络没有太大差别,所以v1中原来的假设辅助分类器可以有助于发展低层级的特征的假设是错的。v3中认为辅助分类器其实类似一个正则化器,支持的事实是:如果边分支使用了bn或者使用dropout层,那么主分类器可以表现的更好。当然,这同时也弱证明了bn也是一个正则化器。
1.3 网格尺度约间
所谓网络尺度约间,对于传统cnn来说,就是每层的feature map变小,或者channel变少。假设一个feature map固定分成\(d*d\)大小的网格,且有\(k\)个通道。为了得到下一层为\(\frac{d}{2}*\frac{d}{2}\)大小的网格,且通道\(2k\)(为了不违反准则1,在减少map大小的时候,相应的增加通道数),则如果先以stride=1进行卷积,然后在进行池化,那么需要的操作是\(d*d*k*2k\),而如果直接池化则需要的操作是\(\frac{d}{2}*\frac{d}{2}*k*2k\),可以看出后者比前者减少了\(3/4\)。

图1.3.1 通常的网格尺度约间方法
如图1.3.1所示,左边那种方法因为map尺度下降太快,违反了准则1,而右边的计算量又太大,所以需要找到一种新的网格尺度约间方法。
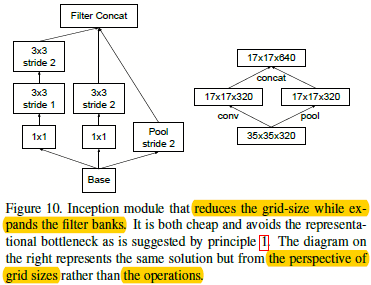
图1.3.2 进行网格尺度约间的方法
作者提出了卷积和池化并行的方式,如图1.3.2右边所示,通过在基于输入为\(35*35*320\)的上面左边是一个stride=2的卷积操作,并列的增加一个stride=2的池化操作,从而并行的输出得到一个\(17*17*640\)的层,可以看出这样即保证了网格尺度的约间,也没有违反准则1.
1.4 google v2网络结构
只要遵循之前的那四点进行网络设计得到的inception的变种,基本上准确度都很稳定。googlenet v2的网络有42层,而计算量只是v1的2.5倍而已,当然还是比vgg要低。
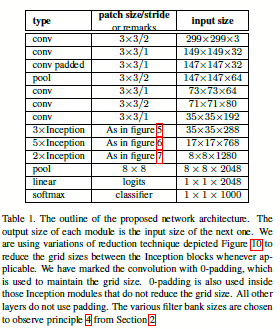
图1.4.1 googlenet v2的网络结构
googlenet v2的网络结构就是将上面的那些修改拿过来组合而成的,而且都遵循着最开始说的4个网络指导原则进行了如下改进(当然这部分描述和图1.4.1略有不符):
- 1 - 将\(7*7\)的卷积替换为3个\(3*3\)的卷积;
- 2 - 其中在\(35*35*288\)的部分引入三个inception v1模块,不过是通过网格尺度约间技术使得输出的时候网络维度变成了\(17*17*768\);
- 3 - 然后引入5个在inception v1上加入卷积分解(大卷积变成小卷积叠加)的模块,同样采用网格尺度约间技术使得网络维度变成了\(8*8*1280\);
- 4 - 接着引入2个在inception v1上加入卷积分解(2维卷积变成1维行(列)卷积)的模块,并将输出的通道合并成2048(即\(8*8*1024\)与另一个\(8*8*1024\)在通道维度上简单的并列)
其中figure 7 如下图:

图1.4.2 在图1.4.1中涉及的figure 7
1.4 低分辨率图片
作者基于不同分辨率进行了网络结构的微调:
- 1 - 299*299的分辨率的在第一层中stride设为2,并且之后采用最大池化;
- 2 - 151*151的分辨率的,在第一层中stride设为1,并且之后采用最大池化;
- 3 - 79*79的分辨率的,在第一层中stride设为1,不要最大池化。
可以看的出来,随着分辨率的降低,那么就需要增加信息的获取;反之减少。基于这三种结构,作者试验发现效果都相当。
1.4 通过标签平滑来进行模型正则
待续
2 - inception v3
其中inception v2加了BN辅助的就是v3了(也就是将针对inception v1 的所有的改进都加起来,然后加个BN)。
Feature Extractor[inception v2 v3]的更多相关文章
- Feature Extractor[Inception v4]
0. 背景 随着何凯明等人提出的ResNet v1,google这边坐不住了,他们基于inception v3的基础上,引入了残差结构,提出了inception-resnet-v1和inception ...
- Feature Extractor[ResNet v2]
0. 背景 何凯明大神等人在提出了ResNet网络结构之后,对其做了进一步的分析工作,详细的分析了ResNet 构建块能起作用的本质所在.并通过一系列的实验来验证恒等映射的重要性,并由此提出了新的构建 ...
- 经典分类CNN模型系列其五:Inception v2与Inception v3
经典分类CNN模型系列其五:Inception v2与Inception v3 介绍 Inception v2与Inception v3被作者放在了一篇paper里面,因此我们也作为一篇blog来对其 ...
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2
from:https://blog.csdn.net/qq_14845119/article/details/73648100 Inception v1的网络,主要提出了Inceptionmodule ...
- GoogLeNet 之 Inception v1 v2 v3 v4
论文地址 Inception V1 :Going Deeper with Convolutions Inception-v2 :Batch Normalization: Accelerating De ...
- Feature Extractor[content]
0. AlexNet 1. VGG VGG网络相对来说,结构简单,通俗易懂,作者通过分析2013年imagenet的比赛的最好模型,并发现感受野还是小的好,然后再加上<network in ne ...
- Feature Extractor[batch normalization]
1 - 背景 摘要:因为随着前面层的参数的改变会导致后面层得到的输入数据的分布也会不断地改变,从而训练dnn变得麻烦.那么通过降低学习率和小心地参数初始化又会减慢训练过程,而且会使得具有饱和非线性模型 ...
- caffe,Inception v2 Check failed: top_shape[j] == bottom[i]->shape(j)
使用Caffe 跑 Google 的Inception V2 对输入图片的shape有要求,某些shape输进去可能会报错. Inception model中有从conv和pooling层concat ...
- 深度学习面试题26:GoogLeNet(Inception V2)
目录 第一层卷积换为分离卷积 一些层的卷积核的个数发生了变化 多个小卷积核代替大卷积核 一些最大值池化换为了平均值池化 完整代码 参考资料 第一层卷积换为分离卷积 net = slim.separab ...
随机推荐
- 13张动图助你彻底看懂马尔科夫链、PCA和条件概率!
13张动图助你彻底看懂马尔科夫链.PCA和条件概率! https://mp.weixin.qq.com/s/ll2EX_Vyl6HA4qX07NyJbA [ 导读 ] 马尔科夫链.主成分分析以及条件概 ...
- 照葫芦画瓢系列之Java --- Maven的集成和使用
一.和Eclipse的集成 1.添加Maven 在windows--> preferences中找到maven选项,如下图: 如果没有上图的Name为apache-maven-3.5.2的项,则 ...
- iOS -----------Downloading core failed:
[!] /bin/bash -c set -e sh build.sh cocoapods-setup core is not a symlink. Deleting... Downloading d ...
- 在插件中得到,调用 插件的id
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8" ...
- Pycharm配置anaconda环境
概述 在上节介绍了anaconda管理python环境,而Pycharm作为主流python IDE,两者配合使用才算完美. 配置 File - Setting - Project Interpret ...
- 关于谷歌JSV8与微软JSRT的性能比较
首先,我并没有得到实际的比较结果,望有兴趣的朋友可以帮助完成这个比较. benchmarksgame,提供了各种语言的性能比较,但都为linux下的测试,很难比较谷歌与微软的东西. 众所周知,JSV8 ...
- 编程经验点滴----巧妙解决 Oracle NClob 读写问题
最近一个新项目中,尝试在 Oracle 数据库中使用 NCLOB 来保存大的 xml 字符串. 在代码自动生成工具(通过 JDBC 驱动程序,读数据库表结构,自动生成对应的 java 代码,包含增加. ...
- Centos7开启ssh免密码登录
1.输入命令:cd .ssh进入rsa公钥私钥目录(清空旧秘钥) 2.在当前目录下执行ssh-keygen -t rsa,三次回车后生成新的公钥(id_rsa.pub)私钥(id_rsa)文件(每个节 ...
- LINQ的求和 平均 最大 最小 分组 计数 等等
1.简单形式: var q = from p in db.Products group p by p.CategoryID into g select g; 语句描述:使用Group By按Categ ...
- 洗礼灵魂,修炼python(90)-- 知识拾遗篇 —— 协程
协程 1.定义 协程,顾名思义,程序协商着运行,并非像线程那样争抢着运行.协程又叫微线程,一种用户态轻量级线程.协程就是一个单线程(一个脚本运行的都是单线程) 协程拥有自己的寄存器上下文和栈.协程调度 ...