machine learning 之 多元线性回归
整理自Andrew Ng的machine learning课程 week2.
目录:
- 多元线性回归 Multivariates linear regression /MLR
- Gradient descent for MLR
- Feature Scaling and Mean Normalization
- Ensure gradient descent work correctly
- Features and polynomial regression
- Normal Equation
- Vectorization
前提:
$x_{(j)}^{(i)}$:第i个训练样本的第j个特征的值;
$x^{(i)}$:第i个训练样本;
m:训练样本的数目;
n:特征的数目;
1、多元线性回归
具有多个特征变量的回归
比如,在房价预测问题中,特征变量有房子面积x1,房间数量x2等;
模型:
$h_\theta(x)=\theta_0+\theta_1x1+\theta_2x_2+...+\theta_nx_n$
为了方便,认为$x_0=1$(注意这是一个vector,$[x_0^{(1)} x_0^{(2)} ... x_0^{(n)}]=1$),这样的话x和theta就可以相互匹配,进行矩阵运算了;
对于一个training example而言:
$h_\theta(x)$
$=\theta_0+\theta_1x1+\theta_2x_2+...+\theta_nx_n$
=$\theta^Tx$
=$\begin{bmatrix} \theta_0 & \theta_1 & ... & \theta_n \end{bmatrix} \begin{bmatrix} x_0\\ x_1\\ ...\\ x_n \end{bmatrix}$
对于所有的训练样本而言:
$X=\begin{bmatrix} x_0^(1) & x_1^(1) & ...& x_n^(1)\\ x_0^(2) & ... & ... & ...\\ ... & ... & ... & ...\\ x_0^(m) & x_1^(m) & ...& x_n^(m) \end{bmatrix} \qquad \theta=\begin{bmatrix} \theta_0\\ \theta_1\\ ...\\ \theta_n \end{bmatrix}$
X是design matrix,$h_\theta(x)=X\theta$
2、Gradient descent for MLR
损失函数:$J(\theta)=\frac{1}{2m} \sum_{i=1}^m(h_\theta(x^{(i)})-y_{(i)})^2 = \frac{1}{2m} (X\theta-y)^T (X\theta-y)$
GD更新准则:
$\theta_j:=\theta_j-\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_j$
3、Feature Scaling and Mean Normalization
思想:确保特征的量级在统一尺度之下
为什么要做feature scaling?
如下图,当特征不在一个尺度之下时,优化时的等高线图相当于一个又长又细的椭圆,此时GD会走的特别曲折,要很久才可以找到最优解;
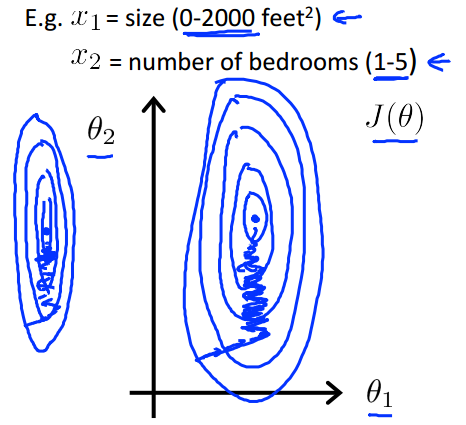
而当特征的尺度一致时,优化时的等高线图是接近一个正圆,GD就会很快的找到最优解;
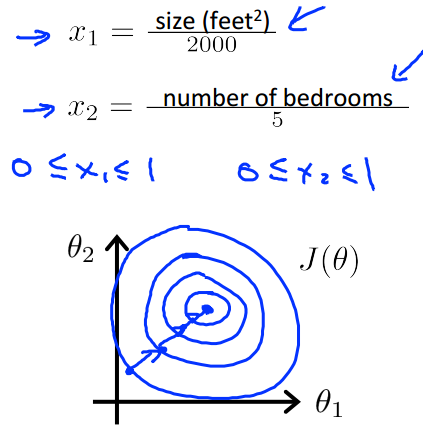
如何做feature scaling?
$x=\frac{x}{max(x)-min(x)}$
这样可以保证x在0到1之间,一般而言,-1<x<1是比较标准的scaling尺度,但是并不是一定要在这个范围之内。
Mean Normalization
结合Feature Scaling :$x=\frac{x-\mu}{range(x)}$
$\mu$是x的均值,range(x)是最大值与最小值的范围,或者是标准差;
4、Ensure gradient descent work correctly
如何保证我们的Gradient descent是work correctly?可以画一个损失函数随迭代次数变化的图:
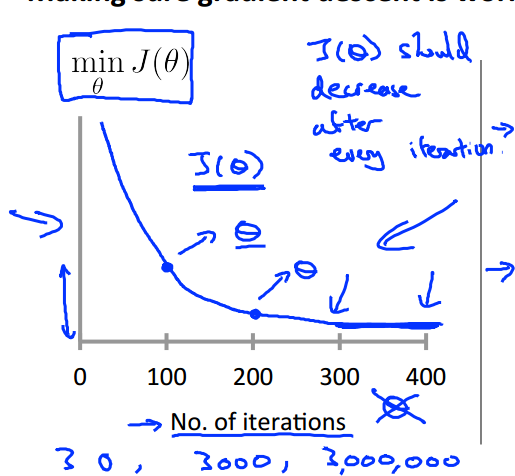
如果GD是做的对的话,那么J应该是下降的,在迭代一定次数后开始收敛。(迭代次数视问题而定,有可能是400,有可能是40,也有可能是4000)
那么怎样才是收敛呢?
在一次迭代中,J下降的十分慢,小于某个很小的阈值(如$10^-3$),但是实际上这个阈值的选择是十分困难的,建议通过J-iteration来调整;
学习率的选取
如果你的J是增大的,那么可能是因为学习率$\alpha$选取的太大了,可以调整$\alpha$;
如果J下降的十分缓慢,说明$\alpha$的选取太小了的,这会消耗很多时间达到收敛;
建议可以通过观察J-iteration图,逐步的调整$\alpha$(0.001,0.003,0.01,0.03,0.1,0.3,1,3.......);
5、Feature and Polynomial regression
Features
比如在房价预测问题中,若x1是房子的长,x2是房子的宽,此时若组合x1和x2就可以得到一个新的特征area=x1*x2;构造一个好的特征对模型是有帮助的;
Polynomial regression
同上思想,如当线性关系无法精确的拟合散点的话,那应当考虑一些非线性的函数,如quadratic、cubic和square root的关系:
$h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_3$
$=\theta_0+\theta_1(size)+\theta_1(size)^2+\theta_1(size)^3$
此时:
$x_1=size$
$x_2=size^2$
$x_3=size^3$
同时,在这个时候,Feature Scaling就显得特别重要了:
因为若size<10,则$size^2<100$,$size^3<1000$,
6、Normal Equation
在线性回归问题中,除了可以用GD求最优解,还可以用解析解之间求解,在线性代数中:
$\frac{\partial J}{\partial \theta}=0$是有解析解的:
$\theta=(X^TX)^-1X^Ty$
注意用这种方法求解时,就没必要进行Feature Scaling了;
那既然有解析解了,为什么还要使用Gradient descent呢?
| Gradient Descent | Normal Equation |
| 需要进行迭代 | 无需迭代 |
| 需要设定学习率$\alpha$ | 无需设定学习率$\alpha$ |
| 时间复杂度为O(kn2) | 时间复杂度O(n3)(主要是求逆的复杂度) |
由表中第3点,当数据的特征特别多(n=106)时,Normal Equation会耗费相当多的时间
而且,并非所有的优化问题都要解析解,很多复杂的机器学习问题是没有解析解的,此时我们还是需要使用Gradient Descent来求解
$X^TX$没有逆?
注意到解析解里面有个求逆运算,但是有些情况是没有逆的:
- Redundant features(linearly dependent)
当两个特征是线性依赖的时候,比如size in feet2 和size in m2;
- Too many features(m<=n)
当特征太多了,多于训练样本的数目的时候;
如何解决这个问题?
删除一些特征,或者使用regularization;
注:在matlab/octave中,求逆有inv和pinv两种,而pinv就是在即使没有逆的时候也可以求出来一个逆;
7、Vectorization
在求解一个线性回归问题的时候,无论是计算损失,还是更新参数($\theta$),都有很多的向量计算问题,对于这些计算问题,可以使用for循环去做,但是在matlab/octave,或者python或其他语言的数值计算包中,对向量的计算都进行了优化,如果使用向量计算而不是for循环的话,可以写更少的代码,并且计算更有效率。
在上面的一些公式中,都做了vectorization的处理。(主要是计算损失和更新参数)
machine learning 之 多元线性回归的更多相关文章
- [Machine Learning]学习笔记-线性回归
模型 假定有i组输入输出数据.输入变量可以用\(x^i\)表示,输出变量可以用\(y^i\)表示,一对\(\{x^i,y^i\}\)名为训练样本(training example),它们的集合则名为训 ...
- [Machine Learning] 单变量线性回归(Linear Regression with One Variable) - 线性回归-代价函数-梯度下降法-学习率
单变量线性回归(Linear Regression with One Variable) 什么是线性回归?线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方 ...
- Coursera《machine learning》--(2)单变量线性回归(Linear Regression with One Variable)
本笔记为Coursera在线课程<Machine Learning>中的单变量线性回归章节的笔记. 2.1 模型表示 参考视频: 2 - 1 - Model Representation ...
- 【Machine Learning】单参数线性回归 Linear Regression with one variable
最近开始看斯坦福的公开课<Machine Learning>,对其中单参数的Linear Regression(未涉及Gradient Descent)做个总结吧. [设想] ...
- 机器学习---最小二乘线性回归模型的5个基本假设(Machine Learning Least Squares Linear Regression Assumptions)
在之前的文章<机器学习---线性回归(Machine Learning Linear Regression)>中说到,使用最小二乘回归模型需要满足一些假设条件.但是这些假设条件却往往是人们 ...
- Machine Learning 算法可视化实现1 - 线性回归
一.原理和概念 1.回归 回归最简单的定义是,给出一个点集D,用一个函数去拟合这个点集.而且使得点集与拟合函数间的误差最小,假设这个函数曲线是一条直线,那就被称为线性回归:假设曲线是一条二次曲线,就被 ...
- 机器学习---用python实现最小二乘线性回归算法并用随机梯度下降法求解 (Machine Learning Least Squares Linear Regression Application SGD)
在<机器学习---线性回归(Machine Learning Linear Regression)>一文中,我们主要介绍了最小二乘线性回归算法以及简单地介绍了梯度下降法.现在,让我们来实践 ...
- 《Machine Learning in Action》—— 浅谈线性回归的那些事
<Machine Learning in Action>-- 浅谈线性回归的那些事 手撕机器学习算法系列文章已经肝了不少,自我感觉质量都挺不错的.目前已经更新了支持向量机SVM.决策树.K ...
- 机器学习---线性回归(Machine Learning Linear Regression)
线性回归是机器学习中最基础的模型,掌握了线性回归模型,有利于以后更容易地理解其它复杂的模型. 线性回归看似简单,但是其中包含了线性代数,微积分,概率等诸多方面的知识.让我们先从最简单的形式开始. 一元 ...
随机推荐
- Asp.net的sessionState四种模式配置方案
sessionState节点的配置 web.config关于sessionState节点的配置方案,sessionState有四种模式:off,inProc,StateServer,SqlServer ...
- 异常-----Template user.ftl not found
freemarker 1.错误描述 java.io.FileNotFoundException: Template user.ftl not found. at freemarker.template ...
- 网页加载进度的实现--JavaScript基础
总结了一些网页加载进度的实现方式…… 1.定时器实现加载进度 <!DOCTYPE html><html lang="en"><head> < ...
- 【BZOJ4816】数字表格(莫比乌斯反演)
[BZOJ4816]数字表格(莫比乌斯反演) 题面 BZOJ 求 \[\prod_{i=1}^n\prod_{j=1}^mf[gcd(i,j)]\] 题解 忽然不知道这个要怎么表示... 就写成这样吧 ...
- [Luogu2991][USACO10OPEN]水滑梯Water Slides
题面戳我 题面描述 受到秘鲁的马丘比丘的新式水上乐园的启发,Farmer John决定也为奶牛们建一个水上乐园.当然,它最大的亮点就是新奇巨大的水上冲浪. 超级轨道包含 E (1 <= E &l ...
- [SCOI2008]奖励关
题面在这里 题意 不好描述.....大家还是看luogu上的吧(资磁洛谷!) sol \(n<=15\)的良心数据肯定是状压啦 只是设状态的时候有点头疼 首先思考我们在无法预知之后宝物的情况下如 ...
- .NET Core使用skiasharp文字头像生成方案(基于docker发布)
一.问题背景 目前.NET Core下面针对于图像处理的库微软并没有集成,在.NET FrameWork下我们已经习惯使用System.Drawing类库做简单的图像处理,到了.NET Core下一脸 ...
- weblogic 服务器部署SSL证书
一.证书介绍 1.需要的证书 生产需要的证数如下: 即客户提供的证数: L1Croot.crt,L1Cchain.crt,entrustcert.crt,server,jks 证书清单: L1Croo ...
- SQL Server 历史SQL执行记录
编程执行Sql语句难免忘记保存执行的文本,或是意外设备故障多种情况的发生.对于写的简单的Sql语句丢了就丢了,但对于自己写的复杂的丢失就有些慌了, 有时候很难再次写出来,这时候就需要用一些方法找回Sq ...
- 用user-selection实现让页面上的内容不能被选中
最开始发现这个功能是在陌小雨的博客中,然后自己百度发现用的是user-selection功能,之前网上有很多关于禁止右键,禁止复制,禁止粘 贴,禁止剪切等都弱爆了.这个功能正好使用到我的网站上啊,(你 ...