【spring源码分析】IOC容器初始化(二)
前言:在【spring源码分析】IOC容器初始化(一)文末中已经提出loadBeanDefinitions(DefaultListableBeanFactory)的重要性,本文将以此为切入点继续分析。
AbstractXmlApplicationContext#loadBeanDefinitions(DefaultListableBeanFactory)
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// Create a new XmlBeanDefinitionReader for the given BeanFactory.
// 创建XmlBeanDefinitionReader对象
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
// 对XmlBeanDefinitionReader进行环境变量的设置
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
// 对XmlBeanDefinitionReader进行设置,可以进行覆盖
initBeanDefinitionReader(beanDefinitionReader);
// 从Resource中加载BeanDefinition
loadBeanDefinitions(beanDefinitionReader);
}
分析:
- 首先创建一个XmlBeanDefinitionReader对象,因为我们需要解析xml文件,然后将其封装成BeanDefinition。
- 设置XmlBeanDefinitionReader对象的相关属性,这里着重关注ResourceLoader,这里引申出Resource/ResourceLoader体系。
- 从Resource中加载BeanDefinition。
Resource体系
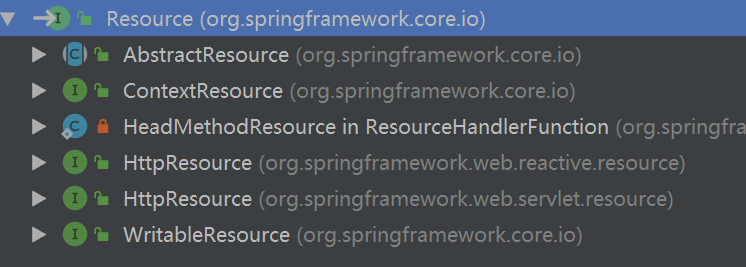
Resource继承InputStreamSource,为spring框架所有资源的访问提供抽象接口,子类AbstractResource提供Resource接口的默认实现。
ResourceLoader体系
ResourceLoader为spring资源加载的统一抽象,主要应用于根据给定的资源文件地址返回相应的Resource对象,其具体的实现由相应子类去负责。
这里列出笔者认为的几个比较重要ResourceLoader的实现类。

- DefaultResourceLoader是ResourceLoader的默认实现
- PathMatchingResourcePatternResolver,该类比较常用,除了支持"classpath*:"格式,还支持Ant风格的路径匹配模式
接下来进入AbstractXmlApplicationContext#loadBeanDefinitions方法
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
// 从配置文件Resource中,加载BeanDefinition
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
// 从配置文件地址中,加载BeanDefinition
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
分析:
看到这里是否很熟悉因为我们在【spring源码分析】IOC容器初始化(一)中已经设置了资源文件的路径(setConfigLocations)方法,因此这里会直接走到第9行处,然后调用AbstractBeanDefinitionReader#loadBeanDefinitions方法:
public int loadBeanDefinitions(String... locations) throws BeanDefinitionStoreException {
Assert.notNull(locations, "Location array must not be null");
int count = 0;
for (String location : locations) {
count += loadBeanDefinitions(location);
}
return count;
}
分析:
这里会遍历locations,并返回最终加载bean的个数,函数最终切入点:AbstractBeanDefinitionReader#loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources):
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
// 获取ResourceLoader对象
ResourceLoader resourceLoader = getResourceLoader();
// 资源加载器为null,抛出异常
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot load bean definitions from location [" + location + "]: no ResourceLoader available");
}
// 如果当前ResourceLoader为匹配模式形式的[支持一个location返回Resource[]数组形式]
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
// 通过location返回Resource[]数组,通过匹配模式形式,可能存在多个Resource
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
// 加载BeanDefinition,返回BeanDefinition加载的个数
int count = loadBeanDefinitions(resources);
// 将Resource[] 添加到actualResources中
if (actualResources != null) {
Collections.addAll(actualResources, resources);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location pattern [" + location + "]");
}
// 返回BeanDefinition加载的个数
return count;
} catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
// ResourceLoader为默认资源加载器,一个location返回一个Resource
} else {
// Can only load single resources by absolute URL.
Resource resource = resourceLoader.getResource(location);
// 加载BeanDefinition,并返回加载BeanDefinition的个数
int count = loadBeanDefinitions(resource);
// 将Resource添加到actualResources中
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location [" + location + "]");
}
// 返回BeanDefinition加载的个数
return count;
}
}
分析:
- 首先获取ResourceLoader,ResourceLoader的赋值在创建XmlBeanDefinitionReader的过程中,如果未指定则会创建一个PathMatchingResourcePatternResolver对象。
- 然后根据对应的ResourceLoader返回的Resource对象。
关注第15行代码,getResources(String)方法,这里会直接委托给PathMatchingResourcePatternResolver#getResources(String)进行处理:
public Resource[] getResources(String locationPattern) throws IOException {
Assert.notNull(locationPattern, "Location pattern must not be null");
// 以"classpath*:"开头的location
if (locationPattern.startsWith(CLASSPATH_ALL_URL_PREFIX)) {
// a class path resource (multiple resources for same name possible)
// #1.isPattern函数的入参为路径
// #2.所以这里判断路径是否包含通配符 如com.develop.resource.*
if (getPathMatcher().isPattern(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()))) {
// a class path resource pattern
// 这里通过通配符返回Resource[]
return findPathMatchingResources(locationPattern);
// 路径不包含通配符
} else {
// all class path resources with the given name
// 通过给定的路径,找到所有匹配的资源
return findAllClassPathResources(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()));
}
// 不以"classpath*:"
} else {
// Generally only look for a pattern after a prefix here,
// and on Tomcat only after the "*/" separator for its "war:" protocol.
// 通常在这里只是通过前缀后面进行查找,并且在tomcat中只有在"*/"分隔符之后才是其"war:"协议
// #1.如果是以"war:"开头,定位其前缀位置
// #2.如果不是以"war:"开头,则prefixEnd=0
int prefixEnd = (locationPattern.startsWith("war:") ? locationPattern.indexOf("*/") + 1 :
locationPattern.indexOf(':') + 1);
// 判断路径中是否含有通配符否含有通配符
if (getPathMatcher().isPattern(locationPattern.substring(prefixEnd))) {
// a file pattern
// 通过通配符返回返回Resource[]
return findPathMatchingResources(locationPattern);
// 路径不包含通配符
} else {
// a single resource with the given name
// 通过给定的location返回一个Resource,封装成数组形式
// 获取Resource的过程都是通过委托给相应的ResourceLoader实现
return new Resource[]{getResourceLoader().getResource(locationPattern)};
}
}
}
分析:
首先两大分支:根据资源路径是否包含"classpath*:"进行处理。
#1."classpath*:"分支:
- 首先判断路径中是否含有通配符"*"或"?",然后执行findPathMatchingResources函数。
- 如果不包含通配符,则根据路径找到所有匹配的资源,执行findAllClassPathResources函数。
#2.路径中不含"classpath*:"分支,与上述过程一样,同样按分支含有通配符与不含通配符进行处理。
PathMatchingResourcePatternResolver#findPathMatchingResources(String)
protected Resource[] findPathMatchingResources(String locationPattern) throws IOException {
// 确定根路径与子路径
String rootDirPath = determineRootDir(locationPattern);
String subPattern = locationPattern.substring(rootDirPath.length());
// 得到根路径下的资源
Resource[] rootDirResources = getResources(rootDirPath);
Set<Resource> result = new LinkedHashSet<>(16);
// 遍历获取资源
for (Resource rootDirResource : rootDirResources) {
// 解析根路径资源
rootDirResource = resolveRootDirResource(rootDirResource);
URL rootDirUrl = rootDirResource.getURL();
// bundle类型资源
if (equinoxResolveMethod != null && rootDirUrl.getProtocol().startsWith("bundle")) {
URL resolvedUrl = (URL) ReflectionUtils.invokeMethod(equinoxResolveMethod, null, rootDirUrl);
if (resolvedUrl != null) {
rootDirUrl = resolvedUrl;
}
rootDirResource = new UrlResource(rootDirUrl);
}
// vfs类型资源
if (rootDirUrl.getProtocol().startsWith(ResourceUtils.URL_PROTOCOL_VFS)) {
result.addAll(VfsResourceMatchingDelegate.findMatchingResources(rootDirUrl, subPattern, getPathMatcher()));
// jar类型资源
} else if (ResourceUtils.isJarURL(rootDirUrl) || isJarResource(rootDirResource)) {
result.addAll(doFindPathMatchingJarResources(rootDirResource, rootDirUrl, subPattern));
// 其他类型资源
} else {
result.addAll(doFindPathMatchingFileResources(rootDirResource, subPattern));
}
}
if (logger.isDebugEnabled()) {
logger.debug("Resolved location pattern [" + locationPattern + "] to resources " + result);
}
// 将结果封装成数组形式 注意该转换形式
return result.toArray(new Resource[0]);
}
分析:
函数的整体处理逻辑比较简单,根据不同的资源类型,将资源最终转换为Resource数组。
特别分析:
determineRootDir(String)
protected String determineRootDir(String location) {
// 确定":"的后一位,如果":"不存在,则prefixEnd=0
int prefixEnd = location.indexOf(':') + 1;
// location的长度
int rootDirEnd = location.length();
// 从location的":"开始(可能不存在)一直到location结束,判断是否包含通配符,如果存在,则截取最后一个"/"分割的部分
/**
* 截取过程:
* classpath*:com/dev/config/*
* prefixEnd=11
* subString(prefixEnd,rootDirEnd)=com/dev/config/*
* 第一次循环rootDirEnd=26,也就是最后一个"/"
* subString(prefixEnd,rootDirEnd)=com/dev/config/
* 第二次循环已经不包含通配符了,跳出循环
* 所以根路径为classpath*:com/dev/config/
*/
while (rootDirEnd > prefixEnd && getPathMatcher().isPattern(location.substring(prefixEnd, rootDirEnd))) {
// 确定最后一个"/"位置的后一位,注意这里rootDirEnd-2是为了缩小搜索范围,提升速度
rootDirEnd = location.lastIndexOf('/', rootDirEnd - 2) + 1;
}
// 如果查找完后rootDirEnd=0,则将prefixEnd赋值给rootDirEnd,也就是冒号的后一位
if (rootDirEnd == 0) {
rootDirEnd = prefixEnd;
}
// 截取根目录
return location.substring(0, rootDirEnd);
}
分析:
该函数有点绕,整体思想就是决定出给定资源路径的根路径,代码中已经给出了详细注释,处理效果如下实例:

PathMatchingResourcePatternResolver#findAllClassPathResources(String)
protected Resource[] findAllClassPathResources(String location) throws IOException {
String path = location;
// location是否已"/"开头
if (path.startsWith("/")) {
path = path.substring(1);
}
// 真正加载location下所有classpath下的资源
Set<Resource> result = doFindAllClassPathResources(path);
if (logger.isDebugEnabled()) {
logger.debug("Resolved classpath location [" + location + "] to resources " + result);
}
return result.toArray(new Resource[0]);
}
分析:
该函数会查找路径下的所有资源,核心函数doFindAllClassPathResources(String):
protected Set<Resource> doFindAllClassPathResources(String path) throws IOException {
Set<Resource> result = new LinkedHashSet<>(16);
ClassLoader cl = getClassLoader();
// 根据ClassLoader来加载资源
// 如果PathMatchingResourcePatternResolver在初始化时,设置了ClassLoader,就用该ClassLoader的getResouce方法
// 否则调用ClassLoader的getSystemResource方法
Enumeration<URL> resourceUrls = (cl != null ? cl.getResources(path) : ClassLoader.getSystemResources(path));
// 遍历集合将集合转换成UrlResource形式
// 如果path为空,这里就会返回项目中classes的路径,通过addAllClassLoaderJarRoots方法进行加载
while (resourceUrls.hasMoreElements()) {
URL url = resourceUrls.nextElement();
result.add(convertClassLoaderURL(url));
}
// 如果path为空,则加载路径下的所有jar
if ("".equals(path)) {
// The above result is likely to be incomplete, i.e. only containing file system references.
// We need to have pointers to each of the jar files on the classpath as well...
// 加载所有jar
addAllClassLoaderJarRoots(cl, result);
}
return result;
}
分析:该函数的主要功能就是将搜索配置文件路径下的所有资源,然后封装成Resource集合返回,供加载BeanDefinition使用。
不含"classpath*:"分支的逻辑与上述分析差不多,这里不再做过多赘述。
Resource资源准备就绪后,再次回到loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources)函数中,在第17行代码处进入正式加载BeanDefinition过程。
AbstractBeanDefinitionReader#loadBeanDefinitions(Resource... resources)
public int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException {
Assert.notNull(resources, "Resource array must not be null");
int count = 0;
// 通过循环的形式单个加载BeanDefinition
for (Resource resource : resources) {
count += loadBeanDefinitions(resource);
}
return count;
}
在循环过程中会落入XmlBeanDefinitionReader#loadBeanDefinitions(Resource resource)
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
// 这里会将Resource封装成EncodeResource,主要主要为了内容读取的正确性
return loadBeanDefinitions(new EncodedResource(resource));
}
该函数将Resource封装成EncodeResource,主要是为了内容读取的正确性,然后进入加载BeanDefinition的核心函数XmlBeanDefinitionReader#loadBeanDefinitions(EncodedResource encodedResource)
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
// 获取已经加载过的资源
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
// 表示当前没有资源加载
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
// 将当前资源加入记录中,如果已经存在,则抛出异常,因为currentResource为Set集合
// 这里主要为了避免一个EncodeResource还没加载完成时,又加载本身,造成死循环(Detected cyclic loading of)
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
// 从封装的encodeResource中获取resource,并取得其输入流,通过流对资源进行操作
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
// 将流封装成InputSource
InputSource inputSource = new InputSource(inputStream);
// 设置InputSource的编码
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 核心逻辑,实现BeanDefinition的加载
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
} finally {
inputStream.close();
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
} finally {
// 最后从缓存中清除资源
currentResources.remove(encodedResource);
// 如果当前资源集合为空,则从EncodeResource集合中移除当前资源的集合
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
分析:
- 首先判断缓存中是否已经存在当前资源,如果存在则抛出异常,这里是为了避免循环加载。
- 然后取出文件流封装成InputSource,进入加载BeanDefinition的核心函数doLoadBeanDefinitions。
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// #1.获取XML的Document实例
Document doc = doLoadDocument(inputSource, resource);
// #2.根据Document注册bean,并返回注册的bean的个数
return registerBeanDefinitions(doc, resource);
} catch (BeanDefinitionStoreException ex) {
throw ex;
} catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
} catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
} catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
} catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
} catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
分析:
- 首先获取XML配置文件的Document实例。
- 根据Document注册Bean,并返回注册Bean的个数。
XmlBeanDefinitionReader#doLoadDocument(InputSource inputSource, Resource resource)
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
分析:
这里是委派给DefaultDocumentLoader#loadDocument函数来实现。
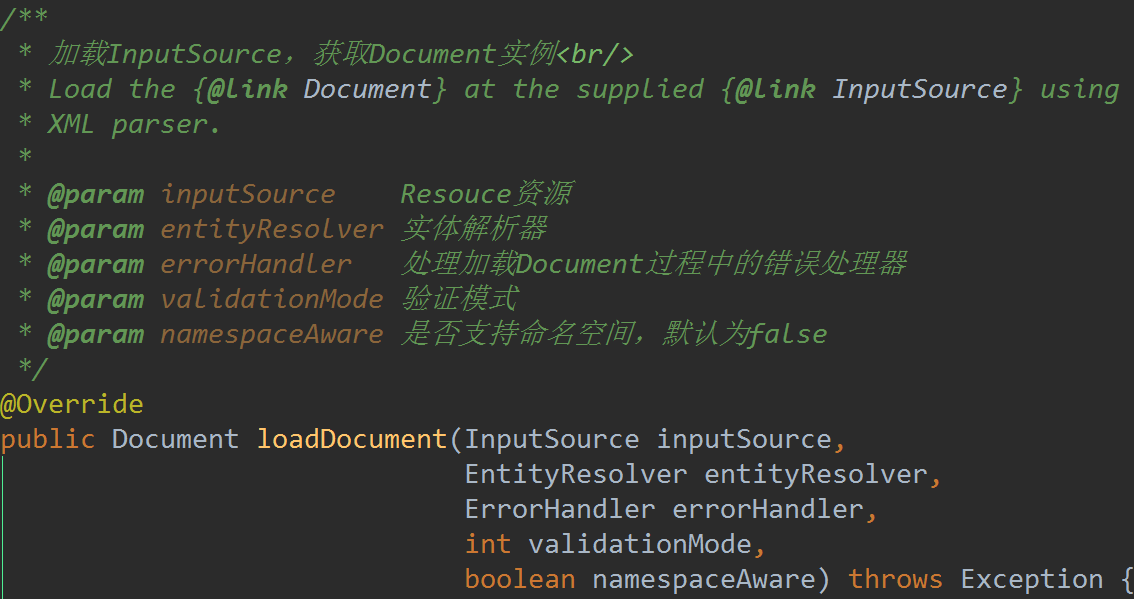
这里有一个验证模式的入参,从getValidationModeForResource函数而来:
protected int getValidationModeForResource(Resource resource) {
// 获取指定的验证模式,默认为自动模式
int validationModeToUse = getValidationMode();
// #1.如果验证模式不为自动验证模式,则表示进行了设置,则直接返回验证模式即可
if (validationModeToUse != VALIDATION_AUTO) {
return validationModeToUse;
}
// #2.到这里表示使用了自动验证模式,再次检测Resource使用的验证模式
int detectedMode = detectValidationMode(resource);
if (detectedMode != VALIDATION_AUTO) {
return detectedMode;
}
// 最后使用默认的VALIDATION_XSD验证模式
// Hmm, we didn't get a clear indication... Let's assume XSD,
// since apparently no DTD declaration has been found up until
// detection stopped (before finding the document's root tag).
return VALIDATION_XSD;
}
分析:
- 首先获取当前的验证模式,默认为自动验证模式。
- 如果当前验证模式不为自动验证模式,则表示进行了设置,则直接返回当前验证模式即可。
- 如果使用了自动验证模式,则需再次检测Resource使用的验证模式
- 最后,如果还是自动验证模式,则返回XSD验证模式。
这里要科普一下DTD与XSD
DTD(Document Type Definition),即文档类型定义,为 XML 文件的验证机制,属于 XML 文件中组成的一部分。DTD 是一种保证 XML 文档格式正确的有效验证方式,它定义了相关 XML 文档的元素、属性、排列方式、元素的内容类型以及元素的层次结构。其实 DTD 就相当于 XML 中的 “词汇”和“语法”,我们可以通过比较 XML 文件和 DTD 文件 来看文档是否符合规范,元素和标签使用是否正确。
但是DTD存在着一些缺陷:
- 它没有使用 XML 格式,而是自己定义了一套格式,相对解析器的重用性较差;而且 DTD 的构建和访问没有标准的编程接口,因而解析器很难简单的解析 DTD 文档。
- DTD 对元素的类型限制较少;同时其他的约束力也叫弱。
- DTD 扩展能力较差。
- 基于正则表达式的 DTD 文档的描述能力有限。
针对 DTD 的缺陷,W3C 在 2001 年推出 XSD。XSD(XML Schemas Definition)即 XML Schema 语言。XML Schema 本身就是一个 XML文档,使用的是 XML 语法,因此可以很方便的解析 XSD 文档。相对于 DTD,XSD 具有如下优势:
- XML Schema 基于 XML ,没有专门的语法。
- XML Schema 可以象其他 XML 文件一样解析和处理。
- XML Schema 比 DTD 提供了更丰富的数据类型。
- XML Schema 提供可扩充的数据模型。
- XML Schema 支持综合命名空间。
- XML Schema 支持属性组。
spring中定义了一些验证模式:
/**
* Indicates that the validation should be disabled. 禁用验证模式
*/
public static final int VALIDATION_NONE = XmlValidationModeDetector.VALIDATION_NONE; /**
* Indicates that the validation mode should be detected automatically. 自动获取验证模式
*/
public static final int VALIDATION_AUTO = XmlValidationModeDetector.VALIDATION_AUTO; /**
* Indicates that DTD validation should be used. DTD验证模式
*/
public static final int VALIDATION_DTD = XmlValidationModeDetector.VALIDATION_DTD; /**
* Indicates that XSD validation should be used. XSD验证模式
*/
public static final int VALIDATION_XSD = XmlValidationModeDetector.VALIDATION_XSD;
XmlBeanDefinitionReader#detectValidationMode(Resource resource)函数是检测资源文件的验证模式的:
protected int detectValidationMode(Resource resource) {
// 如果资源已经被打开,则直接抛出异常
if (resource.isOpen()) {
throw new BeanDefinitionStoreException(
"Passed-in Resource [" + resource + "] contains an open stream: " +
"cannot determine validation mode automatically. Either pass in a Resource " +
"that is able to create fresh streams, or explicitly specify the validationMode " +
"on your XmlBeanDefinitionReader instance.");
}
// 打开InputStream流
InputStream inputStream;
try {
inputStream = resource.getInputStream();
} catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Unable to determine validation mode for [" + resource + "]: cannot open InputStream. " +
"Did you attempt to load directly from a SAX InputSource without specifying the " +
"validationMode on your XmlBeanDefinitionReader instance?", ex);
}
try {
// 检测InputStream到底使用哪一种验证模式
// 核心逻辑
return this.validationModeDetector.detectValidationMode(inputStream);
} catch (IOException ex) {
throw new BeanDefinitionStoreException("Unable to determine validation mode for [" +
resource + "]: an error occurred whilst reading from the InputStream.", ex);
}
}
其核心功能:检测资源文件的验证模式是委托给XmlValidationModeDetector#detectValidationMode(InputStream inputStream)
public int detectValidationMode(InputStream inputStream) throws IOException {
// 将InputStream进行包装,便于读取
// Peek into the file to look for DOCTYPE.
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
try {
// 是否为DTD验证模式,默认为false,即不是DTD验证模式,那就是XSD验证模式
boolean isDtdValidated = false;
String content;
// 循环读取xml资源的内容
while ((content = reader.readLine()) != null) {
// 消费注释内容,返回有用信息
content = consumeCommentTokens(content);
// 如果为注释,或者为空,则继续循环
if (this.inComment || !StringUtils.hasText(content)) {
continue;
}
// #1.如果包含"DOCTYPE",则为DTD验证模式
if (hasDoctype(content)) {
isDtdValidated = true;
break;
}
// #2.该方法会校验,内容中是否有"<",并且"<"后面还跟着字母,如果是则返回true
// 如果为true,最终就是XSD模式
if (hasOpeningTag(content)) {
// End of meaningful data...
break;
}
}
// 返回DTD模式或XSD模式
return (isDtdValidated ? VALIDATION_DTD : VALIDATION_XSD);
} catch (CharConversionException ex) {
// Choked on some character encoding...
// Leave the decision up to the caller.
// 如果发生异常,则返回自动验证模式
return VALIDATION_AUTO;
} finally {
reader.close();
}
}
分析:
这里会遍历资源的内容进行文件验证模式的判断
- consumeCommentTokens(String line)
/**
* 注释开始标志 <br/>
* The token that indicates the start of an XML comment.
*/
private static final String START_COMMENT = "<!--"; /**
* 注释结束标志"-->" <br/>
* The token that indicates the end of an XML comment.
*/
private static final String END_COMMENT = "-->"; private String consumeCommentTokens(String line) {
// 非注释,即为有用信息
if (!line.contains(START_COMMENT) && !line.contains(END_COMMENT)) {
return line;
}
String currLine = line;
// 消耗注释内容,使循环跳向下一行
while ((currLine = consume(currLine)) != null) {
// 当inComment标志位更新,并且返回信息不是以注释开始标志开始就返回currLine
if (!this.inComment && !currLine.trim().startsWith(START_COMMENT)) {
return currLine;
}
}
// 如果没有有用信息,则返回null
return null;
}
分析:
- 如果当前行不是注释,则直接返回。
- consume函数的主要作用是消耗注释内容,继续循环下一行的内容。
private String consume(String line) {
// 如果inComment:true,则走endComent函数;false,则走startComment函数,初始时为false
// 因此这里会走startComment,返回注释位置的index[注释位置+1的index]
int index = (this.inComment ? endComment(line) : startComment(line));
// 如果index=-1,则表示没有注释信息,否则返回注释信息
return (index == -1 ? null : line.substring(index));
}
private int startComment(String line) {
// 返回注释开始标志的位置信息
return commentToken(line, START_COMMENT, true);
}
private int endComment(String line) {
return commentToken(line, END_COMMENT, false);
}
private int commentToken(String line, String token, boolean inCommentIfPresent) {
// 查找注释标志的开始位置[<!--或-->]
int index = line.indexOf(token);
// index>-1表示存在注释开始标志,并将inComment更新为inCommentIfPresent
// [默认在startComment为true,endComment为false]
if (index > -1) {
this.inComment = inCommentIfPresent;
}
// 如果index=-1,则返回注释标志的后一个位置信息index+token.length()
return (index == -1 ? index : index + token.length());
}
分析:
- consume函数意在消费注释信息,继续循环下一行的内容。
- inComment用来标记当前内容是否为注释,初始时为false,所以刚开始碰到一个注释语句,会执行startComment(line),将inComment置为true,然后返回"<!--"后面的内容,此时inComment为true,则会继续循环,此时会执行endComment(line),将inComment置为false,然后会返回"",在detectValidationMode函数中由于content="",此时会继续循环,从而跳过注释内容。
消费注释信息这里稍微有点绕,通过下面流程图可更好的理解:

文件验证模式代码分析完成,这里回到DefaultDocumentLoader#loadDocument:
public Document loadDocument(InputSource inputSource,
EntityResolver entityResolver,
ErrorHandler errorHandler,
int validationMode,
boolean namespaceAware) throws Exception {
// 创建DocumentBuilderFactory
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isTraceEnabled()) {
logger.trace("Using JAXP provider [" + factory.getClass().getName() + "]");
}
// 创建DocumentBuilder对象
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
// 通过DocumentBuilder解析InputSource,返回Document对象
// 解析xml文件的具体过程都是通过jdk内置的类进行解析的--DOMParser为其入口
return builder.parse(inputSource);
}
分析:
- 首先根据验证模式和是否支持命名空间创建DocumentBuilderFactory。
- 然后创建DocumentBuilder对象。
- 最后进行XML文件的解析,具体解析过程是利用jdk内置的DOMParser解析器进行解析。
DefaultDocumentLoader#createDocumentBuilderFactory:
protected DocumentBuilderFactory createDocumentBuilderFactory(int validationMode, boolean namespaceAware)
throws ParserConfigurationException {
// 创建DocumentBuilderFactory实例
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 设置是否支持命名空间
factory.setNamespaceAware(namespaceAware);
// 是否有校验模式
if (validationMode != XmlValidationModeDetector.VALIDATION_NONE) {
// 开启校验模式
factory.setValidating(true);
// XSD模式下设置factory的属性
if (validationMode == XmlValidationModeDetector.VALIDATION_XSD) {
// Enforce namespace aware for XSD...
// 如果为XSD模式,强制开启命名空间支持
factory.setNamespaceAware(true);
try {
// 设置SCHEMA_LANGUAGE_ATTRIBUTE属性为XSD
factory.setAttribute(SCHEMA_LANGUAGE_ATTRIBUTE, XSD_SCHEMA_LANGUAGE);
} catch (IllegalArgumentException ex) {
ParserConfigurationException pcex = new ParserConfigurationException(
"Unable to validate using XSD: Your JAXP provider [" + factory +
"] does not support XML Schema. Are you running on Java 1.4 with Apache Crimson? " +
"Upgrade to Apache Xerces (or Java 1.5) for full XSD support.");
pcex.initCause(ex);
throw pcex;
}
}
} return factory;
}
分析:这里逻辑就非常简单了,主要创建DocumentBuilderFactory对象,然后设置校验模式等相关属性。
DefaultDocumentLoader#createDocumentBuilder:
protected DocumentBuilder createDocumentBuilder(DocumentBuilderFactory factory,
@Nullable EntityResolver entityResolver, @Nullable ErrorHandler errorHandler)
throws ParserConfigurationException {
// 创建DocumentBuilder对象
DocumentBuilder docBuilder = factory.newDocumentBuilder();
// 设置实体解析器
if (entityResolver != null) {
docBuilder.setEntityResolver(entityResolver);
}
// 设置错误处理器
if (errorHandler != null) {
docBuilder.setErrorHandler(errorHandler);
}
return docBuilder;
}
分析:根据DocumentBuilderFactory工厂创建DocumentBuilder对象,并设置实体解析器与错误处理器。
XML文件的具体解析利用了jdk内置的DOMParser类进行,这里就不在深入了。
到这里就得到了XML配置文件的Document实例,介于篇幅原因,注册bean的过程将后面进行分析。
总结
这里总结下本文的重点:
- Resource体系与ResourceLoader体系,加载资源这里比较重要,因为有了资源才能进行后面的BeanDefinition加载。
- 检测配置文件是如何确定文件的验证模式,确定验证模式这里做的比较巧妙,着重如何消费注释信息继续下一次循环。
by Shawn Chen,2018.12.5日,下午。
【spring源码分析】IOC容器初始化(二)的更多相关文章
- SPRING源码分析:IOC容器
在Spring中,最基本的IOC容器接口是BeanFactory - 这个接口为具体的IOC容器的实现作了最基本的功能规定 - 不管怎么着,作为IOC容器,这些接口你必须要满足应用程序的最基本要求: ...
- Spring源码解析-ioc容器的设计
Spring源码解析-ioc容器的设计 1 IoC容器系列的设计:BeanFactory和ApplicatioContext 在Spring容器中,主要分为两个主要的容器系列,一个是实现BeanFac ...
- spring源码分析---IOC(1)
我们都知道spring有2个最重要的概念,IOC(控制反转)和AOP(依赖注入).今天我就分享一下spring源码的IOC. IOC的定义:直观的来说,就是由spring来负责控制对象的生命周期和对象 ...
- spring 源码之 ioc 容器的初始化和注入简图
IoC最核心就是两个过程:IoC容器初始化和IoC依赖注入,下面通过简单的图示来表述其中的关键过程:
- Spring源码阅读-IoC容器解析
目录 Spring IoC容器 ApplicationContext设计解析 BeanFactory ListableBeanFactory HierarchicalBeanFactory Messa ...
- Spring 源码剖析IOC容器(一)概览
目录 一.容器概述 二.核心类源码解读 三.模拟容器获取Bean ======================= 一.容器概述 spring IOC控制反转,又称为DI依赖注入:大体是先初始化bean ...
- Spring源码解析-IOC容器的实现
1.IOC容器是什么? IOC(Inversion of Control)控制反转:本来是由应用程序管理的对象之间的依赖关系,现在交给了容器管理,这就叫控制反转,即交给了IOC容器,Spring的IO ...
- Spring源码解析-IOC容器的实现-ApplicationContext
上面我们已经知道了IOC的建立的基本步骤了,我们就可以用编码的方式和IOC容器进行建立过程了.其实Spring已经为我们提供了很多实现,想必上面的简单扩展,如XMLBeanFacroty等.我们一般是 ...
- Spring源码之IOC容器创建、BeanDefinition加载和注册和IOC容器依赖注入
总结 在SpringApplication#createApplicationContext()执行时创建IOC容器,默认DefaultListableBeanFactory 在AbstractApp ...
随机推荐
- Lenovo System x3650 设置管理接口地址
1.开启服务器. 2.显示<F1> Setup提示后,按 F1.(此提示在屏幕上仅显示几秒钟.必须迅速按 F1.) 如果同时设置了开机密码和管理员密码,则必须输入管理员密码才能访问完整的 ...
- .NET微服务调查结果
.NET Core就是专门针对模块化的微服务架构而设计, 在2018年国庆时间展开.NET微服务的使用情况,本次调查我们总计收到了来自378个开发者的调查.从落地现状.架构体系.未来趋势等方面对微服务 ...
- CORS的简单理解
去年我在做一个项目,是关于标签打印的,它就是一个Windows程序,提供标签打印功能,由其它程序(包括网站)告诉它需要打印怎样的标签,它就出标签,这个“告诉它需要怎样的标签”的过程,是通过HTTP的P ...
- .NET WebAPI中使用Session使用
问题及其解决方案: 今天做项目的时候因为需要编写一个短信验证码的接口我需要在我的后台.net webapi中存入我随机生成的短信验证码方便与前端传递过来的数据对比,所以决定使用session做缓存.但 ...
- 中国IT史上两大严重事故对我们的警醒及预防措施
20190121 一,历史回顾:20150528携程运维大事故 2015年5月28日上午11点开始,携程旅行网官方网站突然显示404错误页,App也无法使用,业务彻底中断. 据称是因为乌云网公布了携程 ...
- CSS揭秘—灵活的背景图(三)
前言: 所有实例均来自<CSS揭秘>,该书以平时遇到的疑难杂症为引,提供解决方法,只能说秒极了,再一次刷新了我对CSS的认知 该书只提供了关键CSS代码,虽然有在线示例代码链接,但访问速度 ...
- Linux如何查看与测试磁盘IO性能
1. 查看磁盘 IO 性能 1.1 top 命令 top 命令通过查看 CPU 的 wa% 值来判断当前磁盘 IO 性能,如果这个数值过大,很可能是磁盘 IO 太高了,当然也可能是其他原因,例如网络 ...
- 如何为ASP.NET Core设置客户端IP白名单验证
原文链接:Client IP safelist for ASP.NET Core 作者:Damien Bowden and Tom Dykstra 译者:Lamond Lu 本篇博文中展示了如何在AS ...
- windows快捷键十八式(win10)
胖友,如果你的电脑是windows系统,下面这十八招windows快捷键都不会,还敢说你会用windows? 说到windows的快捷键,当然不是只有ctrl+c,ctrl+v这么简单,今天我整理了一 ...
- 声明式RESTful客户端在asp.net core中的应用
1 声明式RESTful客户端 声明式服务调用的客户端,常见有安卓的Retrofit.SpringCloud的Feign等,.net有Refit和WebApiClient,这些客户端都是以java或. ...