SQL Server 一列或多列重复数据的查询,删除(转载)
业务需求
最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库)。要求导入目标数据库的数据不能出现重复。但情况是数据源本身就有重复的数据。所以要先清除数据源数据。
于是就把关于重复数据的查询和处理总结一下。这里只可虑基于数据库解决方案。不考虑程序的实现。
环境为:SQL Server 2008
基于数据库的解决方案
数据库测试表dbo.Member
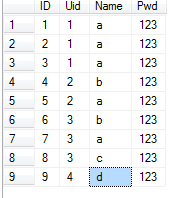
一、单列重复
一,带有having条件的分组查询方法
(1)查询某一列重复记录
语句:
SELECT Name FROM dbo.Member t WHERE Name IN (SELECT Name FROM dbo.Member GROUP BY Name HAVING COUNT(Name)>1 ) ORDER BY t.Name
查询结果:

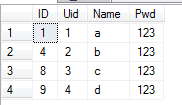
(2)查询某一列不重复的记录
语句:
SELECT * FROM dbo.Member WHERE ID IN (SELECT MIN(ID) FROM dbo.Member GROUP BY Name)
查询结果:
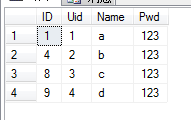
(3)清除某一列重复的数据
语句:
DELETE FROM dbo.Member WHERE ID NOT IN (SELECT MIN(ID) FROM dbo.Member GROUP BY Name)
执行结果:
解释:上面的例子只保存了各自Name的最小值。
二,DISTINCT 的用法
温馨提醒:
不支持多列统计
Oracle和DB2数据库也适用
利用distinct关键字返回唯一不同的值
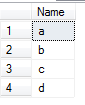
(1)查询某一列不重复数据
语句:
SELECT DISTINCT Name FROM dbo.Member
结果集:
(2)DISTINCT 查询多列不重复(如果查询的列有任何一个不重复,则这条记录视为不重复)
语句:
SELECT DISTINCT Name,Uid FROM dbo.Member
查询结果

DISTINCT 用于统计 语句
SELECT COUNT(DISTINCT(Name)) FROM dbo.Member
二、多列重复
数据表结构
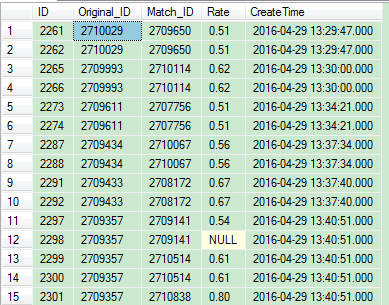
查找Original_ID和Match_ID这两列值重复的行
SQL语句
SELECT m.* FROM dbo.Match m,(
SELECT Original_ID,Match_ID
FROM dbo.Match
GROUP BY Original_ID,Match_ID
HAVING COUNT(1)>1
) AS m1
WHERE m.Original_ID=m1.Original_ID AND m.Match_ID=m1.Match_ID
查询结果

SQL Server 一列或多列重复数据的查询,删除(转载)的更多相关文章
- SQL Server使用 LEFT JOIN ON LIKE进行数据关联查询
这是来新公司写的第一篇文章,使用LEFT JOIN ON LIKE处理一下这种问题: SQL视图代码如下: CREATE View [dbo].[VI_SearchCN] AS --搜索产品的文件 ( ...
- SQL Server 一列或多列重复数据的查询,删除
业务需求 最近给公司做一个小工具,把某个数据库(数据源)的数据导进另一个数据(目标数据库).要求导入目标数据库的数据不能出现重复.但情况是数据源本身就有重复的数据.所以要先清除数据源数据. 于是就把关 ...
- 关于SQL Server数据库中的标识列
一.标识列的定义以及特点 SQL Server中的标识列又称标识符列,习惯上又叫自增列. 该种列具有以下三种特点: 1.列的数据类型为不带小数的数值类型 2.在进行插入(Insert)操作时,该列的值 ...
- SQL Server如何在变长列上存储索引
这篇文章我想谈下SQL Server如何在变长列上存储索引.首先我们创建一个包含变长列的表,在上面定义主键,即在上面定义了聚集索引,然后往里面插入80000条记录: -- Create a new t ...
- SQL Server缺省约束、列约束和表约束
SQL Server缺省约束是SQL Server数据库中的一种约束,下面就为您介绍SQL Server缺省约束.列约束和表约束的定义方法啊,供您参考. SQL Server缺省约束 SQL Serv ...
- SQL Server中Id自增列的最大Id是多少
什么是自增列 在SQL Server中可以将Id列设为自增.即无需为Id指定值,由SQL Server自动给该列赋值,每新增一列Id的值加一,初始值为1. 需要注意的是即使将原先添加的所有数据都删除, ...
- 浅析SQL Server数据库中的伪列以及伪列的含义
SQL Server中的伪列 下午看QQ群有人在讨论(非聚集)索引的存储,说,对于聚集索引表,非聚集索引存储的是索引键值+聚集索引键值:对于非聚集索引表,索引存储的是索引键值+RowId,这应该是一个 ...
- SQL Server 2016新特性:列存储索引新特性
SQL Server 2016新特性:列存储索引新特性 行存储表可以有一个可更新的列存储索引,之前非聚集的列存储索引是只读的. 非聚集的列存储索引支持筛选条件. 在内存优化表中可以有一个列存储索引,可 ...
- Sql Server中判断表、列不存在则创建的方法[转]
一.Sql Server中如何判断表中某列是否存在 首先跟大家分享Sql Server中判断表中某列是否存在的两个方法,方法示例如下: 比如说要判断表A中的字段C是否存在两个方法: 第一种方法 ? ...
随机推荐
- Charpter3 名字 作用域 约束
一个对象拥有其语义价值的区域<其作用域 当一个变量将不再被使用,那它应该被理想的回收机制回收.但现实是我们仅当一个变量离开了其作用域,或变成不可访问,才考虑回收. 然而,作用域规则有其优点:1. ...
- java自动化-数据驱动juint演示,上篇
本文旨在帮助读者介绍,一般的全自动化代码接口,并简单介绍如何使用数据驱动来实现简单的自动化 在经过上述几个博客介绍后,相信读者对自动启动执行一个java编译过的class有了一定了解,也完全有能力去执 ...
- Mac PyCharm激活码(转载CSDN的猪哥66文章)
对于很多刚接触python的新手来说,各种资源都是非常稀缺的.我也是刚接触python不久的新手,有好的资源就分享出来大家共同进步. 这篇文章是教你怎么安装和破解pycharm的教程,我在2019.4 ...
- re模块的方法总结
re模块的方法总结 一,查找 1:match 匹配string 开头,成功返回Match object, 失败返回None,只匹配一个. 示例: s="abc221kelvin4774&qu ...
- Java连接redis
一.依赖包 jedis-2.1.0.jar commons-pool-1.6.jar 二.实例 //连接参数public class RedisConfig { public static int ...
- c#命名规范汇总12条
前言 在刚学习c#的时候,在脑子根本就么有命名规范这个概念,有了一定入门的基础,也很难严格要求自己去规范代码的命名,工作后,发现自己的命名和其他人的命名总会有一些出入,总会闹出一些尴尬的笑话,这里汇总 ...
- css,解决文字与图片对齐的问题
测试代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- 好看又能打的CRM系统大比拼:Salesforce, SugarCRM, Odoo等
介绍 今天的CRM市场提供了大量的解决方案和软件替代品.有些适合大型企业(通常需要内部托管),而其他企业则更多地应用于SME的需求(通常使用云托管解决方案). 在CRM解决方案方面,提供商必须调整其产 ...
- Maven 基本的认识
Maven 基本的认识 1. 什么是Maven? 在平时开发中,经常遇到某个jar包,我在代码层已经Import 和@Automation了,编译器还是提醒你某个jar包找不到,往往这时来个mvn i ...
- SQL 高效运行注意事项(二)
SQL Server高效运行总的来说有两种方式: 一. 扩容,提高服务器性能,显著提高CPU.内存,解决磁盘I/O瓶颈.硬件的提升是立竿见影的,而且是风险小,在硬件更新换代非常快的年代, 当SQLSe ...