Hadoop 2.x
Hadoop 2.x 生态系统及技术架构图
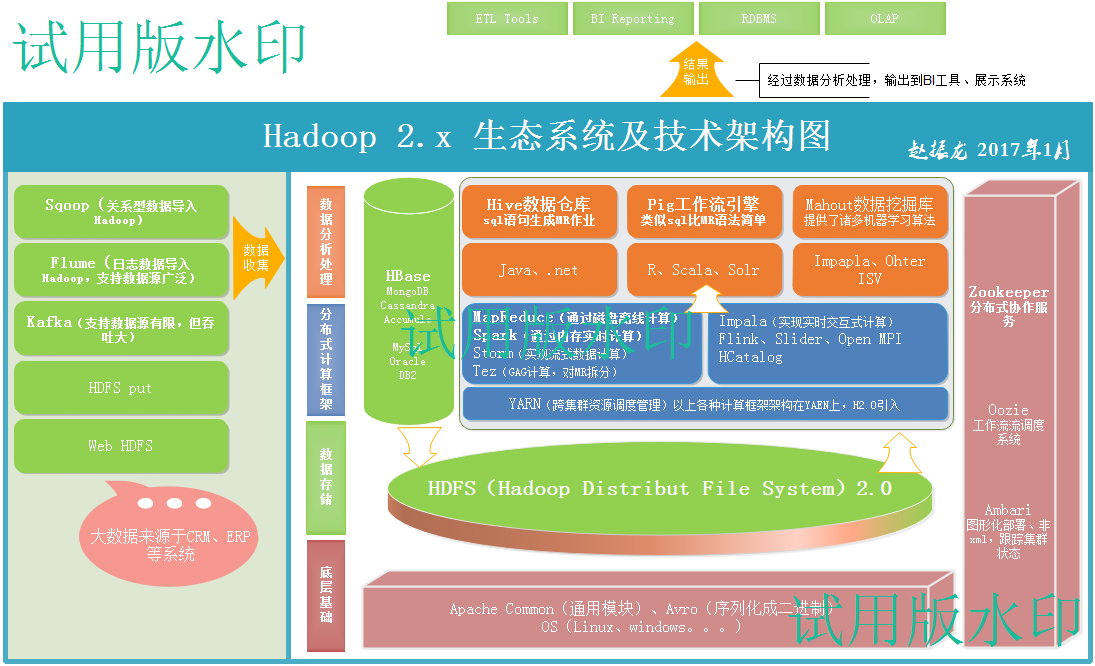
一、负责收集数据的工具:
Sqoop(关系型数据导入Hadoop)
Flume(日志数据导入Hadoop,支持数据源广泛)
Kafka(支持数据源有限,但吞吐大)
二、负责存储数据的工具:
HBase
MongoDB
Cassandra
Accumulo
MySql
Oracle
DB2
HDFS(Hadoop Distribut File System)2.0
三、底层组件
Apache Common(通用模块)、
Avro(序列化成二进制)、
OS(Linux、windows。。。)
四、通用工具
Zookeeper分布式协作服务
Oozie工作流流调度系统
Ambari图形化部署、非xml,跟踪集群状态
五、分布式计算框架
MapReduce(通过磁盘离线计算)
Spark(通过内存实时计算)
Storm(实现流式数据计算)
Tez(GAG计算,对MR拆分)
Impala(实现实时交互式计算)
Flink、Slider、Open MPI
HCatalog
YARN(跨集群资源调度管理)以上各种计算框架架构在YAEN上,H2.0引入
六、数据分析处理
Hive数据仓库
sql语句生成MR作业
Pig工作流引擎
类似sql比MR语法简单
Mahout数据挖掘库
提供了诸多机器学习算法
Java、.net
R、Scala、Solr
Impapla、Ohter ISV
七、结果输出
经过数据分析处理,输出到BI工具、展示系统
ETL Tools
BI Reporting
RDBMS
OLAP
Hadoop 2.x的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 程序员必须要知道的Hadoop的一些事实
程序员必须要知道的Hadoop的一些事实.现如今,Apache Hadoop已经无人不知无人不晓.当年雅虎搜索工程师Doug Cutting开发出这个用以创建分布式计算机环境的开源软...... 1: ...
- Hadoop 2.x 生态系统及技术架构图
一.负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大) 二.负责存储数据的工具:HBaseMong ...
- Hadoop的安装与设置(1)
在Ubuntu下安装与设置Hadoop的主要过程. 1. 创建Hadoop用户 创建一个用户,用户名为hadoop,在home下创建该用户的主目录,就不详细介绍了. 2. 安装Java环境 下载Lin ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
随机推荐
- js模块定义——支持CMD&AMD&直接加载
/* animate */ //直接加载 (function() { var animate = {} //balabala window.animate = animate; })(); //AMD ...
- 【分布式】Chubby与Paxos
一.前言 在上一篇理解了Paxos算法的理论基础后,接下来看看Paxos算法在工程中的应用. 二.Chubby Chubby是一个面向松耦合分布式系统的锁服务,GFS(Google File Syst ...
- android 模拟2048
利用节日休息时间在ANDROID上进行学习并模拟2048游戏. 效果如下图: 制作思路: 1.画出2048游戏主界面,根据手机屏幕宽高度进行计算并画出每个方块的大小. @Override protec ...
- intellij idea 15 修改基础配置加载路径
一.概述 intellij idea 15 默认配置的启动加载路径是"C:\Users\Administrator.IntelliJIdea15",这样会导致占用C盘的空间越来越多 ...
- KMP算法
KMP算法是字符串模式匹配当中最经典的算法,原来大二学数据结构的有讲,但是当时只是记住了原理,但不知道代码实现,今天终于是完成了KMP的代码实现.原理KMP的原理其实很简单,给定一个字符串和一个模式串 ...
- MYSQL基础知识和操作(二).png
- CentOS7安装docker
1. 查看系统版本 $ cat /etc/redhat-release 2. 安装docker $ yum install docker 3.检查安装是否成功$ docker version 若 ...
- Android Studio多渠道打包
本文所讲述的多渠道打包是基于友盟统计实施的. 多渠道打包的步骤: 1.在AndroidManifest.xml里设置动态渠道变量 <meta-data android:name="UM ...
- 文件缓存(配合JSON数组)
1. 写入缓存:建立文件夹,把list集合里面的数组转换为JSON数组,存入文件夹2. 读取缓存:把JSON数组从文件夹里面读取出来,然后放入list集合,返回list集合 private fin ...
- .a静态库构架合成
一.如果类库生成的构架和对应设备的构架不一致,会链接报错 如果项目中使用类库后,遇到形似Undefined symbols for architecture x86_64(x86_64架构下有未定义的 ...