JVM垃圾回收(一)- 什么是垃圾回收
什么是垃圾回收?
垃圾回收是追踪所有正在被使用的对象,并标注剩余的为garbage。这里我们先从JVM的GC是如何实现的说起。
手动内存管理
在开始介绍垃圾回收之前,我们先复习一下手动内存管理。它是指你需要明确的为你的数据手动分配需要的空闲内存,但是如果用完后忘了free 掉这些内存,则之后也无法再次使用这部分内存。也就是说,这部分内存是属于被申明但未被继续使用。这种情况称为一个memory leak(内存泄漏)
下面是一个C语言写的一个例子,使用手动管理内存:
int send_request(){
size_t n = read_size();
int *elements = malloc(4 * sizeof(int));
if(read_elements(n, elements) < n){
// elements not freed
return -1;
}
free(elements)
return 0;
}
忘记free memory 可能是一件相当常见的事情。Memory Leak在过去也是一个较为常见的问题,而且仅能通过修改代码才能完全解决此问题。所以,一个更好的方法是:自动回收未被用的内存,减少人本身可能犯错的可能性。这种自动的机制就是垃圾回收(简称GC)
智能指针
自动垃圾回收的第一种方法基于reference counting(引用计数)。对每个object,简单的计算它被引用了多少次,如果次数为0,则这个object可以被安全的回收。一个很著名的例子是C++的shared pointers:
int send_request() {
size_t n = read_size();
shared_ptr<vector<int>> elements
= make_shared<vector<int>>();
if(read_elements(n, elements) < n) {
return -1;
}
return 0;
}
shared_ptr 用于追踪object被引用的数量。这个值会在object被传递时增加,在离开域时减少。一旦这个引用数量值到达0,shared_ptr 会自动删除它底层的vector。然而,这个例子在实际使用中并不普遍,不过作为一个展示的例子足够了。
自动内存管理
在上面的C++ 代码中,我们已经明确的说明了什么时候我们需要考虑好内存管理。如果我们让所有的object都使用这种自动回收内存的方式的话,肯定会方便开发人员做开发,因为他们不需要再去手动释放一些objects。Runtime会自动获取到哪些内存不会再被使用,并释放这些内存。换句话说,它会自动收集这部分垃圾。
第一个垃圾回收器在1959年创建,用于Lisp语言,并且从那时候开始,垃圾回收的技术才有进展。
引用计数法
上面介绍的C++ 的shared pointers 可以被应用到所有的objects。很多语言例如Perl,Python或PHP都使用了这种方法。下面的图片很好的展示了这个方法:
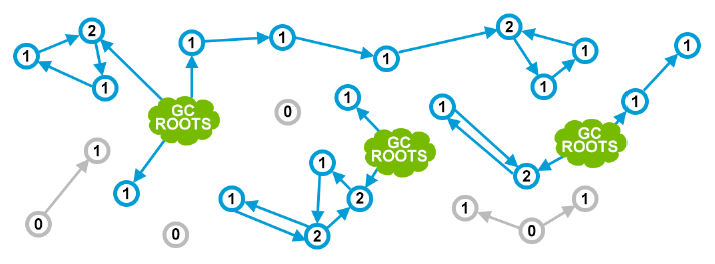
绿色的小云表示它们指向的objects仍然在被程序员使用。从技术层面来说,这些可能是正在执行的方法中的局部变量,或是静态变量等等。它可能在不同的编程语言中有不同的场景,这里我们不做进一步探讨。
蓝色的小环代表内存里当前活跃的objects,上面的数字表示它的引用计数。最后,灰色的小环表示没有被任何当前在使用的object(也就是之别被绿色的小云引用的)引用的objects。也就是说,灰色的小环就是需要被垃圾回收器清理的垃圾。
这个方法看起来好像很不错,但是它有一个很大的问题,即:如果是存在一个独立的有向回环的话,则这些object永远不会被回收,例如:
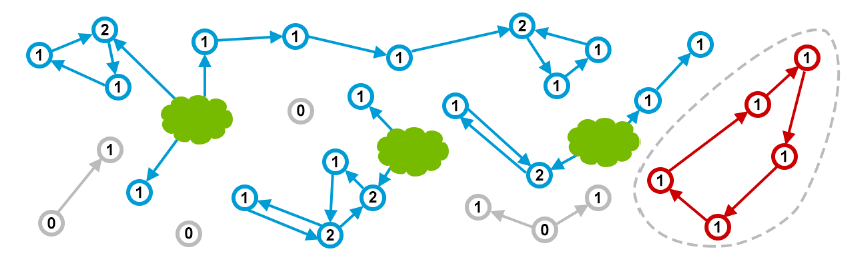
红色的圆环其实是需要被收集的垃圾,但是由于相互引用,引用计数不为1,所以不会被回收。所以这个方法仍旧会造成memory leak。
也有一些方法用于克服这个问题,例如使用一个特殊的 ‘weak‘ references 或应用一个单独的算法用于收集这些回环。像之前提到过的语言 – Perl,Python以及PHP,它们都会以某种方式处理这种回环并回收垃圾。当然,这部分超出了在此讨论的范围,我们仍会以讨论JVM采用的方法为主。
标记并清除
首先,JVM对于如何跟踪一个object会有更具体的信息,所以相对于之前模糊定义的绿色的小云,我们现在可以更清晰的定义那些被称为Garbage Collection Roots(垃圾回收根)的一系列对象:
- 局部变量
- 活跃的线程
- 静态区域
- JNI引用
在JVM中跟踪所有可达的(当前活跃的)对象,并确保那些uon-reachable对象申明的内存被再次重复使用的方法,称为Mark and Sweep(标记并清除)算法。它包含两个步骤:
- Marking(标记):从GC roots开始,遍历所有reachable对象,并在本地内存保存所有这些对象的一个记录
- Sweeping(清除):确保被non-reachable对象占用的内存空间可以在下一个allocation阶段时被重新使用
在JVM中的不同的GC 算法,例如Parallel Scavenge,Parallel Mark+Copy 或CMS,都实现了上面两个阶段,但是会存在一些细微的差别。但是从概念层次上,整个过程基本与上面两个步骤类似。
这个方法中最重要的是:解决了回环导致内存泄漏的问题。
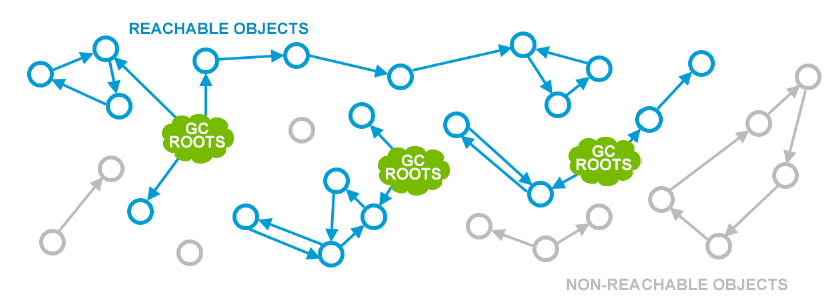
但是这个方法的一个不太好的点是:在collect发生时,应用的线程需要被暂时stopped(停止),因为如果状态是一直在变化的,则引用计数便不会特别准确。当所有应用被暂时stopped,以便让JVM可以完全管理这种内部活动时,这个场景被称为Stop The World pause。当然,STWP 发生的原因可能会有很多种,但是GC是其中最常见的一种。
Java 里的垃圾回收
之前对于Mark and Sweep 的垃圾回收的描述是一个最理论的介绍。在实际情况下,为了适应real-world的场景及需求,对此可能需要做大量的调整。作为一个简单的例子,下面看一下在我们安全的持续分配对象时,JVM所需要做的各类记录与操作。
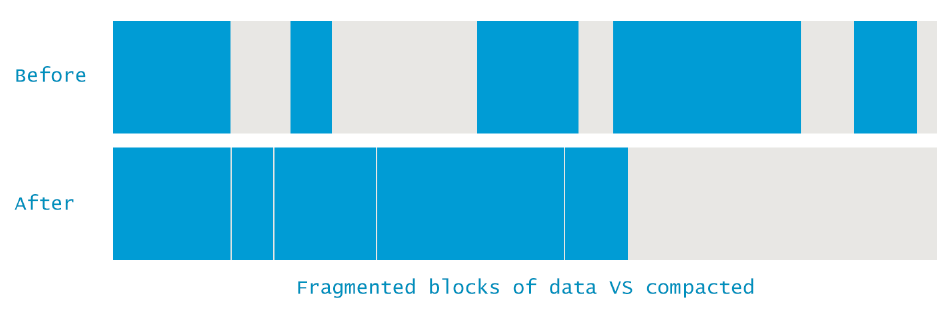
碎片与紧缩
当 Sweeping 发生时,JVM需要确保的是unreachable 对象所占据的空间可以被再次使用。这个(最终一定)会产生内存碎片(类似于磁盘碎片),这样会导致两个问题:
- 写操作会更耗时,因为找到下一个有足够空间的空闲块不再是一个低消耗操作
- 当创建一个新对象时,JVM会在连续的内存块上分配内存。所以如果碎片的问题上升到没有单独、空闲、并足够的空间以满足新创建的对象时,会报一个allocation error
为了避免这些问题,JVM会去确保碎片问题不会失控。所以,除了做Marking and Sweeping,在垃圾回收时,也会有一个“memory defrag“的工作。这个进程重新分配所有reachable 对象,将它们相邻排列,清除掉(或是减少)内存碎片。下面是一个示意图:
世代假说
正如之前提到过的,在做垃圾回收时,会牵涉到完全停止应用。同时,可以明显确认的是:对象越多,回收垃圾的耗时越长。那我们是否可以只对某些小的内存区域做操作?在研究人员对此做进一步研究后,可以发现:在应用内部,大部分内存分配发生在以下两种场景:
- 大部分对象很快变成unused
- 对象不长期存活
这个发现促成了 Weak Generational Hypothesis。根据这个假设,VM 里的内存被分成两部分,分别称为Young Generation和Old Generation,后者有时也被称为 Tenured(终身的)。

这种分离的、独立的可清理区域,使得大量不同的算法可以对GC做很多performance上的提升。当然,这并不是说,这种方式完全没有问题。例如,不同generations的对象可能事实上也是有相互的引用,这样在做垃圾回收时,它们也会被认为是GC roots。
需要着重注意的是,世代假说可能实际上并不适用一些应用。因为GC的算法是对“die young(早逝)”或“有可能一直存在”的对象做优化,但JVM的行为对于(被预期为)“中期”长度生命的对象是不够优化的。
内存池
下面是在堆内存里对内存池的划分,可能大家对此已经比较熟悉了。而对于GC如何在不同的内存池中做回收,可能比较陌生。需要注意的是,不同的GC算法可能在实现的层面稍有差别,但是从概念层面上,基本是一致的。
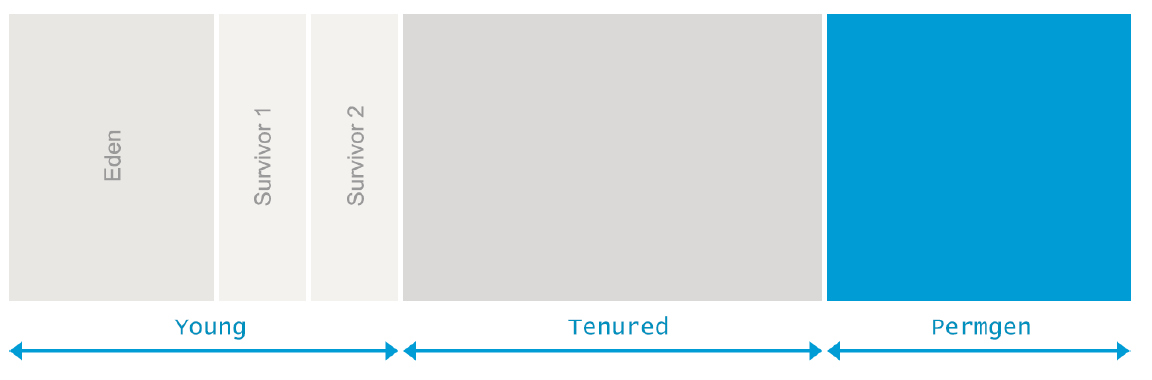
Eden(伊甸园)
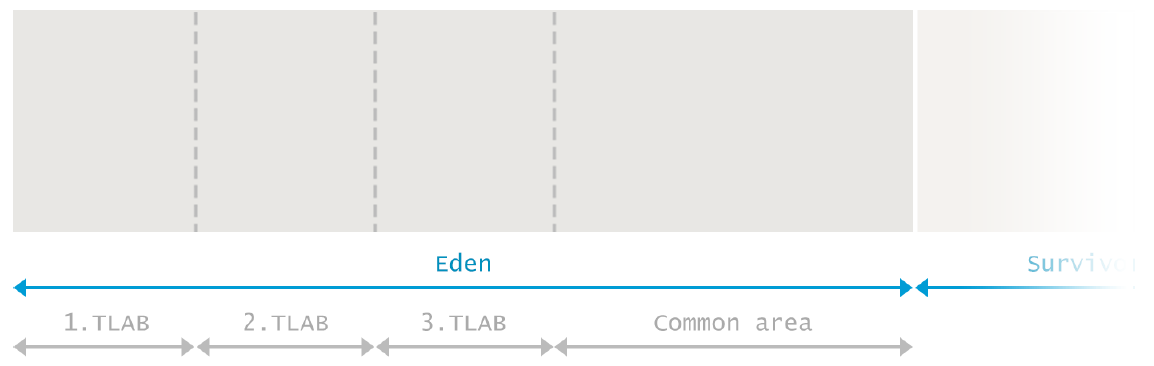
在对象被创建时,会从Eden这个内存区域里分配内存。由于一般会有多个线程用于同时创建大量对象,Eden空间会被进一步划分为一个或多个 Thread Local Allocation Buffer(TLAB)(线程本地分配缓冲区)。这些缓存允许JVM在一个线程在它对应的TLAB中直接分配能够分配的最多的对象,避免了与其他线程同步的消耗。
当在一个TLAB中无法完成分配动作时(一般来说是由于里面没有足够的空间),分配的动作会移动到一个共享的Eden空间。如果那里也没有足够的空间,则在Young Generation里的一个垃圾回收进程会被触发并释放出更多的空间。如果垃圾回收也无法在Eden里释放足够的空间,则对象会被分配到Old Generation。
当Eden 正在被回收时,GC会从GC roots遍历所有可达的对象,并将它们标注为存活(alive)。我们之前提到过,对象可能存在跨generation的引用,所以一个直接的方法是:检查所有从其他generation指向Eden的引用。但是这个可能会直接影响了之前我们提到的世代假说(原本已将它们分为两部分,现在这两部分却有了联系)。
JVM里对此做了一个优化,叫做:card-marking(卡片标记)。简单的说,就是对于那些有被Old Generation 引用的、存在于Eden中的“脏”对象,JVM仅仅是对它做一个大致的、模糊的位置标记。
在标记阶段完成后,所有在Eden中存活的对象会被复制到其中一个Survivor 空间。整个Eden现在会被认为是空的,并且它的空间可以被重新用于分配其他更多的对象。这个方法称为“Mark and Copy”(标记并复制):活跃的对象被标记,然后被复制到(而不是移动)一个survivor 空间。
Survivor Space(幸存者空间)
邻接Eden空间的是两个Survivor空间,被称为from和to。需要注意的是,这两个Survivor空间中的其中一个一定是一直是空的。
空的Survivor 空间会在Young Generation被回收后开始往里面放入内容。所有从整个Young Generation(包括Eden 空间以及non-empty的“from”Survivor空间)存活的对象会被复制到“to”Survivor空间。在这个过程完成后,“to”Survivor现在会存放对象,而“from”Survivor空间没有对象,它们的角色也会在这时做转换。
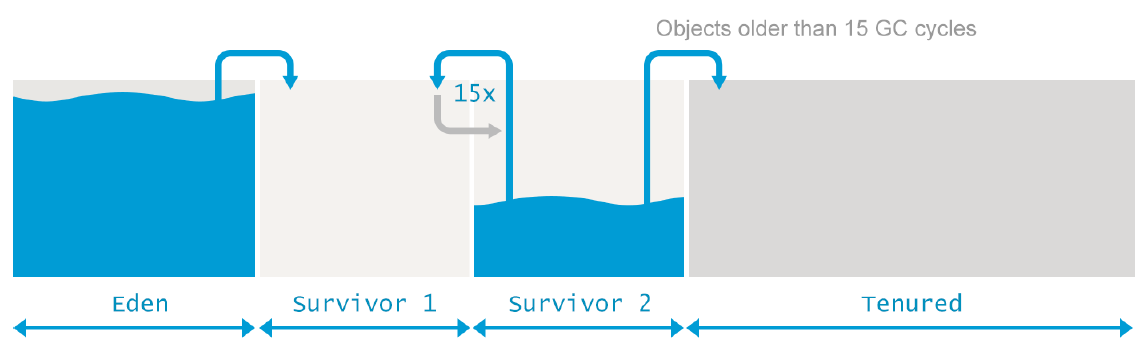
这个在两个Survivor空间中复制存活对象的过程会重复多次,直到一些对象被认为经历的时间足够久并“old enough”。需要注意的是,根据世代假说,存活时间较长的对象被预期是会继续被长时间使用的。
这些长时间存活的对象因此可以被“提升”到Old Generation。当这个过程发生时,对象并不是从一个survivor空间移动到另一survivor空间,而是被移动到了Old Generation空间。这些对象会在Old Generation空间里长久存在,直到它们unreachable。
为了判断一个对象是否是“old enough”并被移动到Old 空间,GC会跟踪对象在回收后仍然存活的次数。在每个对象的generation在GC中完成后,这些依旧存活的对象的年纪会增加。当它们的年纪超过了一个特定的“年纪阈值”后,会被移动到Old 空间。
而实际的“年纪阈值”是JVM动态调整的,但是可以通过指定 -XX:+MaxTenuringThreshold 设置一个上限值。若将此参数设置为0,则会导致移动到Old 空间立即生效(也就是说,不会在Survivor空间之间做复制)。默认情况下,这个阈值在主流的JVM中是15轮GC。这也是HotSpot中的最大值。
Promotion(从young 空间移动到old空间)也可以在对象经历的GC轮数达到阈值前发生,如果在Young Generation中的Survivor空间不足以存下所有存活的对象的话。
Old Generation(老生代)
Old Generation内存空间的实现更为复杂。Old Generation的空间一般会比Young Generation大得多,并且存放了那些更少可能被回收的对象。
在Old Generation中发生的GC频率要少于Young Generation。并且,由于大部分对象被认为是在Old Generation中应该存活的,所以在这里不会有Mark and Copy(标记并复制)的过程发生。取而代之的是,对象会被四处移动,以最小化内存碎片。Old 空间的清理算法一般基于不同的基础。基本上,会经历以下几个步骤:
- 标记所有可达对象(从GC roots可达的对象),设置标记位
- 删除所有不可达对象
- 复制存活的对象,并从Old 空间的起始,将它们紧凑、相邻地排在一起
从上面的步骤可以看到,在Old Generation的GC会将对象紧凑的排列,以避免过度的内存碎片。
PermGen(永生代)
在Java 8 以前,会存在一个特殊的空间名为“Permanent Generation”(永久代)。这个地方会存放一些metadata(例如classes)。同时,一些额外的东西,例如Internalized strings(常量字符串)也会存在PermGen。
但是它在过去常常会对Java 开发者产生大量的问题,因为这个区域到底一共需要多少空间是很难被预测的。而预测失败的结果往往会导致 java.lang.OutOfMemoryError:Permgen space 的报错。
除非真正导致这个OutOfMemory报错的原因是一个内存泄漏,否则修复这个问题的方法一般是增加PermGen的空间分配,例如下面的选项指定了最高允许的PermGen内存空间为256MB:
java -XX:MaxPermSize=256m com.company.MyApplication
Metaspace(源空间)
预测metadata所需的空间是一个复杂且不方便的工作,所以Permanent Generation在Java 8 被移除了,并由Metaspace所取代。 从此,大部分杂七杂八的内容被移动到了常规的Java heap中。
但是,类的定义(class definitions),现在被加载到了名为Metaspace的地方。它存在于本地内存并且不干扰常规堆中的对象。默认情况下,Metaspace的空间仅仅由Java进程所拥有的本地可用内存所限制。这种方式解决了在新增加一个或多个类到应用时返回 java.lang.OutOfMemoryError:Permgen space 的问题。
需要注意的是,拥有这种看似无限制的内存空间并不是没有开销的,如果让Metaspace无控制的增长的话,则会引入大量的swapping操作并甚至可能触发本地内存分配报错。
考虑到仍旧需要对此场景做控制,我们可以限制Metaspace的增长,例如,限制它的大小为256MB:
java -XX:MaxMetaspaceSize=256m com.company.MyApplication
References:
https://plumbr.io/java-garbage-collection-handbook
JVM垃圾回收(一)- 什么是垃圾回收的更多相关文章
- JVM中GC浅解:垃圾回收的了解
1.为什么要有GC 没有GC的世界,我们需要手动进行内存管理,但是内存管理是纯技术活,又容易出错.但是我们写码的目的是为了解决业务问题,所以可以把这种纯技术活自动化,当然自动化也是有代价的. 2.垃圾 ...
- java虚拟机学习-JVM调优总结-新一代的垃圾回收算法(11)
垃圾回收的瓶颈 传统分代垃圾回收方式,已经在一定程度上把垃圾回收给应用带来的负担降到了最小,把应用的吞吐量推到了一个极限.但是他无法解决的一个问题,就是Full GC所带来的应用暂停.在一些对实时性要 ...
- java虚拟机学习-JVM调优总结-分代垃圾回收详述(9)
为什么要分代 分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的.因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率. 在Java程序运行的过程中,会产生大量的对象, ...
- JVM的内存区域划分以及垃圾回收机制详解
在我们写Java代码时,大部分情况下是不用关心你New的对象是否被释放掉,或者什么时候被释放掉.因为JVM中有垃圾自动回收机制.在之前的博客中我们聊过Objective-C中的MRC(手动引用计数)以 ...
- JVM 调优系列之图解垃圾回收
摘要: jvm必知系列,总结一些常见jvm回收机制,方便查阅 对于调优之前,我们必须要了解其运行原理,java 的垃圾收集Garbage Collection 通常被称为"GC", ...
- 03 JVM 从入门到实战 | 简述垃圾回收算法
引言 之前我们学习了 JVM 基本介绍 以及 什么样的对象需要被 GC ,今天就来学习一下 JVM 在判断出一个对象需要被 GC 会采用何种方式进行 GC.在学习 JVM 如何进行垃圾回收方法时,发现 ...
- JVM总括二-垃圾回收:GC Roots、回收算法、回收器
JVM总括二-垃圾回收:GC Roots.回收算法.回收器 目录:JVM总括:目录 一.判断对象是否存活 为了判断对象是否存活引入GC Roots,如果一个对象与GC Roots没有直接或间接的引用关 ...
- JVM运行时数据区和垃圾回收机制
最近参考各种资料,尤其是<深入理解Java虚拟机 JVM高级特性和最佳实践>,大牛之作.把最近学习的Java虚拟机组成和垃圾回收机制总结一下. 你不会的都是新知识,学无止境,每天进步一点点 ...
- JVM 性能优化, Part 4: C4 垃圾回收
ImportNew注:本文是JVM性能优化 系列-第4篇.前3篇文章请参考文章结尾处的JVM优化系列文章.作为Eva Andreasson的JVM性能优化系列的第4篇,本文将对C4垃圾回收器进行介绍. ...
- JVM性能优化, Part 3 垃圾回收
ImportNew注:本文是JVM性能优化 系列-第3篇-<JVM性能优化, Part 3 —— 垃圾回收> 第一篇 <JVM性能优化, Part 1 ―― JVM简介 > 第 ...
随机推荐
- 实现Linux下的ls和ls-l
ls的C语言代码实现 #include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #includ ...
- 用java代码解决excel打开csv文件乱码问题
Java 读取csv文件后,再保存到磁盘上,然后直接用Excel打开,你会发现里面都是乱码. 贴上代码: public class Test { public static void main(S ...
- dokuwiki 安装配置
dokuwiki如果在用户注册的时候,发生"发送密码邮件时产生错误.请联系管理员!",那么需要配置sendmail. 在linux平台下,参考这个帖子https://www.dok ...
- IDEA为了使用方便,需要改的几条配置
自动编译开关 在Eclipse中自动编译开关是开着的,如下所示那么,在IDEA中,务必要手动将其打开,非常重要! 忽略大小写开关 IDEA默认是匹配大小写,此开关如果未关.你输入字符一定要符合大小写. ...
- 更新node的版本,node没有安装到c盘,安装到了D盘
百度的很久,只有这一个实用,记录一下 https://www.cnblogs.com/xinjie-just/p/7061619.html
- 甘特图 (Gantt )的优缺点
时间管理 - 甘特图 (Gantt ) 优点:甘特图直观.简单.容易制作,便于理解,能很清晰地标识出直到每一项任务的起始与结束时间,一般适用比较简单的小型项目,可用于WBS的任何层次.进度控制.资源优 ...
- 《Java程序设计》 第四周学习总结
学号 20175313 <Java程序设计>第四周学习总结 教材学习内容总结 第五章主要内容 了解子类的继承性 子类和父类在同一包中的继承性(除private外其余都继承) 子类和父类不在 ...
- java框架之Hibernate(3)-一对多和多对多关系操作
一对多 例:一个班级可以有多个学生,而一个学生只能属于一个班级. 模型 package com.zze.bean; import java.util.HashSet; import java.util ...
- postman接口自动化,环境变量的用法详解(附postman常用的方法)
在实现接口自动测试的时候,会经常遇到接口参数依赖的问题,例如调取登录接口的时候,需要先获取登录的key值,而每次请求返回的key值又是不一样的,那么这种情况下,要实现接口的自动化,就要用到postma ...
- 自增ID算法snowflake - C#版
急景流年,铜壶滴漏,时光缱绻如画,岁月如诗如歌.转载一篇博客来慰藉,易逝的韶华. 使用UUID或者GUID产生的ID没有规则 Snowflake算法是Twitter的工程师为实现递增而不重复的ID实现 ...