HashMap并发导致死循环 CurrentHashMap
为何出现死循环简要说明
HashMap闭环的详细原因
cocurrentHashMap的底层机制
为何出现死循环简要说明
HashMap是非线程安全的,在并发场景中如果不保持足够的同步,就有可能在执行HashMap.get时进入死循环,将CPU的消耗到100%。
HashMap采用链表解决Hash冲突。因为是链表结构,那么就很容易形成闭合的链路,这样在循环的时候只要有线程对这个HashMap进行get操作就会产生死循环,
单线程情况下,只有一个线程对HashMap的数据结构进行操作,是不可能产生闭合的回路的。
只有在多线程并发的情况下才会出现这种情况,那就是在put操作的时候,如果size>initialCapacity*loadFactor,hash表进行扩容,那么这时候HashMap就会进行rehash操作,随之HashMap的结构就会很大的变化。很有可能就是在两个线程在这个时候同时触发了rehash操作,产生了闭合的回路。
推荐使用currentHashMap
多线程下[HashMap]的问题:
1、多线程put操作后,get操作导致死循环。
2、多线程put非NULL元素后,get操作得到NULL值。
3、多线程put操作,导致元素丢失。
HashMap闭环的详细原因
Java的HashMap是非线程安全的,所以在并发下必然出现问题,以下做详细的解释:
问题的症状
从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题。因为考虑到程序性能,所以需要变成多线程的,于是,变成多线程后到了线上,发现程序经常占了100%的CPU,查看堆栈,你会发现程序都Hang在了HashMap.get()这个方法上了,重启程序后问题消失。但是过段时间又会来。而且,这个问题在测试环境里可能很难重现。
我们简单的看一下我们自己的代码,我们就知道HashMap被多个线程操作。而Java的文档说HashMap是非线程安全的,应该用ConcurrentHashMap。
Hash表数据结构
简单地说一下HashMap这个经典的数据结构。
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷(可参看《Hash Collision DoS 问题》)。
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,这样一来,整个Hash表里的无素都需要被重算一遍。这叫rehash,这个成本相当的大。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。
Put一个Key,Value对到Hash表中:
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null;
}
检查容量是否超标
void addEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize(2 * table.length);
}
新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
迁移的源代码,注意高亮处:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash的过程
画了个图做了个演示。
- 我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
- 最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
- 接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程
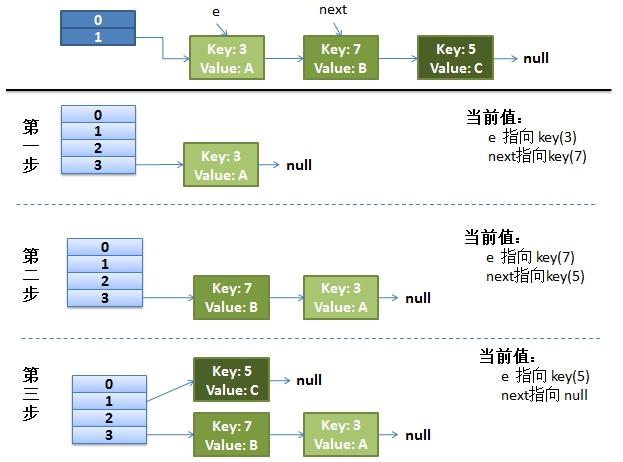
并发下的Rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
- do {
- Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
- int i = indexFor(e.hash, newCapacity);
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- } while (e != null);
而我们的线程二执行完成了。于是我们有下面的这个样子。
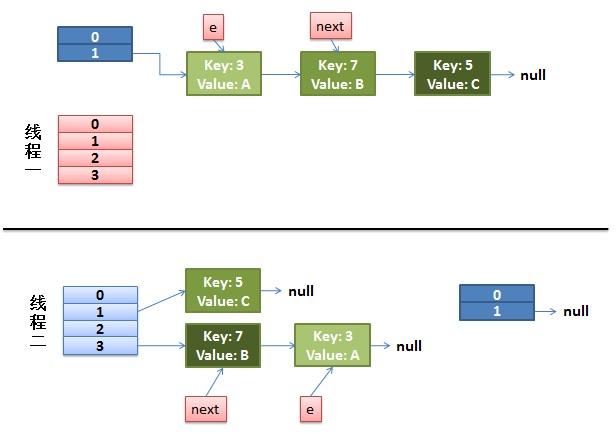
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
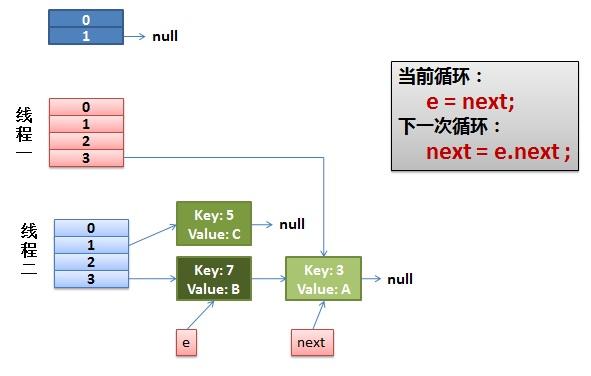
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
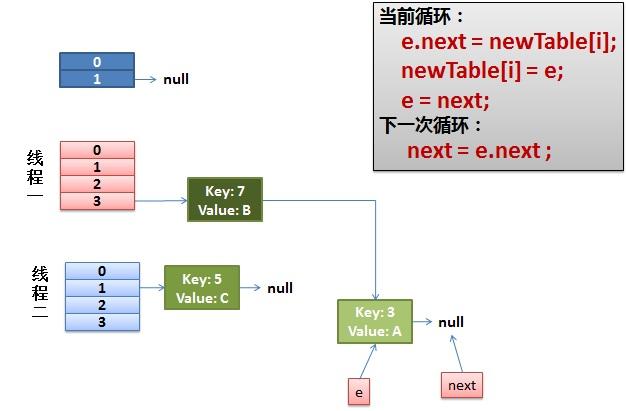
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
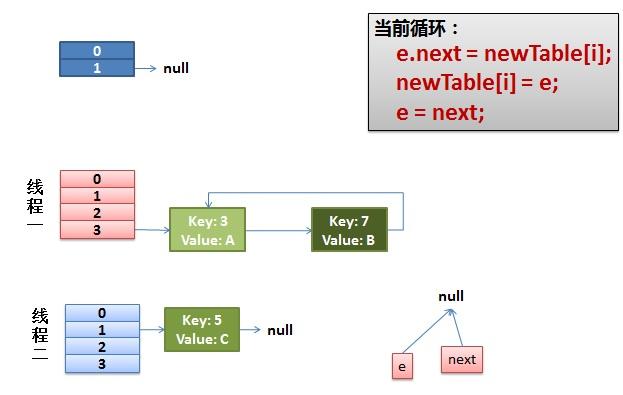
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
其它
有人把这个问题报给了Sun,不过Sun不认为这个是一个问题。因为HashMap本来就不支持并发。要并发就用ConcurrentHashmap
我在这里把这个事情记录下来,只是为了让大家了解并体会一下并发环境下的危险。
cocurrentHashMap的底层机制
ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细。只有在求size等操作时才需要锁定整个表。而在迭代时,ConcurrentHashMap使用了不同于传统集合的快速失败迭代器的弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。
效率低下的HashTable容器
Hashtable继承的是Dictionary(Hashtable是其唯一公开的子类),HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
Hashtable的实现方式---锁整个hash表;而ConcurrentHashMap的实现方式---锁桶(或段)
ConcurrentHashMap的锁分段技术
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。

从上面看出,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),并发能力大大提高。

ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
三、ConcurrentHashMap实现原理
锁分离 (Lock Stripping)
ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。同样当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里"按顺序"是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。不变性是多线程编程占有很重要的地位,下面还要谈到。
final Segment<K,V>[] segments;
不变(Immutable)和易变(Volatile)
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。如果使用传统的技术,如HashMap中的实现,如果允许可以在hash链的中间添加或删除元素,读操作不加锁将得到不一致的数据。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,其结构如下所示:
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
可以看到除了value不是final的,其它值都是final的,为了防止链表结构被破坏,出现ConcurrentModification的情况。这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next引用值,所有的节点的修改只能从头部开始。对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点,为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。
ConcurrentHashMap的初始化
下面我们来结合源代码来具体分析一下ConcurrentHashMap的实现,先看下初始化方法:
- public ConcurrentHashMap(int initialCapacity,
- float loadFactor, int concurrencyLevel) {
- if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
- throw new IllegalArgumentException();
- if (concurrencyLevel > MAX_SEGMENTS)
- concurrencyLevel = MAX_SEGMENTS;
- // Find power-of-two sizes best matching arguments
- int sshift = 0;
- int ssize = 1;
- while (ssize < concurrencyLevel) {
- ++sshift;
- ssize <<= 1;
- }
- segmentShift = 32 - sshift;
- segmentMask = ssize - 1;
- this.segments = Segment.newArray(ssize);
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- int c = initialCapacity / ssize;
- if (c * ssize < initialCapacity)
- ++c;
- int cap = 1;
- while (cap < c)
- cap <<= 1;
- for (int i = 0; i < this.segments.length; ++i)
- this.segments[i] = new Segment<K,V>(cap, loadFactor);
- }
CurrentHashMap的初始化一共有三个参数,一个initialCapacity,表示初始的容量,一个loadFactor,表示负载参数,最后一个是concurrentLevel,代表ConcurrentHashMap内部的Segment的数量,ConcurrentLevel一经指定,不可改变,后续如果ConcurrentHashMap的元素数量增加导致ConrruentHashMap需要扩容,ConcurrentHashMap不会增加Segment的数量,而只会增加Segment中链表数组的容量大小,这样的好处是扩容过程不需要对整个ConcurrentHashMap做rehash,而只需要对Segment里面的元素做一次rehash就可以了。
整个ConcurrentHashMap的初始化方法还是非常简单的,先是根据concurrentLevel来new出Segment,这里Segment的数量是不大于concurrentLevel的最大的2的指数,就是说Segment的数量永远是2的指数个,这样的好处是方便采用移位操作来进行hash,加快hash的过程。接下来就是根据intialCapacity确定Segment的容量的大小,每一个Segment的容量大小也是2的指数,同样使为了加快hash的过程。
这边需要特别注意一下两个变量,分别是segmentShift和segmentMask,这两个变量在后面将会起到很大的作用,假设构造函数确定了Segment的数量是2的n次方,那么segmentShift就等于32减去n,而segmentMask就等于2的n次方减一。
ConcurrentHashMap的get操作
前面提到过ConcurrentHashMap的get操作是不用加锁的,我们这里看一下其实现:
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
segmentFor这个函数用于确定操作应该在哪一个segment中进行,几乎对ConcurrentHashMap的所有操作都需要用到这个函数,我们看下这个函数的实现:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
这个函数用了位操作来确定Segment,根据传入的hash值向右无符号右移segmentShift位,然后和segmentMask进行与操作,结合我们之前说的segmentShift和segmentMask的值,就可以得出以下结论:假设Segment的数量是2的n次方,根据元素的hash值的高n位就可以确定元素到底在哪一个Segment中。
在确定了需要在哪一个segment中进行操作以后,接下来的事情就是调用对应的Segment的get方法:
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
get操作不需要锁。第一步是访问count变量,这是一个volatile变量,由于所有的修改操作在进行结构修改时都会在最后一步写count变量,通过这种机制保证get操作能够得到几乎最新的结构更新。对于非结构更新,也就是结点值的改变,由于HashEntry的value变量是volatile的,也能保证读取到最新的值。接下来就是对hash链进行遍历找到要获取的结点,如果没有找到,直接访回null。对hash链进行遍历不需要加锁的原因在于链指针next是final的。但是头指针却不是final的,这是通过getFirst(hash)方法返回,也就是存在table数组中的值。这使得getFirst(hash)可能返回过时的头结点,例如,当执行get方法时,刚执行完getFirst(hash)之后,另一个线程执行了删除操作并更新头结点,这就导致get方法中返回的头结点不是最新的。这是可以允许,通过对count变量的协调机制,get能读取到几乎最新的数据,虽然可能不是最新的。要得到最新的数据,只有采用完全的同步。
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
最后,如果找到了所求的结点,判断它的值如果非空就直接返回,否则在有锁的状态下再读一次。这似乎有些费解,理论上结点的值不可能为空,这是因为put的时候就进行了判断,如果为空就要抛NullPointerException。空值的唯一源头就是HashEntry中的默认值,因为HashEntry中的value不是final的,非同步读取有可能读取到空值。仔细看下put操作的语句:tab[index] = new HashEntry<K,V>(key, hash, first, value),在这条语句中,HashEntry构造函数中对value的赋值以及对tab[index]的赋值可能被重新排序,这就可能导致结点的值为空。这种情况应当很罕见,一旦发生这种情况,ConcurrentHashMap采取的方式是在持有锁的情况下再读一遍,这能够保证读到最新的值,并且一定不会为空值。
因为实际上put、remove等操作也会更新count的值,所以当竞争发生的时候,volatile的语义可以保证写操作在读操作之前,也就保证了写操作对后续的读操作都是可见的,这样后面get的后续操作就可以拿到完整的元素内容。
ConcurrentHashMap的put操作
看完了get操作,再看下put操作,put操作的前面也是确定Segment的过程,直接看关键的segment的put方法:
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); //加锁
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash(); //看是否需要rehash
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index]; //确定链表头部的位置
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) { //如果存在,替换掉value
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount; //修改modCount和count?
tab[index] = new HashEntry<K,V>(key, hash, first, value); //创建一个新的结点并添加到hash链的头部
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
首先对Segment的put操作是加锁完成的,然后在第五行,如果Segment中元素的数量超过了阈值(由构造函数中的loadFactor算出)这需要进行对Segment扩容,并且要进行rehash。
第8和第9行的操作就是getFirst的过程,确定链表头部的位置。
第11行这里的这个while循环是在链表中寻找和要put的元素相同key的元素,如果找到,就直接更新更新key的value,如果没有找到,则进入21行这里,生成一个新的HashEntry并且把它加到整个Segment的头部,然后再更新count的值。
修改操作还有putAll和replace。putAll就是多次调用put方法。replace甚至不用做结构上的更改,实现要比put和delete要简单得多.
ConcurrentHashMap的remove操作
Remove操作的前面一部分和前面的get和put操作一样,都是定位Segment的过程,然后再调用Segment的remove方法:
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next; //空白行之前的行主要是定位到要删除的节点e
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
整个操作是先定位到段,然后委托给段的remove操作。当多个删除操作并发进行时,只要它们所在的段不相同,它们就可以同时进行。下面是Segment的remove方法实现
首先remove操作也是确定需要删除的元素的位置,HashEntry中的next是final的,一经赋值以后就不可修改,在定位到待删除元素的位置以后,程序就将待删除元素前面的那一些元素全部复制一遍,然后再一个一个重新接到链表上去.
将e前面的结点复制一遍,尾结点指向e的下一个结点。e后面的结点不需要复制,它们可以重用.
假设链表中原来的元素如上图所示,现在要删除元素3,那么删除元素3以后的链表就如下图所示:
ConcurrentHashMap的size操作
在前面的章节中,我们涉及到的操作都是在单个Segment中进行的,但是ConcurrentHashMap有一些操作是在多个Segment中进行,比如size操作,ConcurrentHashMap的size操作也采用了一种比较巧的方式,来尽量避免对所有的Segment都加锁。
前面我们提到了一个Segment中的有一个modCount变量,代表的是对Segment中元素的数量造成影响的操作的次数,这个值只增不减,size操作就是遍历了两次Segment,每次记录Segment的modCount值,然后将两次的modCount进行比较,如果相同,则表示期间没有发生过写入操作,就将原先遍历的结果返回,如果不相同,则把这个过程再重复做一次,如果再不相同,则就需要将所有的Segment都锁住,然后一个一个遍历了.
参考:http://www.iteye.com/topic/344876
HashMap并发导致死循环 CurrentHashMap的更多相关文章
- HashMap resize导致死循环
原文链接:https://blog.csdn.net/hll174/article/details/50915346 问题的症状 从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当 ...
- java 基础 HashMap 并发扩容问题
存入的数据过多的时候,尤其是需要扩容的时候,在并发情况下是很容易出现问题. resize函数: void resize(int newCapacity) { Entry[] oldTable = ta ...
- Java之HashMap在多线程情况下导致死循环的问题
PS:不得不说Java编程思想这本书是真心强大.. 学习内容: 1.HashMap<K,V>在多线程的情况下出现的死循环现象 当初学Java的时候只是知道HashMap<K,V& ...
- Java HashMap并发死循环
在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造成Race Condition,从而导致死循环.这个事情我4. ...
- HashMap导致死循环问题
虽然我推测是链表形成闭环,但 没有去证明过.从网上找了一下: http://blog.csdn.net/autoinspired/archive/2008/07/16/2662290.aspx 里面也 ...
- EntityFramework Core并发导致显示插入主键问题
前言 之前讨论过EntityFramework Core中并发问题,按照官网所给并发冲突解决方案以为没有什么问题,但是在做单元测试时发现too young,too siimple,下面我们一起来看看. ...
- drools规则引擎中易混淆语法分析_相互触发导致死循环分析
整理了下最近在项目中使用drools出现的问题,幸好都在开发与测试阶段解决了,未波及到prod. 首先看这样两条规则: /** * 规则1_set默认利率a */ rule "rate_de ...
- EntityFramework Core并发导致显式插入主键问题
前言 之前讨论过EntityFramework Core中并发问题,按照官网所给并发冲突解决方案以为没有什么问题,但是在做单元测试时发现too young,too simple,下面我们一起来看看. ...
- jquery validate submitHandler 提交导致死循环
dom对像的提交form.submit();和jquery对像的提交$('').submit();功能上是没有什么区别的.但是如果用了jquery validate插件,提交时这二个就区别大了.$(' ...
随机推荐
- mybatis-spring最新版下载地址
mybatis-spring最新版下载地址: http://mvnrepository.com/artifact/org.mybatis/mybatis-spring/1.2.3 mybatis-sp ...
- Node.js在任意目录下使用express命令‘不是内部或外部命令’解决方法
1.一开始我只能在nodejs全局目录下使用express命令建一个新的项目,建在其他任意一个目录命令行都会提示"不是内部或外部命令",导致目录会乱,目录如下. 2.尝试了一会,发 ...
- 基于 xorm 的服务端框架 XGoServer
作者:林冠宏 / 指尖下的幽灵 掘金:https://juejin.im/user/587f0dfe128fe100570ce2d8 博客:http://www.cnblogs.com/linguan ...
- 小z的袜子
传送门 题目描述 作为一个生活散漫的人,小Z每天早上都要耗费很久从一堆五颜六色的袜子中找出一双来穿.终于有一天,小Z再也无法忍受这恼人的找袜子过程,于是他决定听天由命-- 具体来说,小Z把这N只袜子从 ...
- 开发JQuery插件(转)
教你开发jQuery插件(转) 阅读目录 基本方法 支持链式调用 让插件接收参数 面向对象的插件开发 关于命名空间 关于变量定义及命名 压缩的好处 工具 GitHub Service Hook 原 ...
- centos配置单网卡为Trunk模式
单网卡配置多IP(trunk模式)操作标准 1.linux的单网卡配置多IP的操作 下面为linux系统单网卡配置多IP(trunk模式)的操作步骤,系统平台为centos5.5.全部操作完成后,将实 ...
- crontab 定时任务守护程序,停止服务器时出现 job for * canceled
(1)首先要在程序启动的时候加入定时任务到crontab #! /bin/shmkdir -p /home/apps/components/ams/ 2>/dev/nullcp ./amswat ...
- vscode使用笔记
将vue文件添加成html文件识别 "files.associations": {"*.vue": "html"} 插件 view in b ...
- UVW源码漫谈(三)
咱们继续看uvw的源码,这次看的东西比较多,去除底层的一些东西,很多代码都是连贯的,耦合度也比较高了.主要包括下面几个文件的代码: underlying_type.hpp resource.hpp l ...
- WebService的学习
这篇文章不错,直接转了 http://blog.csdn.net/terryzero/article/details/5976638#comments