Scala进阶之路-Spark本地模式搭建
Scala进阶之路-Spark本地模式搭建
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Spark简介
1>.Spark的产生背景
传统式的Hadoop缺点主要有以下两点:
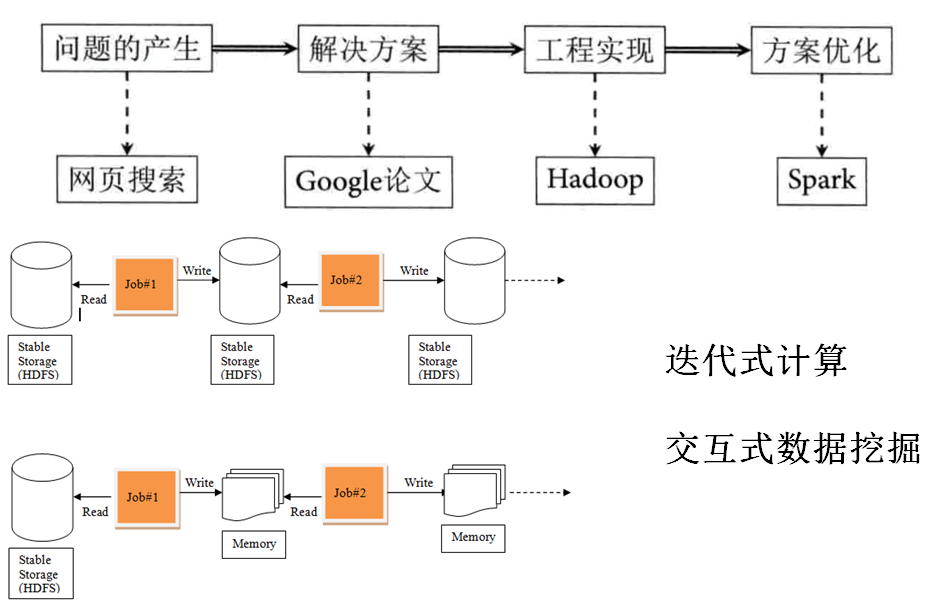
第一.迭代式计算效率低(一个MapReduce依赖上一个MapReduce的结果);
第二.交互式数据挖掘效率低(运行一个HIVE语句效率是极低的,第一天输入的SQL可能等到第二天才能拿到结果)
Spark优化了Hadoop的两个缺点,可以将多个job合并成一个job来执行,也可以将于磁盘的交互迁移到内存进行交互,从而提升了工作效率。
2>.Spark是什么
、软件栈中所有的程序库和高级组件 都可以从下层的改进中获益。 、运行整个软件栈的代价变小了。不需要运行5到10套独立的软件系统了,一个机构只需要运行一套软件系统即可。系统的部署、维护、测试、支持等大大缩减。 、能够构建出无缝整合不同处理模型的应用。

Spark Core:
实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统 交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
Spark SQL:
是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming:
是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib:
提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
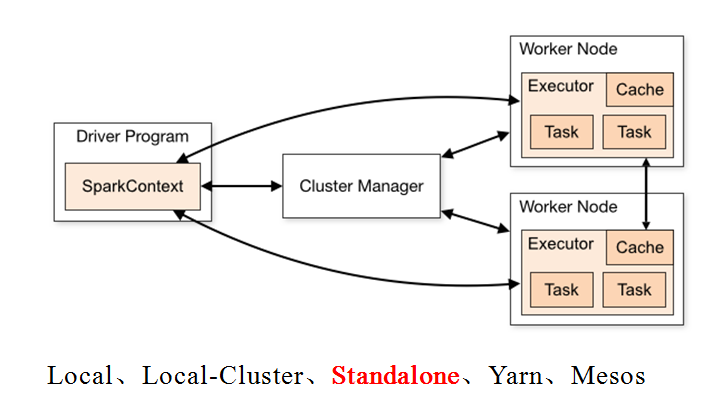
集群管理器:
Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度 器,叫作独立调度器。 Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
3>.Spark的安装模式
安装模式可分为以下几种:
Local、Local-Cluster、Standalone、Yarn、Mesos Master节点主要运行集群管理器的中心化部分,所承载的作用是分配Application到Worker节点,维护Worker节点,Driver,Application的状态。 Worker节点负责具体的业务运行。
二.部署Spark本地模式
1>.下载Spark软件
官网下载地址:http://spark.apache.org/downloads.html
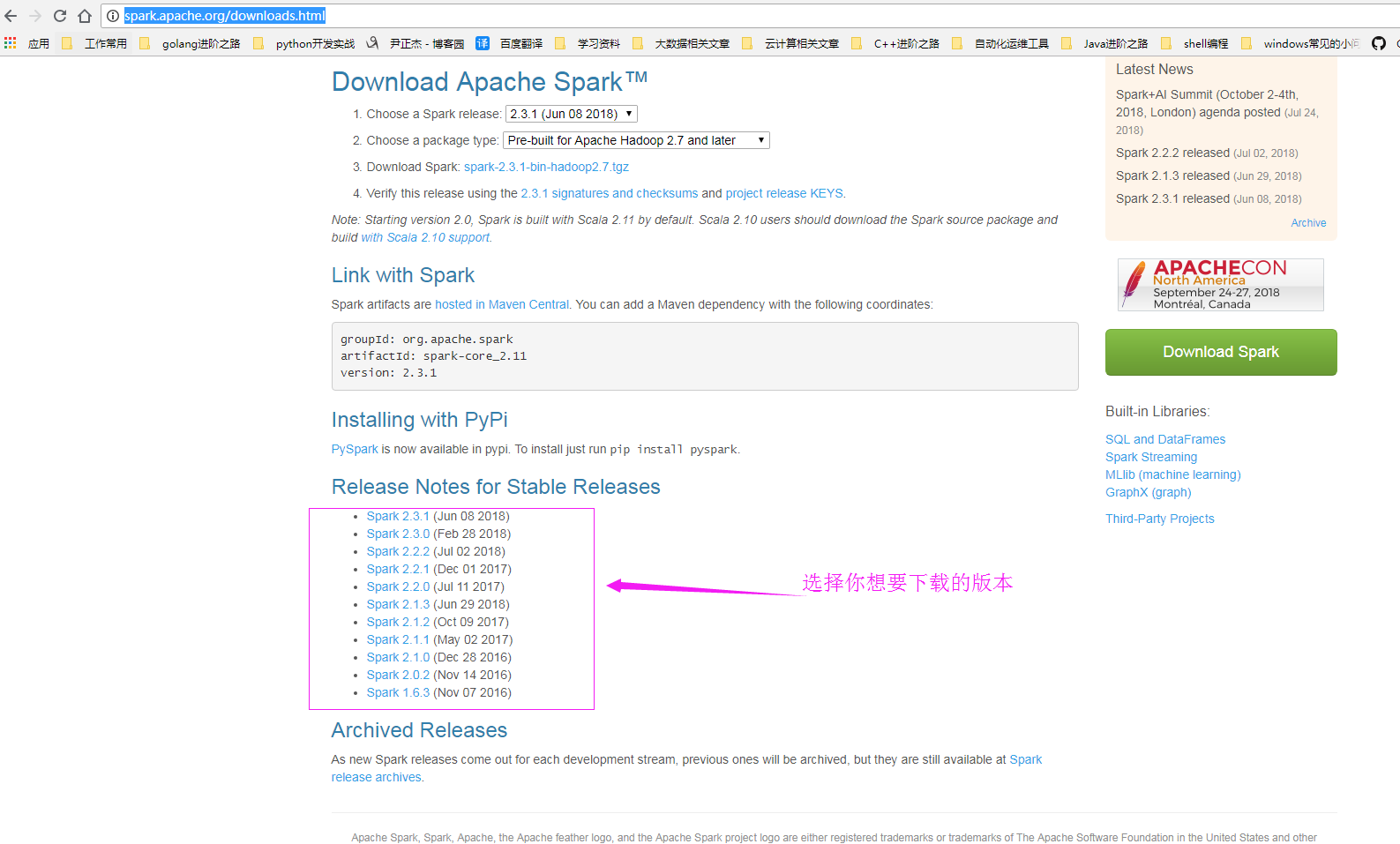
当然点上面的网页只是对该版本的支持,允许我调戏你一下,哈哈,实际上下载位置应该在这里:https://archive.apache.org/dist/spark/ 。
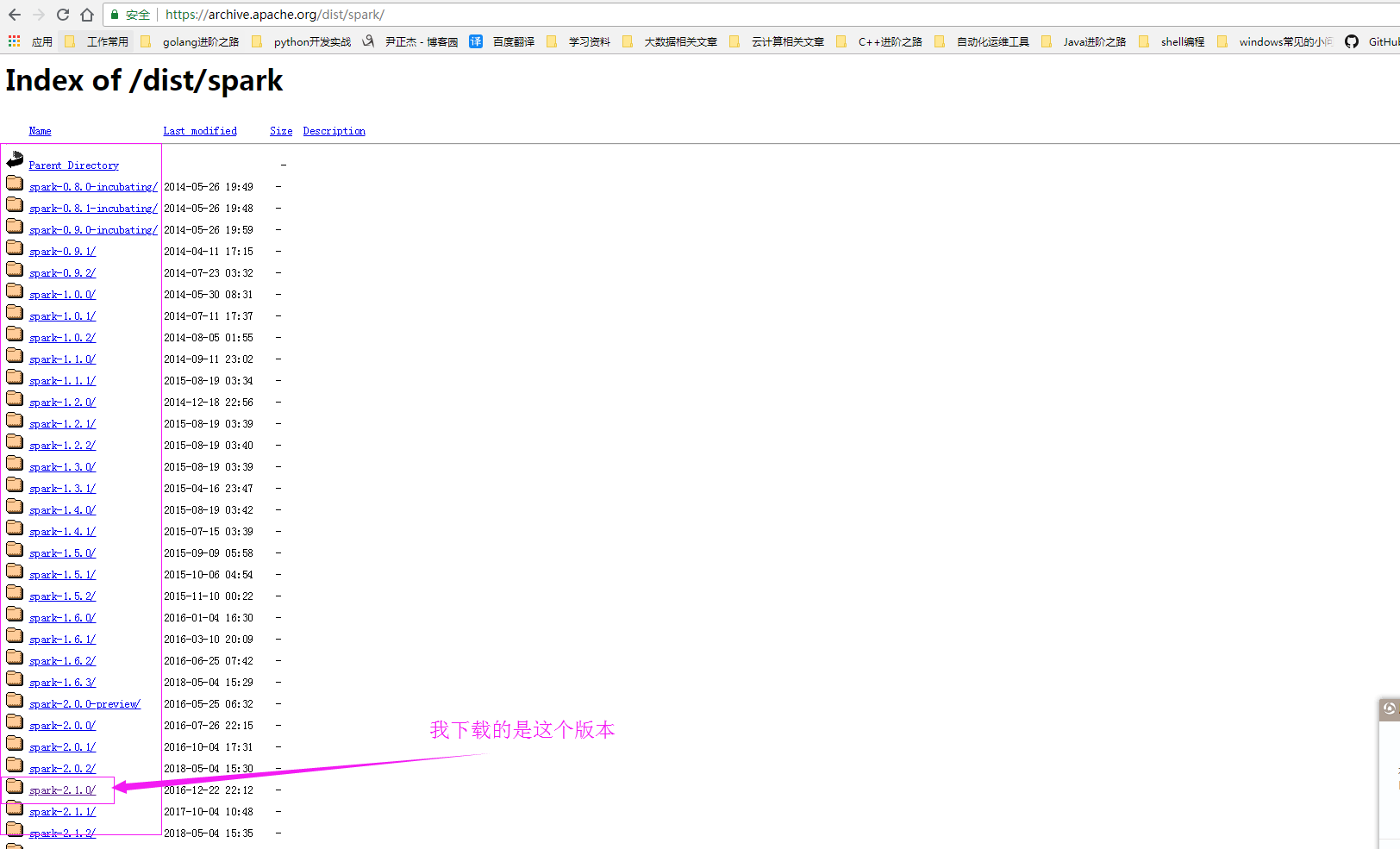
2>.解压下载的Spark并创建软连接
[yinzhengjie@s101 download]$ wget https://archive.apache.org/dist/spark/spark-2.1.0/spark-2.1.0-bin-hadoop2.7.tgz
[yinzhengjie@s101 download]$ ll
total
-rw-r--r-- yinzhengjie yinzhengjie Jan spark-2.1.-bin-hadoop2..tgz
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ tar -zxf spark-2.1.-bin-hadoop2..tgz -C /soft/
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ ln -s /soft/spark-2.1.-bin-hadoop2./ /soft/spark
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ ll /soft/ | grep spark
lrwxrwxrwx yinzhengjie yinzhengjie Jul : spark -> /soft/spark-2.1.-bin-hadoop2./
drwxr-xr-x yinzhengjie yinzhengjie Dec spark-2.1.-bin-hadoop2.
[yinzhengjie@s101 download]$
3>.配置环境变量并使环境变量生效
[yinzhengjie@s101 download]$ tail - /etc/profile
#ADD spark Path
export SPARK_HOME=/soft/spark
PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ source /etc/profile
[yinzhengjie@s101 download]$
4>.启动Spark

5>.查看进程是否启动

6>.查看WebUI界面

三.Spark初体验-使用Spark实现单词统计
1>.创建测试文件
[yinzhengjie@s101 download]$ cat /home/yinzhengjie/.txt
hello world
yinzhengjie hello word
hello scala
hello java
hello python
hello shell
hello yinzhengjie
hello golang
[yinzhengjie@s101 download]$
2>.实现单词统计
体验Spark
----------------------
.登录spark
spark-shell .编写scala代码
//1.加载文本
val rdd1 = sc.textFile("/home/yinzhengjie/1.txt")
//2.压扁
val rdd2 = rdd1.flatMap(line=>{line.split(" ")})
//3.变换,标1成对
val rdd3 = rdd2.map(word=>{(word , )})
//4.按照key进行化简
val rdd4 = rdd3.reduceByKey((a,b)=> a + b).sortBy(t=> -t._2 )
//5.输出结果
rdd4.collect() .一行完成
sc.textFile("/home/yinzhengjie/1.txt").flatMap(_.split(" ")).map((_,)).reduceByKey(_+_).sortBy(t=> -t._2 ).collect()

Scala进阶之路-Spark本地模式搭建的更多相关文章
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- Scala进阶之路-Spark底层通信小案例
Scala进阶之路-Spark底层通信小案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark Master和worker通信过程简介 1>.Worker会向ma ...
- Scala进阶之路-为什么要学习Scala以及开发环境搭建
Scala进阶之路-为什么要学习Scala以及开发环境搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 最近人工智能和大数据那是相当的火呀,人工智能带动了Python的流行,区块 ...
- Scala进阶之路-idea下进行spark编程
Scala进阶之路-idea下进行spark编程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 1>.创建新模块并添加maven依赖 <?xml version=&qu ...
- Spark进阶之路-Spark HA配置
Spark进阶之路-Spark HA配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 集群部署完了,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借 ...
- Scala进阶之路-Scala的基本语法
Scala进阶之路-Scala的基本语法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.函数式编程初体验Spark-Shell之WordCount var arr=Array( ...
- Scala进阶之路-Scala中的高级类型
Scala进阶之路-Scala中的高级类型 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.类型(Type)与类(Class)的区别 在Java里,一直到jdk1.5之前,我们说 ...
- Scala进阶之路-Scala高级语法之隐式(implicit)详解
Scala进阶之路-Scala高级语法之隐式(implicit)详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们调用别人的框架,发现少了一些方法,需要添加,但是让别人为你一 ...
- Scala进阶之路-并发编程模型Akka入门篇
Scala进阶之路-并发编程模型Akka入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Akka Actor介绍 1>.Akka介绍 写并发程序很难.程序员不得不处 ...
随机推荐
- Jquery画折线图、柱状图、饼图
1.今天做了一个折线图,首先需要导js文件.这里有一个demo:http://files.cnblogs.com/files/feifeishi/jquery_zhexiantubingtuzhuzh ...
- shell脚本--权限分配
因为shell脚本内部是很多命令的集合,这些命令也许会涉及到操作某一个文件,而且shell脚本的运行,也是需要当前用户对脚本具有运行的权限,否则,会因为权限不够而失败. 首先最重要的一点:修改权限,只 ...
- shell脚本--shift参数左移
参数左移什么意思呢?这个参数指的是在运行脚本时,跟在脚本名后面的参数,前面已经讲过,可以使用$#来获取参数的个数,使用$*来获取所有的参数,而参数左移的含义是这样的:有个指针指向参数列表第一个参数,左 ...
- What Is Apache Hadoop
What Is Apache Hadoop? The Apache™ Hadoop® project develops open-source software for reliable, scala ...
- ASP.NET MVC自定义异常处理
1.自定义异常处理过滤器类文件 新建MyExceptionAttribute.cs异常处理类文件
- 关于virtualenv python环境引用 pycharm相关配置的使用讨论
今天总算决定来搞一波以前从来没有弄清楚的环境问题,也觉得是时候弄明白了. 这里先说关于python的环境引用,再谈到virtualenv最后再谈论我使用的pycharm5.0关于是用python环境的 ...
- Ideal test 不执行main方法了
参考:idea 导入项目后不能执行main方法 用了ideal之后,发现自己的项目里面没有test文件夹,自己建了一个,发现竟然不能执行main函数, 后来经过点播之后,才知道,光建立文件夹是没用的, ...
- Delphi的关键字
Constructor;构造器,定义构造函数使用Constructor关键字
- AGC005F Many Easy Problems(NTT)
先只考虑求某个f(k).考虑转换为计算每条边的贡献,也即该边被所选连通块包含的方案数.再考虑转换为计算每条边不被包含的方案数.这仅当所选点都在该边的同一侧.于是可得f(k)=C(n,k)+ΣC(n,k ...
- Python函数绘图
最近看数学,发现有时候画个图还真管用,对理解和展示效果都不错.尤其是三维空间和一些复杂函数,相当直观,也有助于解题.本来想用mathlab,下载安装都太费事,杀鸡不用牛刀,Python基本就能实现.下 ...