Mac下hadoop运行word count的坑
Mac下hadoop运行word count的坑
Word count体现了Map Reduce的经典思想,是分布式计算中中的hello world。然而博主很幸运地遇到了Mac下特有的问题Mkdirs failed to create,特此记录
一、代码
- WCMapper.java
package wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
/**
* 四个泛型中,前两个是指mapper输入的数据类型
* KEYIN是输入的key类型,VALUEIN是输入的value类型
* map和reduce的数据输入输出都是以key-value对的形式分装的
* 默认情况下,框架传递给我们的mapper的输入数据中
* key是要处理的文本中第一行的起始偏移量,value是这一行的内容
*
* Long->LongWritable实现hadoop自己的序列化接口,内容更精简,传输效率高
* String->Text
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
//mapreduce框架每一行数据就调用一次改方法
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 具体的业务逻辑就写在这个方法中,而且需要的处理的key-value已经传递进来
// 将这一行的内容转换成string
String line = value.toString();
// 切分单词
String[] words = StringUtils.split(line, ' ');
// 通过context把结果输出
for (String word: words){
context.write(new Text(word), new LongWritable(1));
}
}
}
- WCReducer.java
package wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
// 框架在map处理完成之后,将所有k-v对缓存起来
// 进行分组,然后传递一个组<key, values{}>
// 调用一次reduce方法
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
// 遍历values,累加求和
for (LongWritable value: values){
count += value.get();
}
// 输出这一个单词的统计结果
context.write(key, new LongWritable(count));
}
}
- WCRunner.java(启动项)
package wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 用来描述一个特定的作业
* 比如,该作业使用哪个类作为逻辑处理的map,哪个作为reduce
* 还可以指定该作业要需要的数据所在的路径
* 还可以指定该作业输出的结果放到哪个路径
*/
public class WCRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 设置整个job需要的jar包
// 通过WCRuner来找到其他依赖WCMapper和WCReducer
job.setJarByClass(WCRunner.class);
// 本job使用的mapper和reducer类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
// 指定reducer的输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定mapper的输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 指定原始数据存放在哪里
FileInputFormat.setInputPaths(job,new Path("/wc/input/"));
// 指定处理结果的输出数据存放在哪里
FileOutputFormat.setOutputPath(job, new Path("/wc/output/"));
// 将job提交运行
job.waitForCompletion(true);
}
}
二、问题重现
写好代码后打包成jar,博主是用IDEA直接图形化操作的,然后提交到hadoop上运行
hadoop jar hadoopStudy.jar wordcount.WCRunner
结果未像官网和其他很多教程中说的那样出结果,而是报错
Exception in thread "main" java.io.IOException: Mkdirs failed to create /var/folders/vf/rplr8k812fj018q5lxcb5k940000gn/T/hadoop-unjar1598612687383099338/META-INF/license
at org.apache.hadoop.util.RunJar.ensureDirectory(RunJar.java:146)
at org.apache.hadoop.util.RunJar.unJar(RunJar.java:119)
at org.apache.hadoop.util.RunJar.unJar(RunJar.java:94)
at org.apache.hadoop.util.RunJar.run(RunJar.java:227)
at org.apache.hadoop.util.RunJar.main(RunJar.java:153)
最后折腾了半天,发现是Mac的问题,在stackoverflow中找到解释
The issue is that a /tmp/hadoop-xxx/xxx/LICENSE file and a
/tmp/hadoop-xxx/xxx/license directory are being created on a
case-insensitive file system when unjarring the mahout jobs.
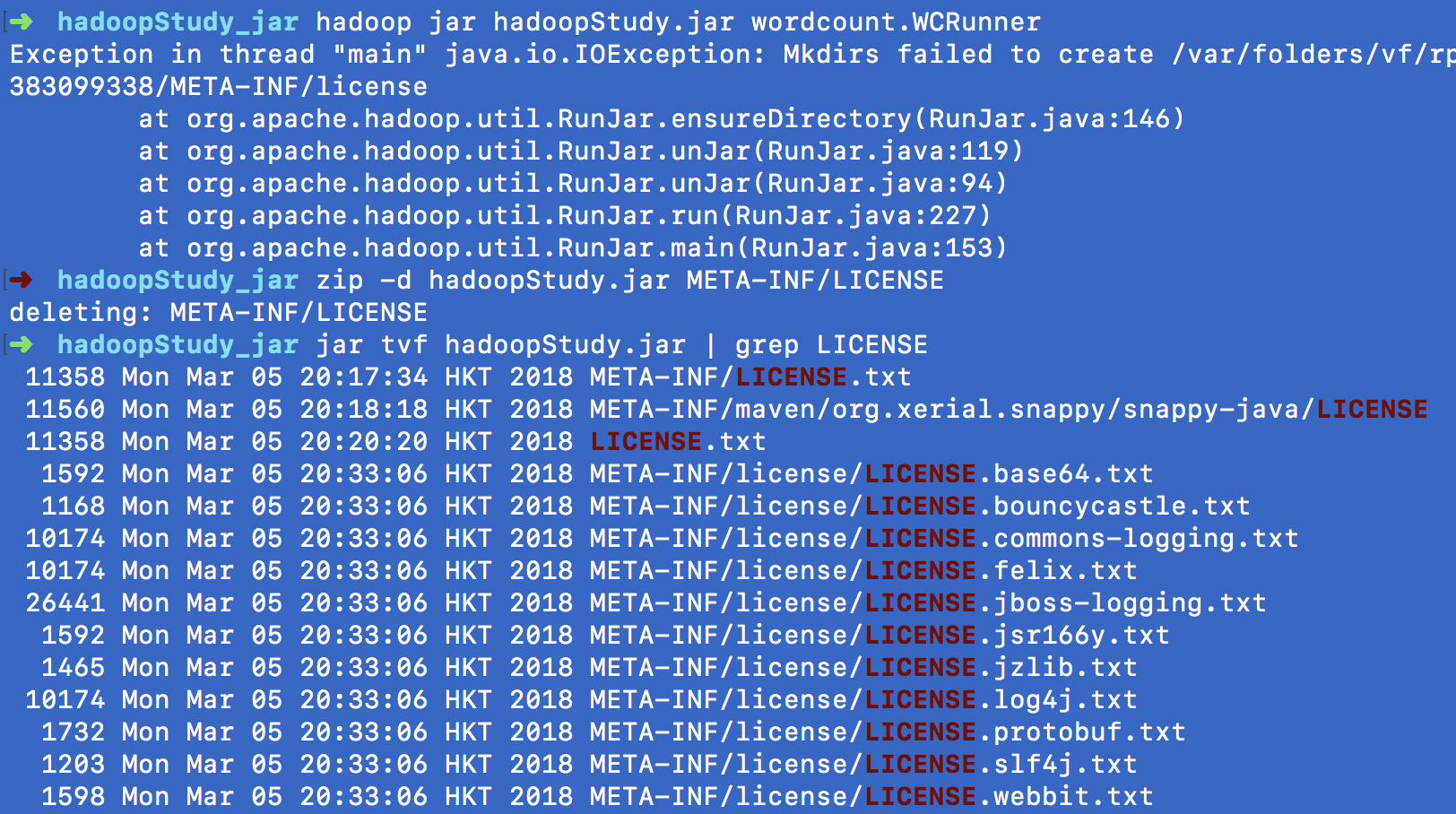
删除原来压缩包的META-INF/LICENS,再重新压缩,解决问题~
zip -d hadoopStudy.jar META-INF/LICENSE
jar tvf hadoopStudy.jar | grep LICENSE
然后把新的jar上传到hadoop上运行
hadoop jar hadoopStudy.jar wordcount.WCRunner
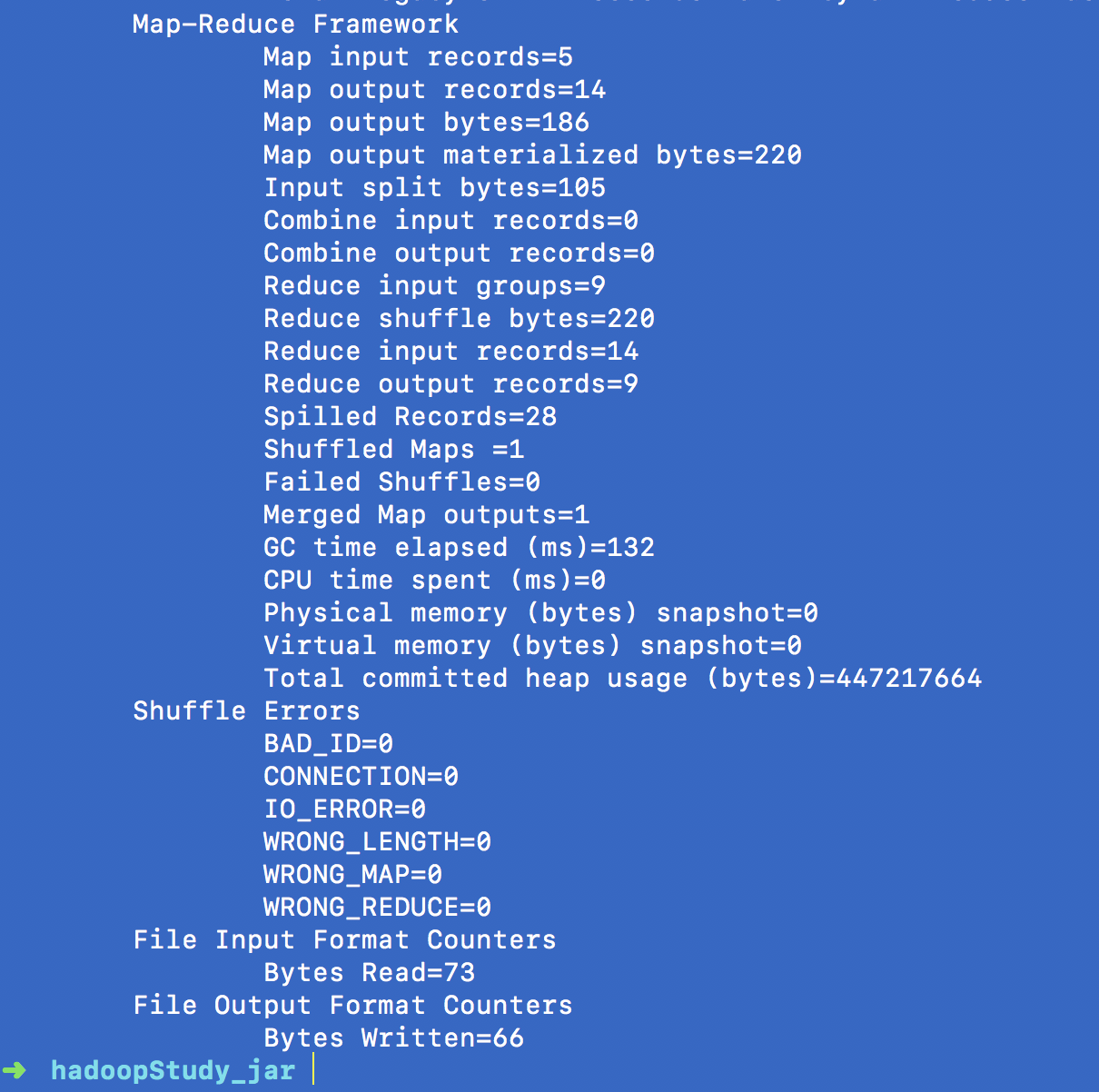
bingo!
三、运行结果
顺便用浏览器看一下运行结果
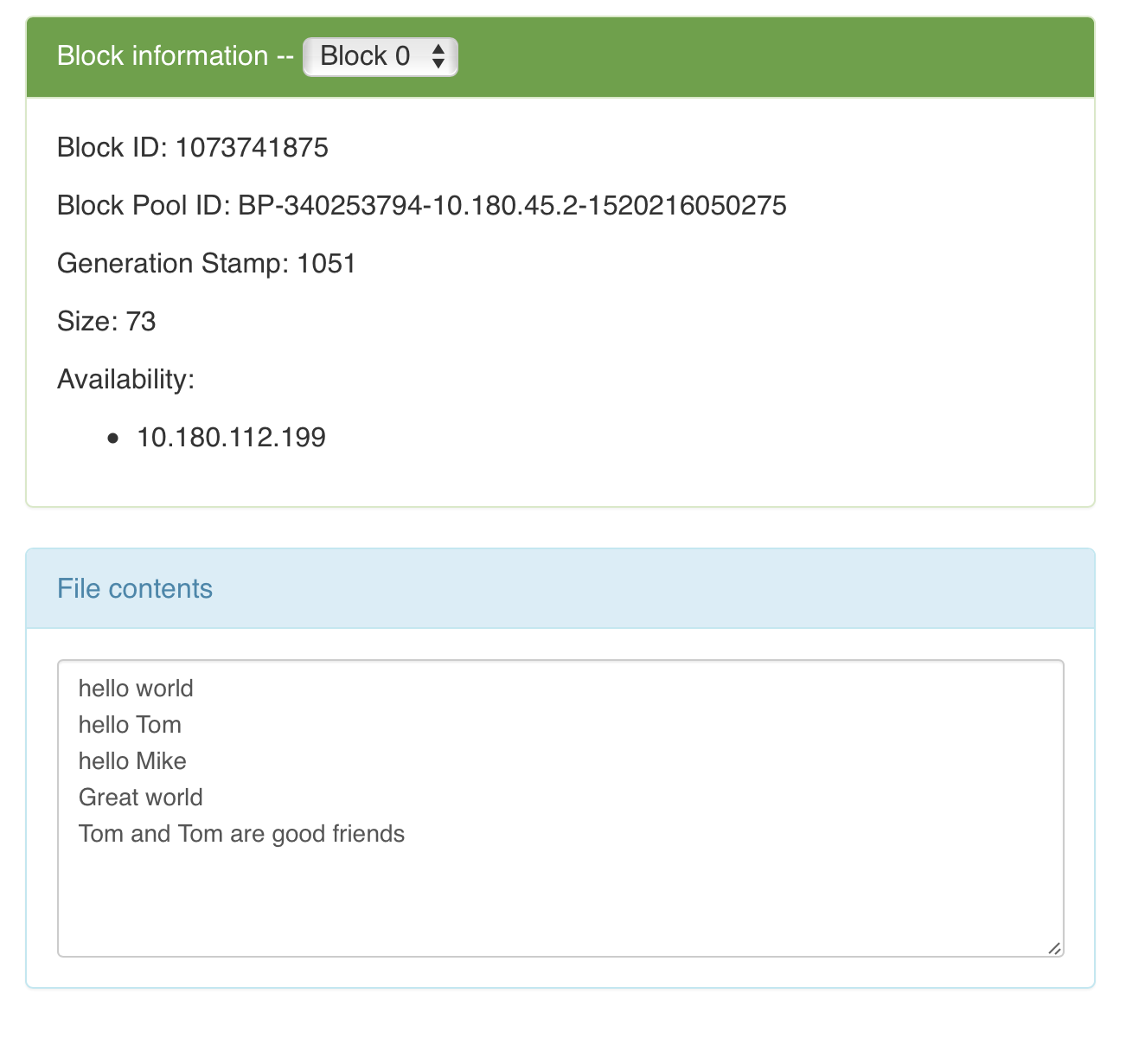
- 输入文件
wc/input/input.txt
- 输出文件
/wc/output/part-r-00000]
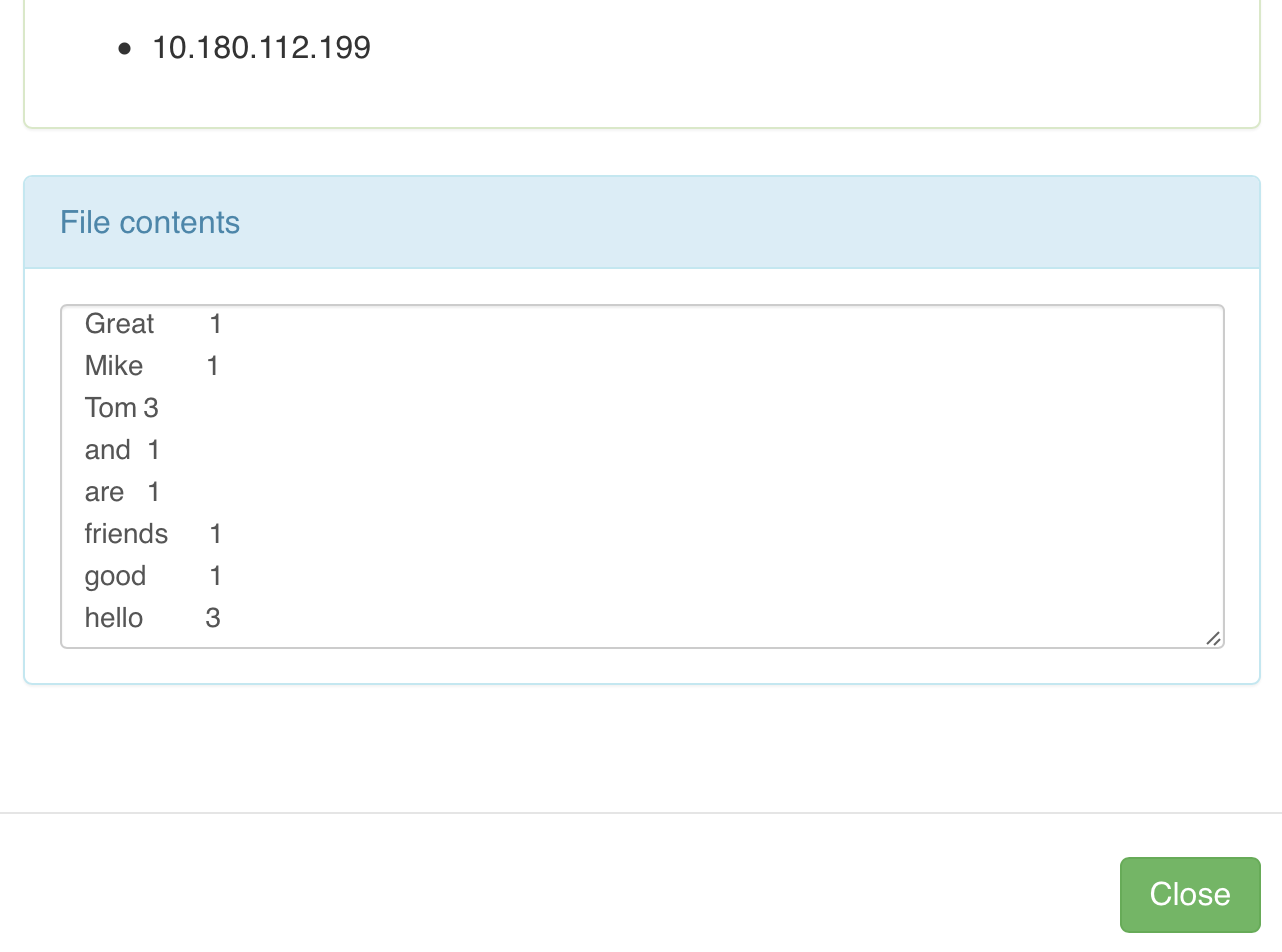
运行结果显然是正确的,再也不敢随便说Mac大法好了……
Mac下hadoop运行word count的坑的更多相关文章
- Mac 下安装运行Rocket.chat
最近花了一周的时间,复习了HTML.CSS.原生JS,并学习了Node.js.CoffeeScript.js.MongoDB,入了下门. 因为准备在Rocket.chat 上做二次开发,所以先下载和安 ...
- mac上eclipse上运行word count
1.打开eclipse之后,建立wordcount项目 package wordcount; import java.io.IOException; import java.util.StringTo ...
- Hadoop AWS Word Count 样例
在AWS里用Elastic Map Reduce 开一个Cluster 然后登陆master node并编译下面程序: import java.io.IOException; import java. ...
- mac 下php运行bug
如下所说bug在window下没有,在mac下存在. mac下的php报如下错误: fopen("data.json") Error: failed to open stream: ...
- [MapReduce_1] 运行 Word Count 示例程序
0. 说明 MapReduce 实现 Word Count 示意图 && Word Count 代码编写 1. MapReduce 实现 Word Count 示意图 1. Map:预 ...
- CentOS下Hadoop运行环境搭建
1.安装ssh免密登录 命令:ssh-keygen overwrite(覆盖写入)输入y 一路回车 将生成的密钥发送到本机地址 ssh-copy-id localhost (若报错命令无法找到则需要安 ...
- openssl1.0在mac下的编译安装(踩坑精华)
之前做了一次brew版本升级,然后用pip3安装的一个python命令就无法执行了(涉及到openssl库),执行就会报一个错误. ImportError: dlopen(/usr/local/Cel ...
- cgywin下 hadoop运行 问题
1 cgywin下安装hadoop需要配置JAVA_home变量 , 此时使用 window下安装的jdk就可以 ,但是安装路径不要带有空格.否则会不识别. 2 在Window下启动Hadoop ...
- Mac下怎么运行python3的py文件
我的Mac现在是10.14.6系统,默认自带的python版本是2.7.(怎么查看版本?打开终端,输入python即可看到版本号) 由于现在需要运行python3写的py文件,需要将自带的python ...
随机推荐
- Redis托管Session
一:redis托管session主要是为了不同域之间共享session.Asp.net提供了四种处理Session的方法 1. InProc模式 这是ASP.NET默认的Session管理模式,在应 ...
- SVG 图像入门教程
http://www.ruanyifeng.com/blog/2018/08/svg.html 一.概述 SVG 是一种基于 XML 语法的图像格式,全称是可缩放矢量图(Scalable Vector ...
- MySQl 查询性能优化相关
0. 1.参考 提升网站访问速度的 SQL 查询优化技巧 缓存一切数据,读取内存而不是硬盘IO 如果你的服务器默认情况下没有使用MySQL查询缓存,那么你应该开启缓存.开启缓存意味着MySQL 会把所 ...
- 【转】ArcGIS10.0完全卸载全攻略
ArcGIS10.0完全卸载详细步骤: 1.开始>控制面板>添加删除程序,卸载所有ArcGIS软件和帮助文档,以及所有ArcGIS补丁.2.从添加删除程序面板中删除所有Python相关的应 ...
- HTTP.sys远程执行代码漏洞
远程执行代码漏洞存在于 HTTP 协议堆栈 (HTTP.sys) 中,当 HTTP.sys 未正确分析经特殊设计的 HTTP 请求时会导致此漏洞. http://bbs.safedog.cn/thre ...
- JS元素意外点击元素消失
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Django1.11.7配置静态文件
Django配置静态文件分为三步 1.建文件夹 2.设置setting 3.页面引用 1.文件目录结构 在APP下新建static文件夹,将js和css文件放入文件夹 2.配置settings.py ...
- 033 Url中特殊字符的处理
在url跳转页面的时候,参数值中的#不见了,一直没有处理,今天有空看了一下,后来发现后台的过滤器之类的都没有处理,就比较奇怪了,原来是特殊字符的问题. 一:Url中的特殊字符 1.说明 这里还是需要做 ...
- Machine Learning 神器 - sklearn
Sklearn 官网提供了一个流程图, 蓝色圆圈内是判断条件,绿色方框内是可以选择的算法: 从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据. 由图中,可以看到算法有 ...
- 正则表达式在python中的简单使用
正则表达式独立与编程语言,基本上所有的编程语言都实现了正则表达式的相关操作.在Python中正则表达式的表现为re模块: import re 其操作有三个方法: my_string = "h ...