【Python3爬虫】用Python中的队列来写爬虫
一、写在前面
当你看着你的博客的阅读量慢慢增加的时候,内心不禁有了些小激动,但是不得不吐槽一下--博客园并不会显示你的博客的总阅读量是多少。而这一篇博客就将教你怎么利用队列这种结构来编写爬虫,最终获取你的博客的总阅读量。
二、必备知识
队列是常用数据结构之一,在Python3中要用queue这个模块来实现。queue这个模块实现了三种队列:
class queue.Queue(maxsize=0):FIFO队列(first in first out),先进先出,第一个进入队列的元素会第一个从队列中出来。maxsize用于设置队列里的元素总数,若小于等于0,则总数为无限大。
class queue.LifoQueue(maxsize=0):LIFO队列(last in first out),后进先出,最后一个进入队列的元素会第一个从队列中出来。maxsize用于设置队列里的元素总数,若小于等于0,则总数为无限大。
class queue.PriorityQueue(maxsize=0):优先级队列(first in first out),给队列中的元素分配一个数字标记其优先级。maxsize用于设置队列里的元素总数,若小于等于0,则总数为无限大。
这次我使用的是Queue这个队列,Queue对象中包含的主要方法如下:
Queue.put(item, block=True, timeout=None):将元素放入到队列中。block用于设置是否阻塞,如果timeout为正数,表明最多阻塞多少秒。
Queue.get(block=True, timeout=None):从队列中删除并返回一个元素,如果队列为空,则报错。block用于设置是否阻塞,如果timeout为正数,表明最多阻塞多少秒。
Queue.empty():判断队列是否为空,如果队列为空,返回False,否则返回True。
三、具体步骤
首先进入博客,然后打开开发者工具选择查看元素,如下:
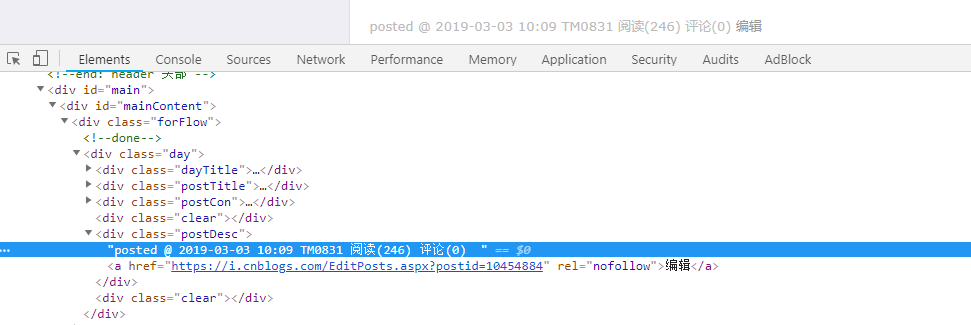
这里只要定位到类名为postDesc的div节点就可以提取到我们想要的阅读量信息了,这一步是很简单的。问题在于如何实现翻页?先定位到下一页查看一下元素:
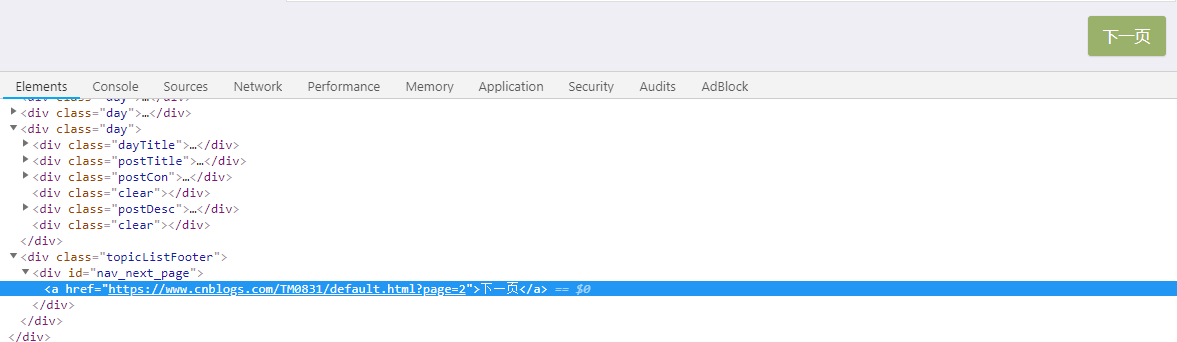
好像定位到id为nav_next_page的div节点就行了,是这样吗?点击进入下一页,然后再次定位查看一下:
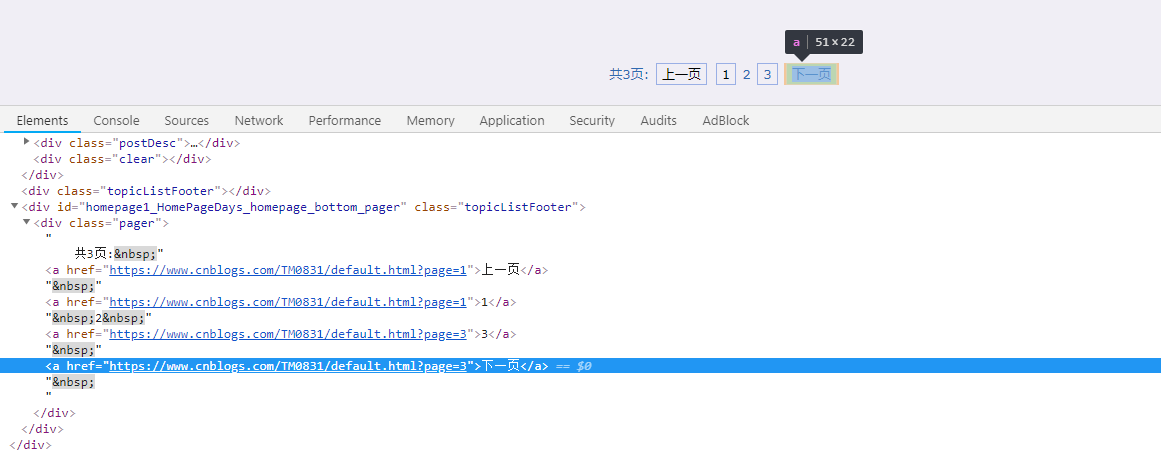
可以看到用之前定位div节点的方法已经不行了,怎么办呢?我的解决办法是用正则表达式进行匹配,因为下一页对应的元素都是这样的:
<a href="链接">下一页</a>
所以只需要进行一下正则匹配就能获取下一页的链接了,如果获取不到,就说明已经是最后一页了!
四、完整代码
"""
Version: Python3.5
Author: OniOn
Site: http://www.cnblogs.com/TM0831/
Time: 2019/3/11 10:46
"""
import re
import queue
import requests
from lxml import etree class CrawlQueue:
def __init__(self):
"""
初始化
"""
self.q = queue.Queue() # 爬取队列
self.username = input("请输入您的博客名称:")
self.q.put("http://www.cnblogs.com/" + self.username)
self.urls = ["http://www.cnblogs.com/" + self.username] # 记录爬取过的url
self.result = [] # 储存阅读量数据 def request(self, url):
"""
发送请求和解析网页
:param url: 链接
:return:
"""
res = requests.get(url)
et = etree.HTML(res.text)
lst = et.xpath('//*[@class="postDesc"]/text()')
for i in lst:
num = i.split(" ")[5].lstrip("阅读(").rstrip(")")
self.result.append(int(num)) # 下一页
next_page = re.search('<a href="(.*?)">下一页</a>', res.text)
if next_page:
href = next_page.group().split(' ')[-1].replace('<a href="', '').replace('">下一页</a>', '')
if href not in self.urls: # 确保之前没有爬过
self.q.put(href)
self.urls.append(href) def get_url(self):
"""
从爬取队列中取出url
:return:
"""
if not self.q.empty():
url = self.q.get()
self.request(url) def main(self):
"""
主函数
:return:
"""
while not self.q.empty():
self.get_url() if __name__ == '__main__':
crawl = CrawlQueue()
crawl.main()
print("您的博客总阅读量为:{}".format(sum(crawl.result)))
完整代码已上传到GitHub!
【Python3爬虫】用Python中的队列来写爬虫的更多相关文章
- python中利用队列asyncio.Queue进行通讯详解
python中利用队列asyncio.Queue进行通讯详解 本文主要给大家介绍了关于python用队列asyncio.Queue通讯的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细 ...
- java/python中的队列
Queue<TreeNode> que=new LinkedList<>(); 用linkedlist实现队列,offer,poll进出队列,peek对列顶部元素 python ...
- Python中的队列
参考资料: https://www.cnblogs.com/yhleng/p/9493457.html 问:我们为什么想使用队列? 答:为了方便,我就想喂给队列一堆object,就想让它们先进先出(F ...
- 6、Python 中 利用 openpyxl 读 写 excel 操作
__author__ = 'Administrator' from openpyxl import load_workbook # Excel_Util 类 class Excel_util: #初始 ...
- python中的Queue(队列)详解
一.Queue简介 python中的队列分类可分为两种: 1.线程Queue,也就是普通的Queue 2.进程Queue,在多线程与多进程会介绍. Queue的种类: FIFO: Queue.Que ...
- python中的生成器函数是如何工作的?
以下内容基于python3.4 1. python中的普通函数是怎么运行的? 当一个python函数在执行时,它会在相应的python栈帧上运行,栈帧表示程序运行时函数调用栈中的某一帧.想要获得某个函 ...
- 爬虫开发python工具包介绍 (1)
本文来自网易云社区 作者:王涛 本文大纲: 简易介绍今天要讲解的两个爬虫开发的python库 详细介绍 requests库及函数中的各个参数 详细介绍 tornado 中的httpcilent的应用 ...
- Python中生成器,迭代器,以及一些常用的内置函数.
知识点总结 生成器 生成器的本质就是迭代器. 迭代器:Python中提供的已经写好的工具或者通过数据转化得来的. 生成器:需要我们自己用Python代码构建的 创建生成器的三种方法: 通过生成器函数 ...
- Python中HTTPS连接
permike 原文 Python中HTTPS连接 今天写代码时碰到一个问题,花了几个小时的时间google, 首先需要安装openssl,更新到最新版本后,在浏览器里看是否可访问,如果是可以的,所以 ...
随机推荐
- SOFA 源码分析 — 扩展机制
前言 我们在之前的文章中已经稍微了解过 SOFA 的扩展机制,我们也说过,一个好的框架,必然是易于扩展的.那么 SOFA 具体是怎么实现的呢? 一起来看看. 如何使用? 看官方的 demo: 1.定义 ...
- 佛祖镇楼,BUG避易
def FZZL(): print(" _ooOoo_ ") print(" o8888888o ") print(" 88 . 88 ") ...
- MySQL技术内幕 InnoDB存储引擎(笔记)
1. InnoDB 体系架构 其中,后台程序主要负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最近的数据. 此外将已经修改的数据刷新到磁盘文件,同时保证在数据库发生异常的时候Innodb能恢复正常 ...
- Python_检查程序规范
''' 检查Python程序的一些基本规范,例如,运算符两测是否有空格,是否每次只导入一个模块,在不同的功能模块之间是否有空行,注释是否够多,等等 ''' import sys import re d ...
- Python_二叉树
BinaryTree.py '''二叉树:是每个节点最多有两个子树(分别称为左子树和右子树)的树结构,二叉树的第i层最多有2**(i-1)个节点,常用于排序或查找''' class BinaryTre ...
- 计算机协议、标准以及OSI模型的简单介绍
由概念启发学习,引导学习.本篇文章中包含了一些最基本的概念和底层知识.虽然零碎,但是这是基础. 一.协议和标准 协议指的是一组控制数据通信的规则.协议有三要素:语法(syntax),语义(semant ...
- 并发库应用之十三 & 并发集合类的应用
传统集合实现同步的问题 举了一个例子:Map集合线程不同步导致的问题. 解决办法:使用同步的Map集合 使用集合工具类中的方法将不同步的集合转为同步的Collections.synchronizedM ...
- codeforces 982D Shark
题意: 给出一个数组,删除大于等于k的数字,使得其满足以下条件: 1.剩余的连续的段,每一段的长度相等: 2.在满足第一个条件的情况下,段数尽可能多: 3.在满足前两个条件的情况下,k取最小的. 求k ...
- linux 安装 PHP fileinfo 扩展
将windows解压Linux服务器 1.错误: PHP Fileinfo extension must be installed/enabled to use Intervention Image. ...
- sql server按符号截取字符串
http://www.360doc.com/content/12/0626/13/1912775_220523992.shtml