requests+多进程poll+pymongo实现抓取小说
今天看着有个很吸引人的小说作品信息:一家只在深夜开门营业的书屋,欢迎您的光临。
作为东野奎吾《深夜食堂》漫画的fans,看到这个标题按捺不住我的好奇心........
所以我又抓下来了,总共52章,下面有源码,写的有点乱哦,凑合看看,关键看结果,@~@。。。。
代码写完,几秒钟就抓取下来,比下载效率高不少,小激动~~~~~~
readme>>>环境python2,我的python2还有多长寿命;其他內库依赖见代码体现
# coding:utf-8 from multiprocessing import Pool
from lxml import etree
import requests
import pymongo def save_mongo(data):
client = pymongo.MongoClient('60.205.211.210',27017)
db = client.test
collection = db.shenyeshuwu
collection.insert(dict(data))
print('--------%s---------存储完毕' %data['title']) def parse_content(url):
resp = requests.get(url).content
html = etree.HTML(resp)
contents = html.xpath('//*[@id="j_chapterBox"]/div[2]/div/div[2]/p/text()|//*[@id="j_chapterBox"]/div[1]/div/div[2]/p/text()')
return contents def parse_html(html):
'''
[{
'title':title,
'url':url,
'content':content
}]
'''
page = etree.HTML(html)
article_url_list = page.xpath('//ul[@class="cf"]/li/a')
for i in article_url_list:
url = 'http:' + i.xpath('./@href')[0]
# print(url)
title = i.xpath('./text()')[0]
# print(title)
time = i.xpath('./@title')[0]
# print(time)
con = parse_content(url)
# print(con)
data = {
'url': url,
'title': title,
'time': time,
'content': con
}
print(data)
save_mongo(data) def get_page(url):
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
resp = requests.get(url,headers=header).content
parse_html(resp) def main():
url = 'https://book.qidian.com/info/1011335417#Catalog'
# get_page(url)
# 使用进程池 map(func,iterable)
pool = Pool(4)
# pool.map(parse_content,data)
pool.apply_async(get_page,args=(url,))
pool.close()
pool.join() if __name__ == '__main__':
main()
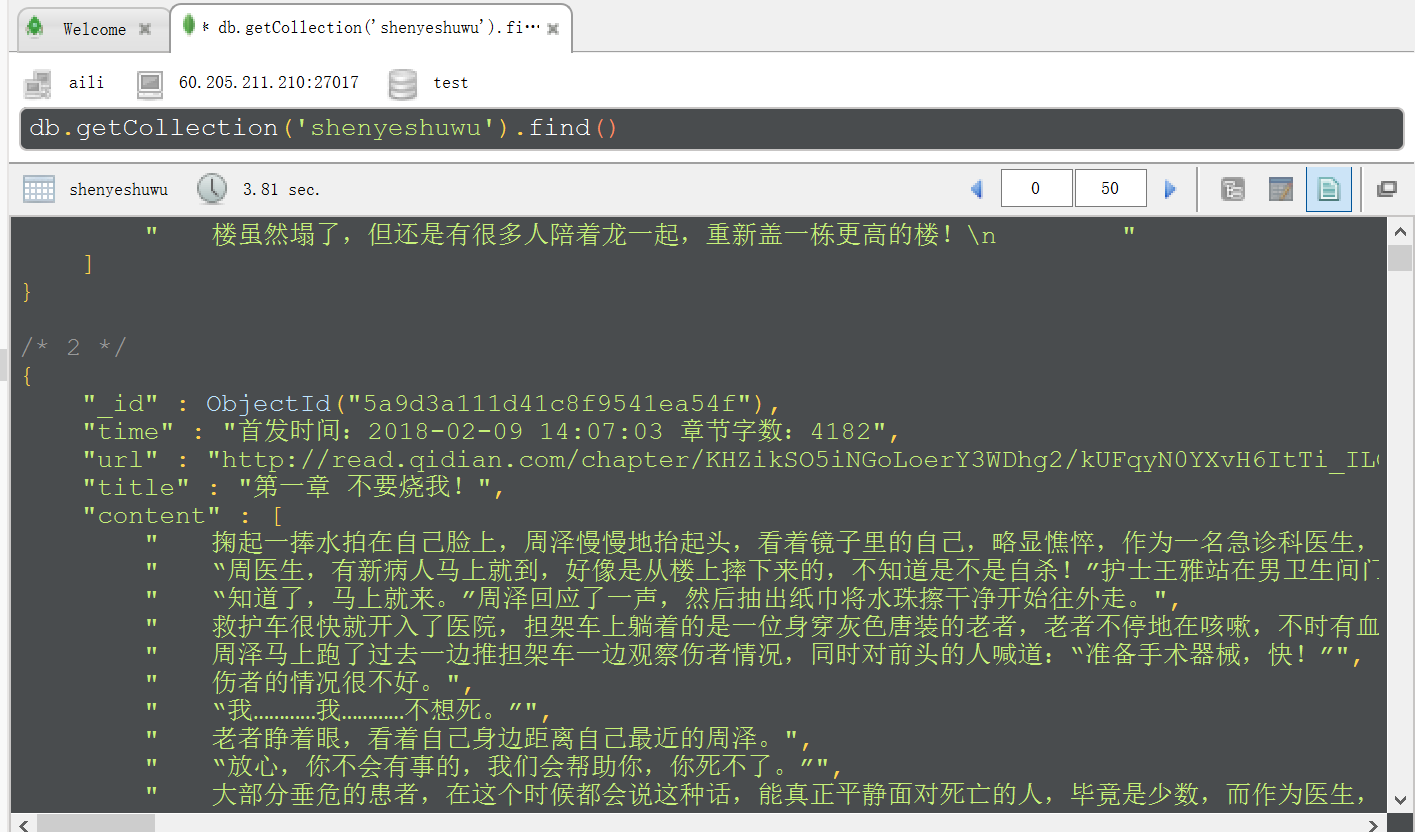
如往常,把截图展示下:
requests+多进程poll+pymongo实现抓取小说的更多相关文章
- C# 爬虫 抓取小说
心血来潮,想研究下爬虫,爬点小说. 通过百度选择了个小说网站,随便找了一本小书http://www.23us.so/files/article/html/13/13655/index.html. 1. ...
- C# 爬虫 正则、NSoup、HtmlAgilityPack、Jumony四种方式抓取小说
心血来潮,想爬点小说.通过百度选择了个小说网站,随便找了一本小说http://www.23us.so/files/article/html/13/13655/index.html. 1.分析html规 ...
- Python抓取小说
Python抓取小说 前言 这个脚本命令MAC在抓取小说写,使用Python它有几个码. 代码 # coding=utf-8 import re import urllib2 import chard ...
- scrapy抓取小说
用scrapy建立一个project,名字为Spider scrapy startproject Spider 因为之前一直用的是电脑自带的python版本,所以在安装scrapy时,有很多问题,也没 ...
- python requests 模拟登陆网站,抓取数据
抓取页面数据的时候,有时候我们需要登陆才可以获取页面资源,那么我们需要登陆以后才可以跳转到对应的资源页面,那么我们需要通过模拟登陆,登陆成功以后再次去抓取对应的数据. 首先我们需要通过手动方式来登陆一 ...
- python爬虫之抓取小说(逆天邪神)
2022-03-06 23:05:11 申明:自我娱乐,对自我学习过程的总结. 正文: 环境: 系统:win10, python版本:python3.10.2, 工具:pycharm. 项目目标: 实 ...
- Python 爬虫-抓取小说《盗墓笔记-怒海潜沙》
最近想看盗墓笔记,看了一下网页代码,竟然不是js防爬虫,那就用简单的代码爬下了一节: """ 爬取盗墓笔记小说-七星鲁王宫 """ from ...
- Python 爬虫-抓取小说《鬼吹灯之精绝古城》
想看小说<鬼吹灯之精绝古城>,可是网页版的好多广告,还要一页一页的翻,还无法复制,于是写了个小爬虫,保存到word里慢慢看. 代码如下: """ 爬取< ...
- jsoup使用样式class抓取数据时空格的处理
最近在研究用android和jsoup抓取小说数据,jsoup的使用可以参照http://www.open-open.com/jsoup/;在抓纵横中文网永生这本书的目录内容时碰到了问题, 永生的书简 ...
随机推荐
- 05_Javascript进阶第二天
String对象 res=str.charAt(1);//返回字符串中第n个字符(输出:i) res=str.charCodeAt(1);//返回第n个字符的ASCII编码(输出:105) res=S ...
- 【转】shell字符串截取
shell字符串的截取的问题: 一.Linux shell 截取字符变量的前8位,有方法如下: 1.expr substr “$a” 1 8 2.echo $a|awk ‘{print substr( ...
- Date对象和正则对象
1.Date对象 创建 var date1 = new Date(); var date2 = new Date(12983798123);//填一个毫秒值,应该是距离1970年1月1日.....多少 ...
- VUE 框架
一.什么是vue 它是一个构建用户界面的JAVASCRITPO框架 二.怎么使用VUE (1).引入vue.js 如:<script src='vue.js'>&l ...
- Trusted Execution Technology (TXT) --- 基本原理篇
版权声明:本文为博主原创文章,未经博主允许不得转载. http://www.cnblogs.com/tsec/p/8409600.html 1. Intel TXT 介绍 TXT是Trusted Ex ...
- [一个脑洞] Candy?'s 不饱和度
update 2017.7.10 Candy?'s 不饱和度 题目背景 化学老师让同学们出题!昌老师担任有机组组长! Candy?出了一道数不饱和度的题目,昌老师不会做所以拒绝接受!!! 于是Cand ...
- BZOJ 1040: [ZJOI2008]骑士 [DP 环套树]
传送门 题意:环套树的最大权独立集 一开始想处理出外向树树形$DP$然后找到环再做个环形$DP$ 然后看了看别人的题解其实只要断开环做两遍树形$DP$就行了...有道理! 注意不连通 然后洛谷时限再次 ...
- .net使用AsposeWord导出word table表格
本文为原创,转载请注明出处 1.前言 .net平台下导出word文件还可以使用Microsoft.Office.Interop和NPOI,但是这两者都有缺点,微软的Office.Interop组件需要 ...
- js 前端图片压缩+ios图片角度旋转
step1:读取选择的图片,并转为base64: function ImgToBase64 (e, fn) { // 图片方向角 //fn为传入的方法函数,在图片操作完成之后执行 var Orient ...
- 关于CSS的外边距合并问题
首先,需要明确的是只有普通文档流中块框的垂直外边距才会发生外边距合并.行内框.浮动框或绝对定位之间的外边距不会合并. 而在普通文档流中,这又分两种情况,分别是父子元素之间和相邻元素之间. <!D ...