matlab练习程序(马尔可夫聚类MCL)
本文主要参考:
https://wenku.baidu.com/view/b7907665caaedd3383c4d31b.html
https://blog.csdn.net/u010376788/article/details/50187321
虽然参考上面两篇文章,不过这里和他给出的算法步骤不完全一致。
因为上面文章是针对Graphs的,矩阵中有边为0的数据,而我的数据是Vector的,边是根据距离计算出来的,应该还是有点区别的,而且我还用了kmeans。
首先给出他的算法步骤:
1.输入一个无向图,Expansion的幂e和Inflation的参数r。
2.创建邻接矩阵。
3.对每个结点添加自循环(可选的)。
4.标准化矩阵(每个元素除以所在列的所有元素之和)。
5.计算矩阵的第e次幂。
6.用参数r对求得的矩阵进行Inflation处理。
7.重复第5步和第6步,直到状态稳定不变(收敛)。
8.把最终结果矩阵转换成聚簇。
然后是这里的算法步骤:
1.输入数据,创建邻接矩阵。
2.标准化矩阵(每个元素除以所在列的所有元素之和)。
3.对标准化后的矩阵进行马尔可夫状态转移。
4.重复第2步和第3步,直到状态稳定不变(收敛)。
5.使用kmeans把最终结果矩阵转换成聚簇。(不明白kmeans的可以看看这篇文章)
代码如下:
clear all;
close all;
clc; K=;
theta=:0.01:*pi;
p1=[*cos(theta) + rand(,length(theta))/;*sin(theta)+ rand(,length(theta))/];
p2=[*cos(theta) + rand(,length(theta))/;*sin(theta)+ rand(,length(theta))/];
p3=[cos(theta) + rand(,length(theta))/;sin(theta)+ rand(,length(theta))/];
p=[p1 p2 p3]'; randIndex = randperm(length(p))'; %打乱数据顺序
p=p(randIndex,:);
plot(p(:,),p(:,),'.') for i = :length(p)
for j =:length(p)
W(i,j) = sqrt(sum((p(i,:)-p(j,:)).^)); %根据距离初始化无向图的边
end
end preW=W;
while
x=repmat(sum(W),length(p),);
W=W./x;
W=W*W; %马尔科夫状态转移 if sum(sum(preW-W))<1e-15
break;
end preW=W;
end [idx,ctrs] = kmeans(W(:,),K); %用kmeans将收敛矩阵转换为聚簇
figure;
plot(p(idx==,),p(idx==,),'r.')
hold on;
plot(p(idx==,),p(idx==,),'g.')
plot(p(idx==,),p(idx==,),'b.')
原始数据:
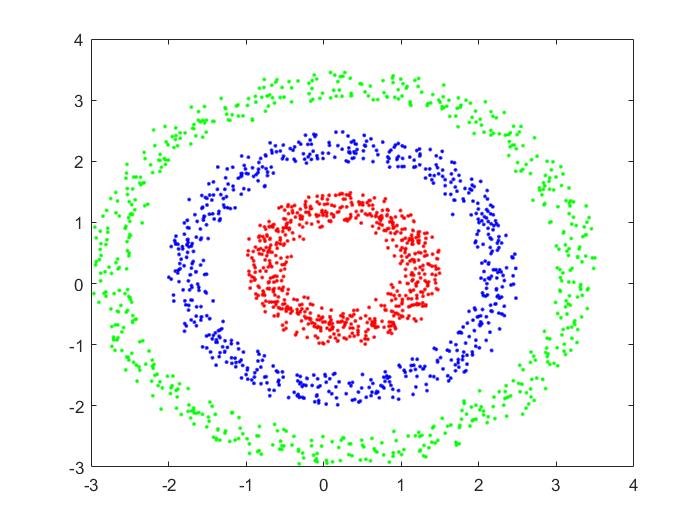
聚类后:
matlab练习程序(马尔可夫聚类MCL)的更多相关文章
- 马尔科夫随机场(MRF)及其在图像降噪中的matlab实现
(Markov Random Field)马尔科夫随机场,本质上是一种概率无向图模型 下面从概率图模型说起,主要参考PR&ML 第八章 Graphical Model (图模型) 定义:A g ...
- 从随机过程到马尔科夫链蒙特卡洛方法(MCMC)
从随机过程到马尔科夫链蒙特卡洛方法 1. Introduction 第一次接触到 Markov Chain Monte Carlo (MCMC) 是在 theano 的 deep learning t ...
- [综]隐马尔可夫模型Hidden Markov Model (HMM)
http://www.zhihu.com/question/20962240 Yang Eninala杜克大学 生物化学博士 线性代数 收录于 编辑推荐 •2216 人赞同 ×××××11月22日已更 ...
- 机器学习&数据挖掘笔记_19(PGM练习三:马尔科夫网络在OCR上的简单应用)
前言: 接着coursera课程:Probabilistic Graphical Models上的实验3,本次实验是利用马尔科夫网络(CRF模型)来完成单词的OCR识别,每个单词由多个字母组合,每个字 ...
- 隐马尔科夫模型(Hidden Markov Models)
链接汇总 http://www.csie.ntnu.edu.tw/~u91029/HiddenMarkovModel.html 演算法笔记 http://read.pudn.com/downloads ...
- Python实现HMM(隐马尔可夫模型)
1. 前言 隐马尔科夫HMM模型是一类重要的机器学习方法,其主要用于序列数据的分析,广泛应用于语音识别.文本翻译.序列预测.中文分词等多个领域.虽然近年来,由于RNN等深度学习方法的发展,HMM模型逐 ...
- 马尔可夫随机场(Markov random fields) 概率无向图模型 马尔科夫网(Markov network)
上面两篇博客,解释了概率有向图(贝叶斯网),和用其解释条件独立.本篇将研究马尔可夫随机场(Markov random fields),也叫无向图模型,或称为马尔科夫网(Markov network) ...
- 隐马尔可夫(HMM)/感知机/条件随机场(CRF)----词性标注
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 7. 词性标注 7.1 词性标注概述 什么是词性 在语言学上,词性(Par-Of- ...
- HMM基本原理及其实现(隐马尔科夫模型)
HMM(隐马尔科夫模型)基本原理及其实现 HMM基本原理 Markov链:如果一个过程的“将来”仅依赖“现在”而不依赖“过去”,则此过程具有马尔可夫性,或称此过程为马尔可夫过程.马尔可夫链是时间和状态 ...
随机推荐
- C# 请求接口返回中文乱码→???
在工作过程中,调用第三方接口出现当返回的数据是中文的时候,中文数据便会变成 这样??? 迷~ ,一开始我以为是发送成功后接收字符编码是不是不对,在换过UTF-8,Unicode,...都是不行. 最后 ...
- centos 7 mariadb安装
centos 7 mariadb安装 1.安装MariaDB 安装命令 yum -y install mariadb mariadb-server 安装完成MariaDB,首先启动MariaDB sy ...
- Mac下快速搭建PHP开发环境
最近做了一个后端的项目,是用PHP+MySQL+Nginx做的,所以把搭建环境的方法简单总结一下. 备注: 物料:Apache/Nginx+PHP+MySQL+MAMP Mac OS 10.12.1 ...
- Python快速学习02:基本数据类型 & 序列
前言 系列文章:[传送门] 也就每点一点点的开始咯,“还有两年时间,两年可以学很多东西的” Python ['paɪθən] n. 巨蛇,大蟒 基本数据类型 变量不需要声明 a=10 # int 整 ...
- python scrapy 爬取西刺代理ip(一基础篇)(ubuntu环境下) -赖大大
第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrapy框架 具体就自行百度了,主要内容不是在这. 第二步:创建scrapy(简单介绍) 1.Creating a p ...
- [NewLife.XCode]增删改查入门
NewLife.XCode是一个有10多年历史的开源数据中间件,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量结合示例代码和运行日志来进行深入分析,蕴含 ...
- Oracle 理论到实践之碎碎念
有关 Oracle 的著名谣传 1.如果你想把表中数据复制到另一张表,或者想根据现有表创建一个类似的新表,网上有大量不明所以的帖子告诉你实现该功能的语法是select field1,field2 in ...
- C#.Net Core 操作Docker中的redis数据库
做软件开发的人,会在本机安装很多开发时要用到的软件,比如数据库,有MS SQL Server,MySQL,等,如果每种数据库都按照在本机确实有点乱,这个时候我们就想用虚拟机来隔离,这样就不会扰乱本机一 ...
- leetcode — plus-one
import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * Source : https://o ...
- [机器学习]正则化方法 -- Regularization
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到. L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合( ...