汽车之家店铺数据抓取 DotnetSpider实战[一]
一、背景
春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得庆幸的,该库也支持.Net Core,于是趁着春节的空档研究一下整个开源项目,顺便实战一下。目前互联网汽车行业十分火热,淘车,人人车,易车,汽车之家,所以我选取了汽车之家,芒果汽车这个店铺,对数据进行抓取。
二、开发环境
VS2017+.Net Core2.x+DotNetSpider+Win10
三、开发
3.1新建.Net Core项目
新建一个.Net Core 控制台应用
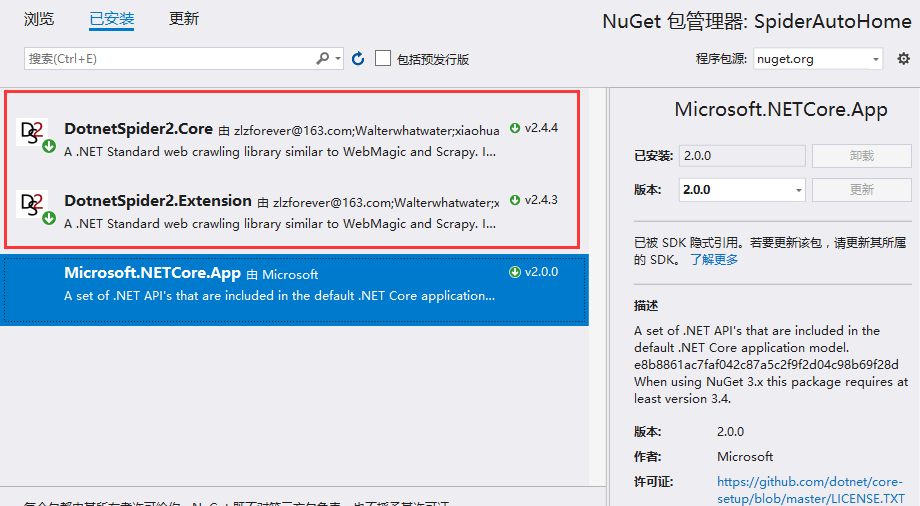
3.2通过Nuget添加DotNetSpider类库
搜索DotnetSpider,添加这两个库就行了
3.3分析需要抓取的网页地址
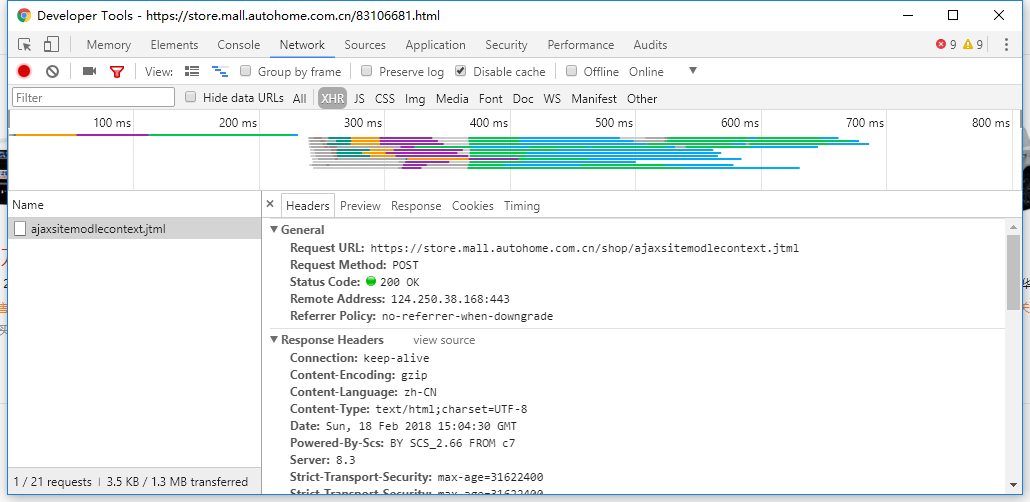
打开该网页https://store.mall.autohome.com.cn/83106681.html,红框区域就是我们要抓取的信息。

我们通过Chrome的开发工具的Network抓取到这些信息的接口,在里面可以很清楚的知道HTTP请求中所有的数据,包括Header,Post参数等等,其实我们把就是模拟一个HTTP请求,加上对HTML的一个解析就可以将数据解析出来。
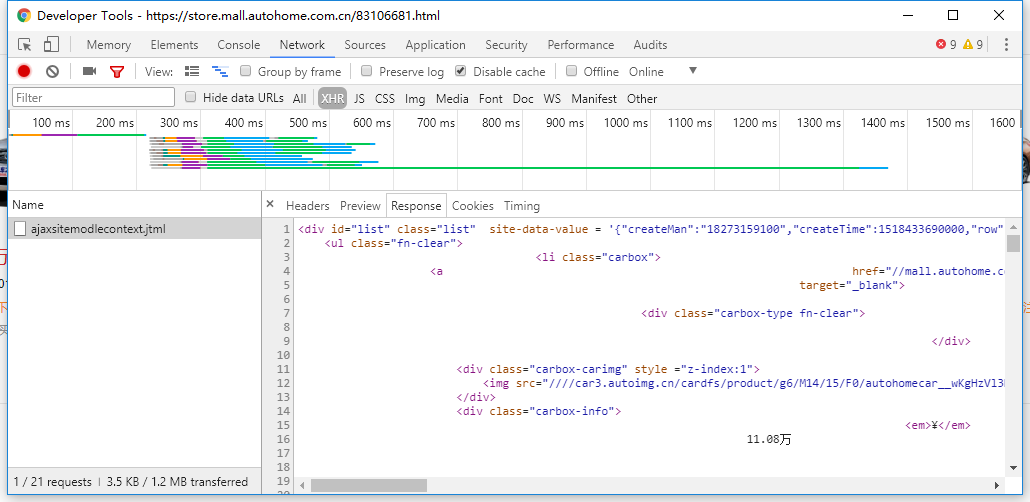
参数page就是页码,我们只需要修改page的值就可以获取指定页码的数据了。

返回结果就是列表页的HTML。
3.4创建存储实体类AutoHomeShopListEntity
class AutoHomeShopListEntity : SpiderEntity
{
public string DetailUrl { get; set; }
public string CarImg { get; set; }
public string Price { get; set; }
public string DelPrice { get; set; }
public string Title { get; set; }
public string Tip { get; set; }
public string BuyNum { get; set; } public override string ToString()
{
return $"{Title}|{Price}|{DelPrice}|{BuyNum}";
}
}
3.5创建AutoHomeProcessor
用于对于获取到的HTML进行解析并且保存
private class AutoHomeProcessor : BasePageProcessor
{
protected override void Handle(Page page)
{
List<AutoHomeShopListEntity> list = new List<AutoHomeShopListEntity>();
var modelHtmlList = page.Selectable.XPath(".//div[@class='list']/ul[@class='fn-clear']/li[@class='carbox']").Nodes();
foreach (var modelHtml in modelHtmlList)
{
AutoHomeShopListEntity entity = new AutoHomeShopListEntity();
entity.DetailUrl = modelHtml.XPath(".//a/@href").GetValue();
entity.CarImg = modelHtml.XPath(".//a/div[@class='carbox-carimg']/img/@src").GetValue();
var price = modelHtml.XPath(".//a/div[@class='carbox-info']").GetValue(DotnetSpider.Core.Selector.ValueOption.InnerText).Trim().Replace(" ", string.Empty).Replace("\n", string.Empty).Replace("\t", string.Empty).TrimStart('¥').Split("¥");
if (price.Length > )
{
entity.Price = price[];
entity.DelPrice = price[];
}
else
{
entity.Price = price[];
entity.DelPrice = price[];
}
entity.Title = modelHtml.XPath(".//a/div[@class='carbox-title']").GetValue();
entity.Tip = modelHtml.XPath(".//a/div[@class='carbox-tip']").GetValue();
entity.BuyNum = modelHtml.XPath(".//a/div[@class='carbox-number']/span").GetValue();
list.Add(entity);
}
page.AddResultItem("CarList", list);
} }
3.6创建AutoHomePipe
用于输出抓取到的结果。
private class AutoHomePipe : BasePipeline
{ public override void Process(IEnumerable<ResultItems> resultItems, ISpider spider)
{
foreach (var resultItem in resultItems)
{
Console.WriteLine((resultItem.Results["CarList"] as List<AutoHomeShopListEntity>).Count);
foreach (var item in (resultItem.Results["CarList"] as List<AutoHomeShopListEntity>))
{
Console.WriteLine(item);
}
}
}
}
3.7创建Site
主要就是将HTTP的Header部信息放进去
var site = new Site
{
CycleRetryTimes = ,
SleepTime = ,
Headers = new Dictionary<string, string>()
{
{ "Accept","text/html, */*; q=0.01" },
{ "Referer", "https://store.mall.autohome.com.cn/83106681.html"},
{ "Cache-Control","no-cache" },
{ "Connection","keep-alive" },
{ "Content-Type","application/x-www-form-urlencoded; charset=UTF-8" },
{ "User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"} } };
3.8构造Request
因为我们所抓取到的接口必须用POST,如果是GET请求则这一部可以省略,参数就放在PostBody就行。
List<Request> resList = new List<Request>();
for (int i = ; i <= ; i++)
{
Request res = new Request();
res.PostBody = $"id=7&j=%7B%22createMan%22%3A%2218273159100%22%2C%22createTime%22%3A1518433690000%2C%22row%22%3A5%2C%22siteUserActivityListId%22%3A8553%2C%22siteUserPageRowModuleId%22%3A84959%2C%22topids%22%3A%22%22%2C%22wherePhase%22%3A%221%22%2C%22wherePreferential%22%3A%220%22%2C%22whereUsertype%22%3A%220%22%7D&page={i}&shopid=83106681";
res.Url = "https://store.mall.autohome.com.cn/shop/ajaxsitemodlecontext.jtml";
res.Method = System.Net.Http.HttpMethod.Post; resList.Add(res);
}
3.9构造爬虫并且执行
var spider = Spider.Create(site, new QueueDuplicateRemovedScheduler(), new AutoHomeProcessor())
.AddStartRequests(resList.ToArray())
.AddPipeline(new AutoHomePipe());
spider.ThreadNum = ;
spider.Run();
3.10执行结果
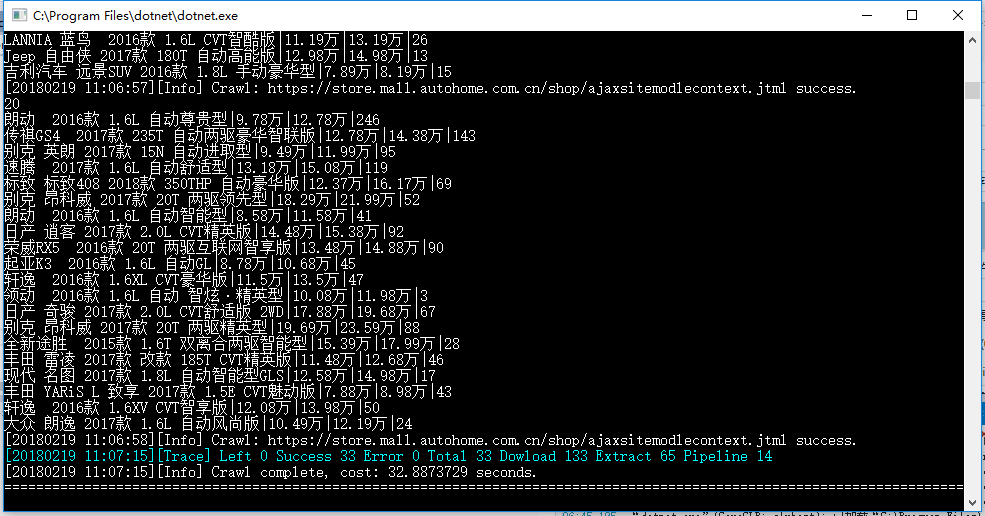
四、下次预告
接下来我会将对商品的详情页数据(包括车型参数配置之类的)进行抓取,接口已经抓取到了,还在思考如果更加便捷获取到商品id,因为目前来看商品id是存储在页面的js全局变量中,抓取起来比较费劲。
五、总结
.Net 相对于别的语言感觉并不是那么活跃,DotnetSpider虽然时间不长,但是希望园子里面大伙都用起来,让他不断的发展,让我们的.Net能够更好的发展。
第一次写博客,时间比较仓促,还有很多不足的地方,欢迎拍砖。
祝大家新年快乐
2018年2月19日
汽车之家店铺数据抓取 DotnetSpider实战[一]的更多相关文章
- 汽车之家店铺数据抓取 DotnetSpider实战
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- 汽车之家店铺商品详情数据抓取 DotnetSpider实战[二]
一.迟到的下期预告 自从上一篇文章发布到现在,大约差不多有3个月的样子,其实一直想把这个实战入门系列的教程写完,一个是为了支持DotnetSpider,二个是为了.Net 社区发展献出一份绵薄之力,这 ...
- 汽车之家汽车品牌Logo信息抓取 DotnetSpider实战[三]
一.正题前的唠叨 第一篇实战博客,阅读量1000+,第二篇,阅读量200+,两篇文章相差近5倍,这个差异真的令我很费劲,截止今天,我一直在思考为什么会有这么大的差距,是因为干货变少了,还是什么原因,一 ...
- Python爬虫入门教程 23-100 石家庄链家租房数据抓取
1. 写在前面 作为一个活跃在京津冀地区的开发者,要闲着没事就看看石家庄这个国际化大都市的一些数据,这篇博客爬取了链家网的租房信息,爬取到的数据在后面的博客中可以作为一些数据分析的素材. 我们需要爬取 ...
- Python爬虫入门教程石家庄链家租房数据抓取
1. 写在前面 这篇博客爬取了链家网的租房信息,爬取到的数据在后面的博客中可以作为一些数据分析的素材.我们需要爬取的网址为:https://sjz.lianjia.com/zufang/ 2. 分析网 ...
- 美团店铺数据抓取 token解析与生成
美团.点评网的token都是用一套加密算法,实际上就是个gzip压缩算法.加密了2次,第一次是加密了个sign值,然后把sign值带进去参数中进行第二次加密,最后得出token 分析请求 打开上海美食 ...
- Python 爬取汽车之家口碑数据
本文仅供学习交流使用,如侵立删!联系方式见文末 汽车之家口碑数据 2021.8.3 更新 增加用户信息参数.认证车辆信息等 2021.3.24 更新 更新最新数据接口 2020.12.25 更新 添加 ...
- 大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫
大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫 大众点评的反爬虫手段有那些: 封ip,封账号,字体库反爬虫,css文字映射,图形滑动验证码 这个图片是滑动验证码,访问频率高的话,会出 ...
- UiPath数据抓取Data Scraping的介绍和使用
一.数据抓取(Data Scraping)的介绍 使用截据抓取使您可以将浏览器,应用程序或文档中的结构化数据提取到数据库,.csv文件甚至Excel电子表格中. 二.Data Scraping在UiP ...
随机推荐
- JXLS 2.4.0系列教程(二)——循环导出一个链表的数据
请务必先看上一篇文章,本文在上一篇文章的代码基础上修改而成. JXLS 2.4.0系列教程(一)--最简单的模板导出 上一篇文章我们介绍了JXLS和模板导出最简单的应用,现在我们要更进一步,介绍在模板 ...
- webpack的安装与使用
在安装 Webpack 前,你本地环境必须已安装nodejs. 可以使用npm安装,当然由于 npm 安装速度慢,也可以使用淘宝的镜像及其命令 cnpm,安装使用介绍参照:使用淘宝 NPM 镜像. 使 ...
- Spark性能调优之资源分配
Spark性能调优之资源分配 性能优化王道就是给更多资源!机器更多了,CPU更多了,内存更多了,性能和速度上的提升,是显而易见的.基本上,在一定范围之内,增加资源与性能的提升,是成正比的:写完了 ...
- destoon 开启邮箱
- "Cache-control”常见的取值private、no-cache、max-age、must-revalidate及其用意
http://www.cnblogs.com/kaima/archive/2009/10/13/1582337.html 网页的缓存是由HTTP消息头中的"Cache-control&quo ...
- 关于eclipse 与OpenCV 配置频繁报错的问题总结Program "C:/SDK/android-ndk-xxx/ndk-build.cmd" is not found in PATH报错的解决!
2018-01-3116:58:12 Program "C:/SDK/android-ndk-r8/ndk-build.cmd" is not found in PATH 今天这一 ...
- java面向对象的三大特性——封装
封装 封装从字面上来理解就是包装的意思,专业点就是信息隐藏,是指利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体,数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节 ...
- 反应堆模式(reactor)
在提到高性能服务器编程的时候肯定有听过reactor模式,如果只是简单的写一个服务器和客户端建立连接的程序来熟悉一下使用socket函数编程,一般这种情况都是同步方式实现的,服务器阻塞等待客户端的连接 ...
- 【深度学习系列】迁移学习Transfer Learning
在前面的文章中,我们通常是拿到一个任务,譬如图像分类.识别等,搜集好数据后就开始直接用模型进行训练,但是现实情况中,由于设备的局限性.时间的紧迫性等导致我们无法从头开始训练,迭代一两百万次来收敛模型, ...
- 自己写的一个tomcat发布脚本
闲来无事,就自己写一个shell脚本,方便自己以后在服务器上部署tomcat下的项目.我本地用maven打包,然后每次都要人工去切换一堆堆目录,有点繁琐,所以我写了下面的shell脚本. #! /bi ...