requests+多进程poll+pymongo实现抓取小说
今天看着有个很吸引人的小说作品信息:一家只在深夜开门营业的书屋,欢迎您的光临。
作为东野奎吾《深夜食堂》漫画的fans,看到这个标题按捺不住我的好奇心........
所以我又抓下来了,总共52章,下面有源码,写的有点乱哦,凑合看看,关键看结果,@~@。。。。
代码写完,几秒钟就抓取下来,比下载效率高不少,小激动~~~~~~
readme>>>环境python2,我的python2还有多长寿命;其他內库依赖见代码体现
# coding:utf-8 from multiprocessing import Pool
from lxml import etree
import requests
import pymongo def save_mongo(data):
client = pymongo.MongoClient('60.205.211.210',27017)
db = client.test
collection = db.shenyeshuwu
collection.insert(dict(data))
print('--------%s---------存储完毕' %data['title']) def parse_content(url):
resp = requests.get(url).content
html = etree.HTML(resp)
contents = html.xpath('//*[@id="j_chapterBox"]/div[2]/div/div[2]/p/text()|//*[@id="j_chapterBox"]/div[1]/div/div[2]/p/text()')
return contents def parse_html(html):
'''
[{
'title':title,
'url':url,
'content':content
}]
'''
page = etree.HTML(html)
article_url_list = page.xpath('//ul[@class="cf"]/li/a')
for i in article_url_list:
url = 'http:' + i.xpath('./@href')[0]
# print(url)
title = i.xpath('./text()')[0]
# print(title)
time = i.xpath('./@title')[0]
# print(time)
con = parse_content(url)
# print(con)
data = {
'url': url,
'title': title,
'time': time,
'content': con
}
print(data)
save_mongo(data) def get_page(url):
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
resp = requests.get(url,headers=header).content
parse_html(resp) def main():
url = 'https://book.qidian.com/info/1011335417#Catalog'
# get_page(url)
# 使用进程池 map(func,iterable)
pool = Pool(4)
# pool.map(parse_content,data)
pool.apply_async(get_page,args=(url,))
pool.close()
pool.join() if __name__ == '__main__':
main()
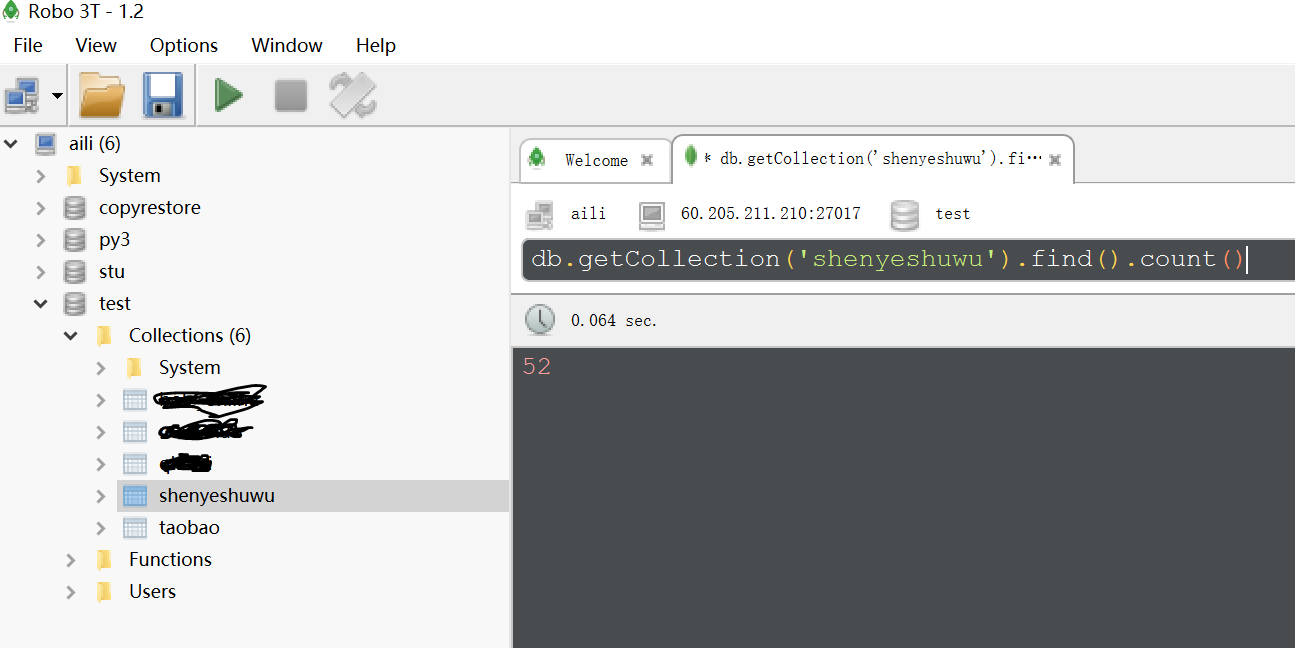
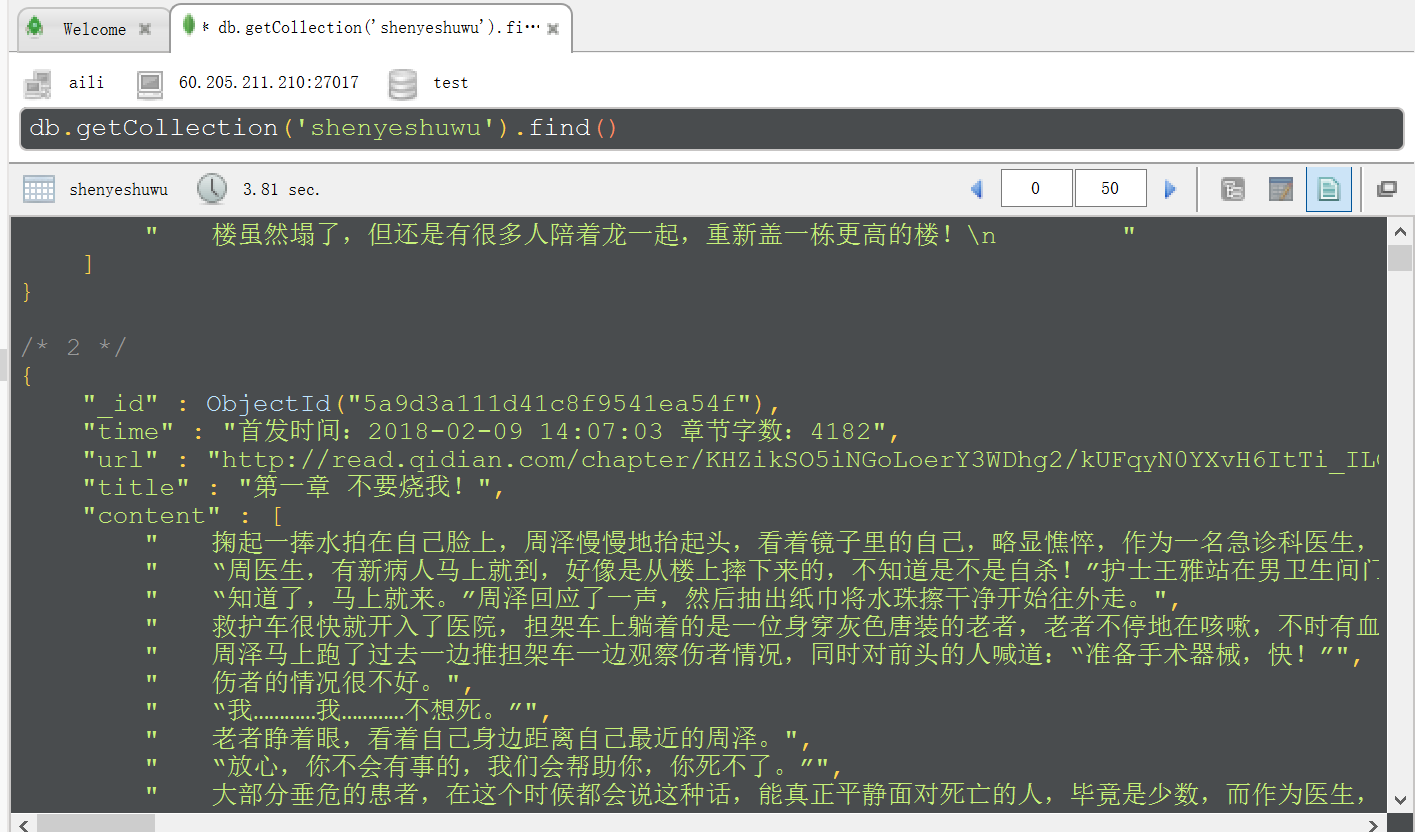
如往常,把截图展示下:
requests+多进程poll+pymongo实现抓取小说的更多相关文章
- C# 爬虫 抓取小说
心血来潮,想研究下爬虫,爬点小说. 通过百度选择了个小说网站,随便找了一本小书http://www.23us.so/files/article/html/13/13655/index.html. 1. ...
- C# 爬虫 正则、NSoup、HtmlAgilityPack、Jumony四种方式抓取小说
心血来潮,想爬点小说.通过百度选择了个小说网站,随便找了一本小说http://www.23us.so/files/article/html/13/13655/index.html. 1.分析html规 ...
- Python抓取小说
Python抓取小说 前言 这个脚本命令MAC在抓取小说写,使用Python它有几个码. 代码 # coding=utf-8 import re import urllib2 import chard ...
- scrapy抓取小说
用scrapy建立一个project,名字为Spider scrapy startproject Spider 因为之前一直用的是电脑自带的python版本,所以在安装scrapy时,有很多问题,也没 ...
- python requests 模拟登陆网站,抓取数据
抓取页面数据的时候,有时候我们需要登陆才可以获取页面资源,那么我们需要登陆以后才可以跳转到对应的资源页面,那么我们需要通过模拟登陆,登陆成功以后再次去抓取对应的数据. 首先我们需要通过手动方式来登陆一 ...
- python爬虫之抓取小说(逆天邪神)
2022-03-06 23:05:11 申明:自我娱乐,对自我学习过程的总结. 正文: 环境: 系统:win10, python版本:python3.10.2, 工具:pycharm. 项目目标: 实 ...
- Python 爬虫-抓取小说《盗墓笔记-怒海潜沙》
最近想看盗墓笔记,看了一下网页代码,竟然不是js防爬虫,那就用简单的代码爬下了一节: """ 爬取盗墓笔记小说-七星鲁王宫 """ from ...
- Python 爬虫-抓取小说《鬼吹灯之精绝古城》
想看小说<鬼吹灯之精绝古城>,可是网页版的好多广告,还要一页一页的翻,还无法复制,于是写了个小爬虫,保存到word里慢慢看. 代码如下: """ 爬取< ...
- jsoup使用样式class抓取数据时空格的处理
最近在研究用android和jsoup抓取小说数据,jsoup的使用可以参照http://www.open-open.com/jsoup/;在抓纵横中文网永生这本书的目录内容时碰到了问题, 永生的书简 ...
随机推荐
- 【转】linux grep命令
1.作用 Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来 2.格式 grep [options] 3.主要参数 [options]主要参数: - ...
- matlab获取文件夹中的所有文件名(dir)
当前目录中包含文件及目录如下: abc111.txt abc112.txt abc113.txt a\ (文件夹) CODE: >> dir('test') %目录 . ...
- bzoj4326 运输计划
4326: NOIP2015 运输计划 Time Limit: 30 Sec Memory Limit: 128 MB Description 公元 2044 年,人类进入了宇宙纪元.L 国有 n ...
- windows下cmd常用
windows下cmd常用 shutdown -s -t 2------2秒后关机 加上-f选项意思是强制执行 shutdown -r -t 2------2秒后重启 加上-f选项意思是强制执行 lo ...
- 【三思笔记】 全面学习Oracle分区表及分区索引
[三思笔记]全面学习Oracle分区表及分区索引 2008-04-15 关于分区表和分区索引(About PartitionedTables and Indexes) 对于 10gR2 而言,基本上可 ...
- Linux history命令
history命令主要用于显示历史命令, 重新执行历史命令. Linux系统当你在shell(控制台)中输入并执行命令时,shell会自动把你的命令记录到历史列表中,一般保存在用户目录下的.bash_ ...
- WebService的学习
这篇文章不错,直接转了 http://blog.csdn.net/terryzero/article/details/5976638#comments
- js中如何处理大量有规律的变量
var a1=document.getElementById('a1'); var a1=document.getElementById('a2'); var a1=document.getEleme ...
- 洛谷 [P2486] 染色
树剖+线段树维护连续相同区间个数 注意什么时候长度要减一 #include <iostream> #include <cstdio> #include <cstdlib& ...
- BZOJ 3265: 志愿者招募加强版 [单纯形法]
传送门 一个人多段区间,一样.... 不过国家队论文上说这道题好像不能保证整数解.... #include <iostream> #include <cstdio> #incl ...