Hive metastore表结构设计分析
今天总结下,Hive metastore的结构设计。什么是metadata呢,对于它的描述,可以理解为数据的数据,主要是描述数据的属性的信息。它是用来支持如存储位置、历史数据、资源查找、文件记录等功能。元数据算是一种电子式目录。为了达到编制目录的目的,必须在描述并收藏数据的内容或特色,进而达成协助数据检索的目的。
那么我们从hive metastore的表结构设计开始:
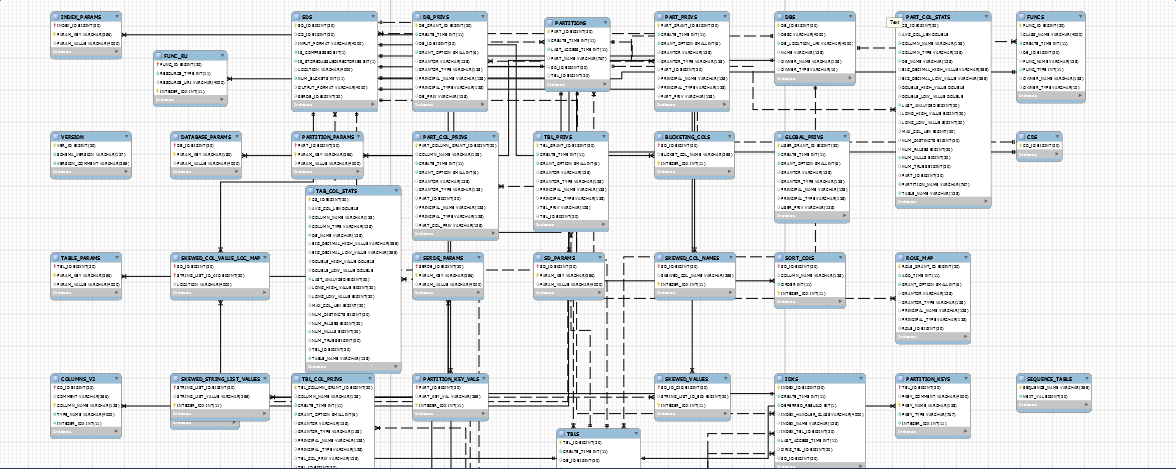
看到后,是不是有一种想死的冲动?没错,我也想死,但是我们可以一点一点的看,也会有理解错误,但这都是在我们通向精通的路途之上,不是么?那么我们围绕着几个核心主表进行分析。
1、DBS 表 Columns:DB_ID、DESC、DB_LOCATION_URI、NAME、OWNER_NAME、OWNER_TYPE
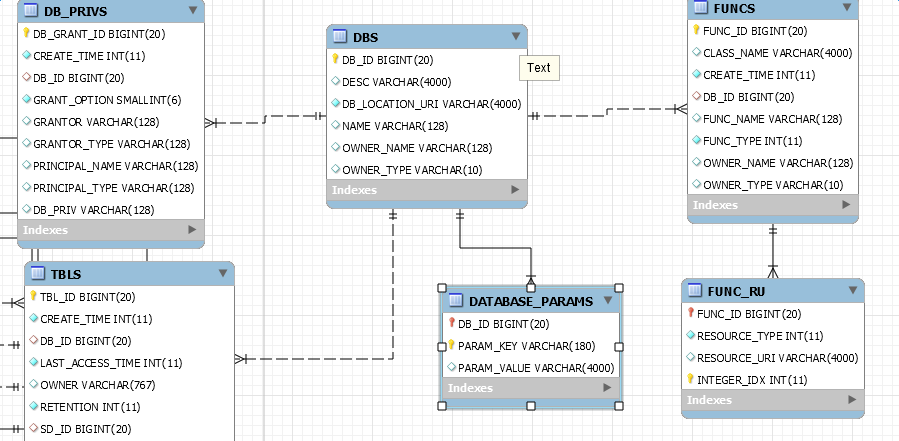
DBS 表记录基本的db信息,其中DB_ID为其主键,同时也是FUNC_RU、FUNCS、DB_PRIVS、DATABASE_PARAMS、以及TBLS的外键。
一般来说,在hive meta初始化时都会自动创建一个名叫default的库,随后通过业务发展以及数据治理等需求,可进行不同业务域库的划分。
FUNC 表是用来存储udf的基本信息,一个UDF只能对应一个库下的表。FUNC_RU表,用于存储该udf的类型及指向的路径。
DB_PRIVS 表记录该DB下的权限记录信息,具体没怎么研究,因为现在更多的集成开源的类似于sentry、range等成熟的权限框架。
DATABASE_PARAMS 表记录DB的一些扩展信息,便于进行特殊属性的扩展。
TBLS 表自然是记录该DB下的所有Table信息。对应唯一的DB_ID。
2、TBLS 表 Columns:TBL_ID、CREATE_TIME、DB_ID,LAST_ACCESS_TIME、OWNER、RETENTION、SD_ID、TBL_NAME、TBL_TYPE、VIEW_EXPANDED_TEXT、VIEW_ORIGNAL_TEXT
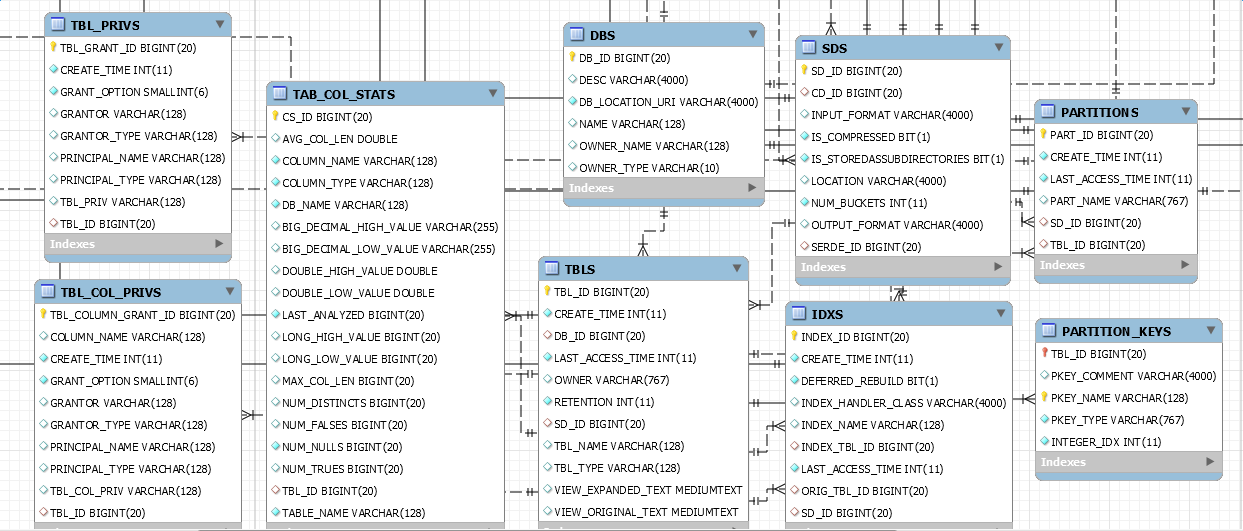
首先,TBLS表,这个表主要记录了table的一些基本信息,包括表名、创建时间、类型,以及SD_ID等信息。tbl_id为TBLS的主键,同时也是TABLE_PARAMS、TBL_COL_PRIVS、IDXS、TBL_PRIVS、SDS、PARTITIONS、PARTITION_KEYS、TAB_COL_STATS表的外键。
每个TBLS都对应唯一的DB_ID,取决于你在哪个db下创建的表。在创建表写入meta的同时,也会创建相应的物理路径。同时会在SDS表中加入DDL时设置的input output、表的location以及SERDE信息(具体下面再说)
TBL_PRIVS、TBL_COL_PRIVS表记录该hive表的表及列权限认证信息。PARTITIONS表记录该表的DDL分区的信息,对于PARTITION_KEYS以及PARTITION_VALUES都是用于PartName的拼接获取。(可查看本博客 hive metadata源码解析)
(IDXS 与 TAB_COL_STATS还没有深入研究,后续添加)
3、PARTITIONS 表 Columns:PART_ID、CREATE_TIME、LAST_ACCESS_TIME、PART_NAME、SD_ID、TBL_ID

PARTITIONS表,通过表名也能才想到,它是partition分区存储的元数据信息。
PART_ID为PARTITIONS表的主键,同时也是PART_COL_STATS、PART_PRIVS、PARTITION_KEY_VALS、PARTITION_PARAMS、DATABASE_PARAMS表的外键。
Partition表在metastore中是相当重要的表,关系到partition的元数据存取(具体可参考本博客hive metastore partition篇)
4、SDS 表 Columns:SD_ID、CD_ID、INPUT_FORMAT、IS_COMPRESSED、IS_STOREDASSUBDIRECTORIES、LOCATION\NUM_BUCKETS、OUTPUT_FORMAT、SERDE_ID
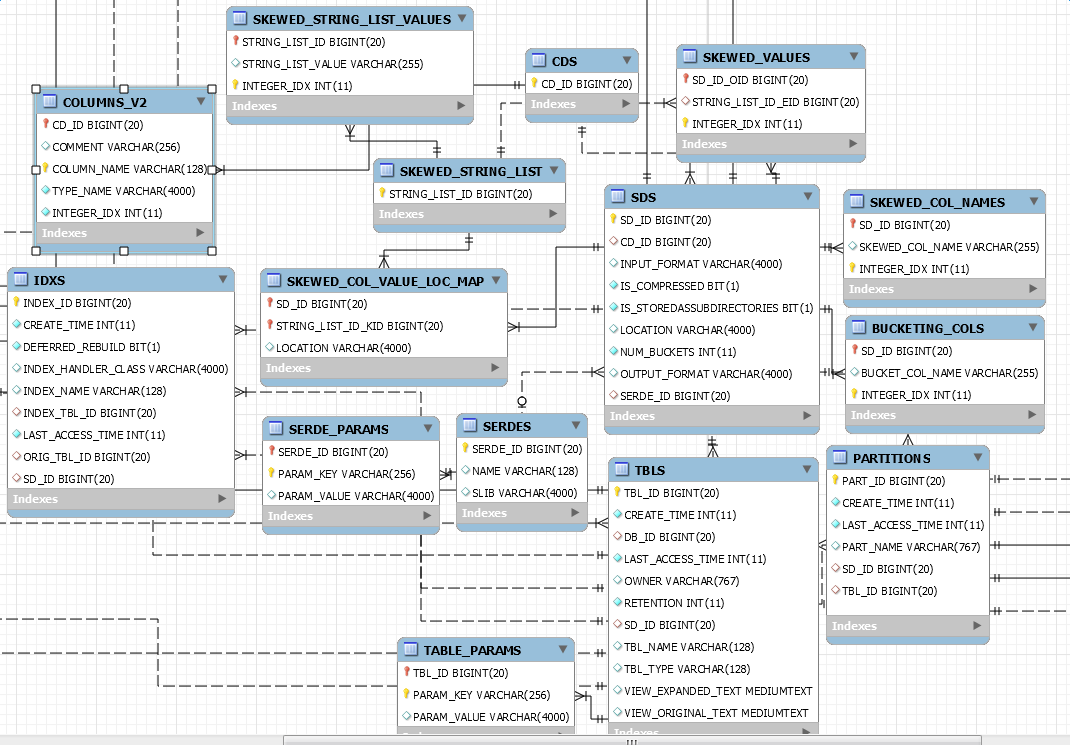
SDS表主要包含计算引擎运行时需要的input与output 、location路径以及序列化的class信息。SD_ID为该表的主键,同时也是PARTITIONS、BUCKETING_COLS、SKEWD_COL_NAMES、SD_PARAMS、SORT_COLS、SKEWED_VALUES、IDXS的外键。
今天大概先梳理到这里,后面我们从代码层面详细分析。新年快乐~o(* ̄︶ ̄*)o~
Hive metastore表结构设计分析的更多相关文章
- MySQL和hive对比表结构脚本
#!/bin/bash source /etc/profile runlog='/tmp/zewei/check_schema_log' hive_database_schema=/tmp/hive_ ...
- 读取hive的表结构,生成带comment的视图建表语句
### 读取hive的表结构,生成带comment的视图建表语句 # 读取配置文件中的表并进行遍历 grep -v '^#' tablesFile|while read tableName do st ...
- hive 查看表结构和属性
1.查看数据库/表 show databases/tables; 2.切换数据库 use database_name; 3.查看表结构 desc table_name; 4.查看表详细属性 desc ...
- Hive 修改表结构常用操作
添加列 add columns alter table table_name add columns (id int comment '主键ID' ) ; 默认在表所有字段之后,分区字段之前. 替换 ...
- Hive改表结构的两个坑|避坑指南
Hive在大数据中可能是数据工程师使用的最多的组件,常见的数据仓库一般都是基于Hive搭建的,在使用Hive时候,遇到了两个奇怪的现象,今天给大家聊一下,以后遇到此类问题知道如何避坑! 坑一:改变字段 ...
- hive建表结构
drop table dw.fct_so;create table dw.fct_so(so_id bigint comment '订单ID',parent_so_id bigint comment ...
- Hive metastore整体代码分析及详解
从上一篇对Hive metastore表结构的简要分析中,我再根据数据设计的实体对象,再进行整个代码结构的总结.那么我们先打开metadata的目录,其目录结构: 可以看到,整个hivemeta的目录 ...
- hive表信息查询:查看表结构、表操作等--转
原文地址:http://www.aboutyun.com/forum.PHP?mod=viewthread&tid=8590&highlight=Hive 问题导读:1.如何查看hiv ...
- hive表信息查询:查看表结构、表操作等
转自网友的,主要是自己备份下 有时候不记得! 问题导读:1.如何查看hive表结构?2.如何查看表结构信息?3.如何查看分区信息?4.哪个命令可以模糊搜索表 1.hive模糊搜索表 show tabl ...
随机推荐
- Spark性能调优之解决数据倾斜
Spark性能调优之解决数据倾斜 数据倾斜七种解决方案 shuffle的过程最容易引起数据倾斜 1.使用Hive ETL预处理数据 • 方案适用场景:如果导致数据倾斜的是Hive表.如果该Hiv ...
- Spark_总结一
Spark_总结一 1.Spark介绍 1.1什么是Spark? Apache Spark是一个开源的集群计算框架,使数据计算更快(高效运行,快速开发) 1.2Spa ...
- 《You dont know JS》值相关总结
值 一:和数组相关的几个需要关注的点 数组可以容纳任何类型的值. 数组声明时不需要预先设置大小.可以动态改变. 使用delete运算符可以将数组中的某个元素删除,但是这个操作不会改变数组的length ...
- 一个域名最多能对应几个IP地址?,一个IP地址可以绑定几个域名?
一个域名最多能对应几个IP地址?,一个IP地址可以绑定几个域名?谢谢 xikeboy | 浏览 31055 次 推荐于2016-04-24 14:21:14 最佳答案 1.也就是说通常情况下一个域名同 ...
- MySQL改写子查询成Join
有时用别的方式而不是子查询可以获得更高的性能 : For example: SELECT * FROM t1 WHERE id IN (SELECT id FROM t2); 改写: SELECT D ...
- 使用WinDbg获取SSDT函数表对应的索引再计算得出地址
当从Ring3进入Ring0的时候会将所需要的SSDT索引放入到寄存器EAX中去,所以我们这里通过EAX的内容得到函数在SSDT中的索引号,然后计算出它的地址首先打开WinDbug,我们以函数ZwQu ...
- python_如何对字典进行排序?
案例: 某班英语成绩以字典的形式存储为: {'lili':78, 'jin':50, 'liming': 30, ......} 依据成绩高低,进行学生成绩排名 如何对字典排序? 方法1: #!/us ...
- 爬取知名社区技术文章_items_2
item中定义获取的字段和原始数据进行处理并合法化数据 #!/usr/bin/python3 # -*- coding: utf-8 -*- import scrapy import hashlib ...
- 【Python3之迭代器,生成器】
一.可迭代对象和迭代器 1.迭代的概念 上一次输出的结果为下一次输入的初始值,重复的过程称为迭代,每次重复即一次迭代,并且每次迭代的结果是下一次迭代的初始值 注:循环不是迭代 while True: ...
- RESTClient
RESTClient是Mozilla Firefox一个用于测试http请求插件. 1.打开火狐扩展搜索RESTClient进行安装并重启浏览器. 2.重启后可以在Mozilla Firefox地址栏 ...