学习MongoDB 七: MongoDB索引(索引基本操作)(一)
一、简介
在MongoDB建立索引能提高查询效率,只需要扫描索引只存储的这个集合的一小部分,并只把这小部分加载到内存中,效率大大的提高,如果没有建立索引,在查询时,MongoDB必须执行全表扫描,在数据量大时,效率差别就很明显,对于包括一个没有索引的排序操作的查询,服务器必须在返回任何结果之前将所有的文档加载到内存中来进行排序。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。索引项的排序支持高效的相等匹配和基于范围的查询操作。
从mongoDB 3.0开始ensureIndex被废弃,使用 createIndex创建索引。
创建索引的语法:
db.collection.createIndex(keys,options)|
参数 |
类型 |
描述 |
|
keys |
document |
一个包含该字段的字段和值对的文档,该文档的索引键和该值描述该字段的索引类型。对于某个领域的上升索引,指定一个值为1;对于下降的索引,指定一个值为1。 MongoDB支持几种不同的索引类型,包括文本,空间,和哈希索引。查看更多信息的索引类型。 |
|
options |
document |
在创建索引的时的限制条件 |
二、 索引的基本操作
我们先插入10w条记录
- for(var i=0;i<1000000;i++){
- . db. orders.insert({
- "onumber" : i,
- "date" : "2015-07-02",
- "cname" : "zcy"+i,
- "items" :[ {
- "ino" : i,
- "quantity" : i,
- "price" : 4.0
- },{
- "ino" : i+1,
- "quantity" : i+1,
- "price" : 6.0
- }
- ]
- })
- }
1. 默认索引
存储在MongoDB集合中的每个文档(document)都有一个默认的主键“_id“,如果我们在添加新的文档时,没有指定“_id“值时,MongoDB会创建一个ObjectId值,并创建会自动创建一个索引在“_id“键上,默认索引的名称是”_id_“,并无法删除,如下面的命令查看:
>db.orders.getIndexes()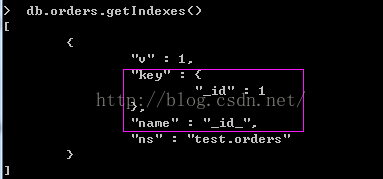
2. 查看索引信息
返回一个数组,该数组保存标识和描述集合上现有索引的文档列表,可以查看我们是否有对某个集合创建索引,并创建哪些索引,方便我们管理。
语法:
>db.collection.getIndexes()3. 创建单列索引
我们对文档单个字段创建索引或者对内嵌文档的单个字段创建索引
语法:
db.collection.createIndex({field:boolean} })boolean:对于某个领域的上升索引,指定一个值为1;对于下降的索引,指定一个值为1。
(1)创建
例子:
>db.orders.createIndex({cname:1}) 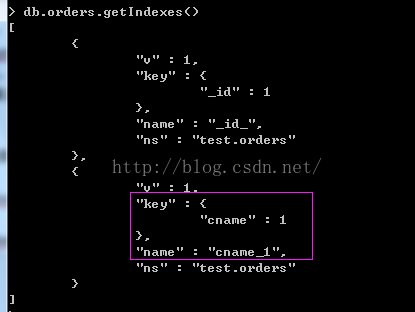
我们对orders集合创建了cname索引,默认的索引名称是”cname_1“
(2)根据条件查询文档,并查看查询效率怎么样
例子:
> db.orders.find({"cname":"zcy100000"})我们查询orders 集合根据条件cname为zcy100000的文档
我们测试有建索引和没建索引在1000000条文档执行查询的效率怎么样,我们这边先使用explain()函数,下一篇我们介绍
我们这边先介绍几个参数
1) n:当前查询返回的文档数量。
2)millis:当前查询所需时间,毫秒数。
3)indexBounds:当前查询具体使用的索引
例子:
> db.orders.find({"cname":"zcy100000"}).explain()1)没建索引时,查询条件cname为zcy100000的文档

返回一个记录,花费1006毫秒,没使用到索引
2)有建索引,查询条件cname为zcy100000的文档
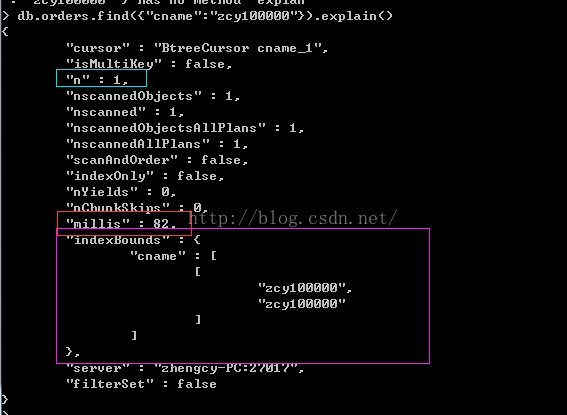
返回一个记录,花费82毫秒,有使用到cname索引
我们结果是相差很大的,有建索引字段,查询效率比较高,在大数据时,差别更明显。
(3)查询和排序组合使用
我们查询集合cname大于zcy100的文档并对onumber进行降序排序
例子:
>db.orders.find({"cname":{$gt:"zcy1000"}}).sort({"onumber":1}).explain()
执行出现错误:
"$err" : "Runner error:Overflow sort stage buffered data usage of 33554456 bytes exceeds internal limit of 33554432 bytes",
我们的内存只有33554432字节,对于包括一个没有索引的排序操作的查询,服务器必须在返回任何结果之前将所有的文档加载到内存中来进行排序。
我们对onumber创建索引
> db.orders.createIndex({onumber:-1})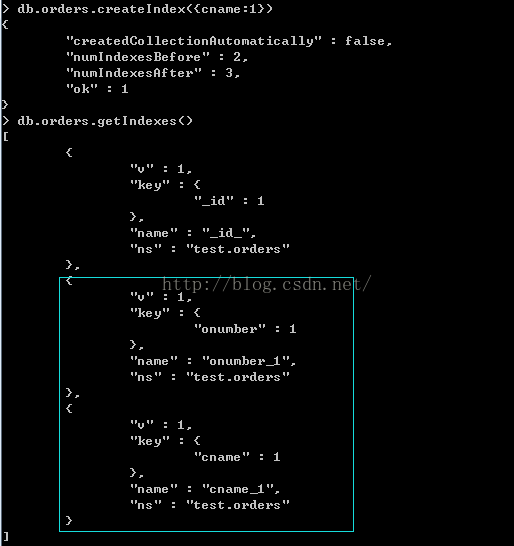

这次我们在执行时,可以正常执行,已经减少了内存的缓存的数据
4. 创建组合索引
我们可以同时对多个键创建组合索引
语法:
db.collection.createIndex({field1:boolean, field2:boolean } })说明:
db.collection.createIndex({a:1,b:1,c:1 } })
我们对a、b、c进组合创建索引,支持查询时会用到索引的几种:
1) a
2) a,b
3) a,b,c
这三中的查询条件,会使用到索引
(1) 创建组合索引
我们同时对onumber和cname进行组合索引
例子:
>db.orders.createIndex({cname:1,onumber:-1})索引存储在一个易于遍历读取的数据集合中,存储的数据
{_id:..,"onumber" : 2, "date" : "2015-07-02", "cname" : "zcy1"})
{_id:..,"onumber" : 1, "date" : "2015-07-02", "cname" : "zcy1"})
{_id:..,"onumber" : 1, "date" : "2015-07-02", "cname" : "zcy2"})
(2) 查询
1)我们对cname和onumber作为查询条件时
例子:
>db.orders.find({"cname":{$gt:"zcy1000"},"onumber":2000}).explain()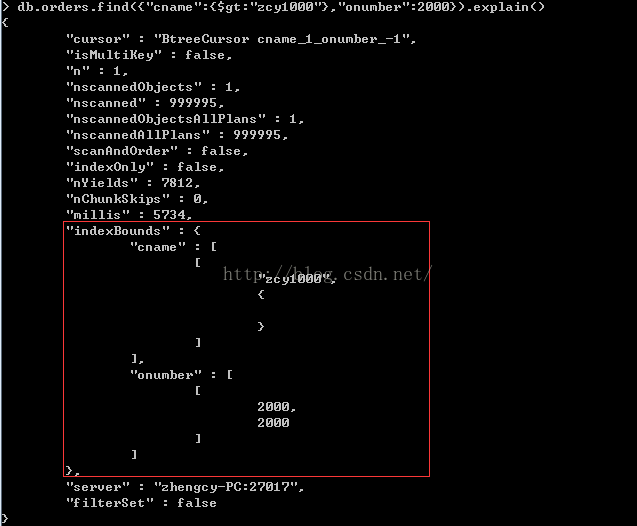
我们查询条件cname大于zcy1000并且onumber等于2000的数据,我们用explain()查询索引使用情况
2)我们只用两个索引其中一个作为查询时
第一种情况:我们条件只使用"cname":{$gt:"zcy1000"}作为查询条件
例子:
>db.orders.find({"cname":{$gt:"zcy1000"}}).explain()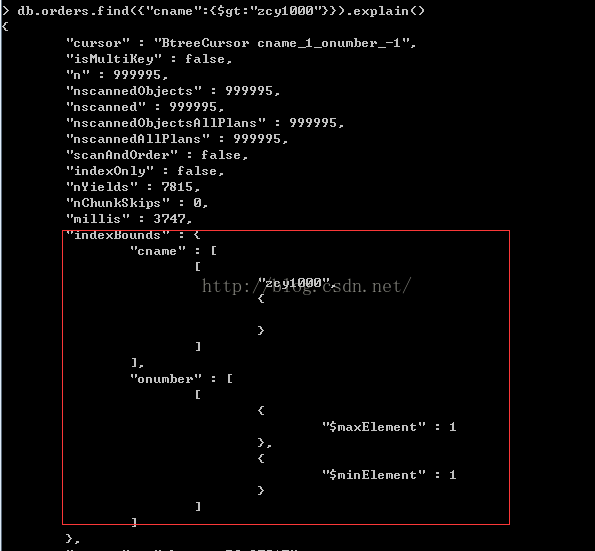
会使用到索引,符合我们前面介绍的我们对a、b、c进组合创建索引,支持查询时会用到索引的第一种。
第二种情况:我们条件只使用"onumber":2000作为查询条件
例子:
> db.orders.find({"onumber":2000}).explain()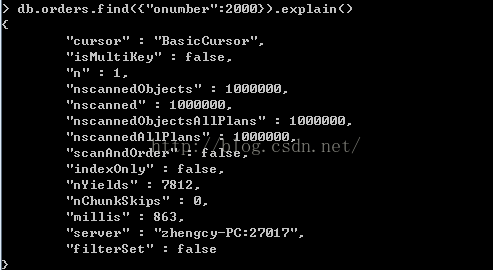
不会使用到索引,不符合我们前面介绍的我们对a、b、c进组合创建索引,支持查询时会用到几种。
(3)查询和排序组合使用
我们查询集合cname大于zcy100的文档并对onumber进行降序排序
例子:
>db.orders.find({"cname":{$gt:"zcy1000"}}).sort({"onumber":1}).explain()执行出现错误:
"$err" : "Runner error:Overflow sort stage buffered data usage of 33554456 bytes exceeds internal limit of 33554432 bytes",
sort时,不会使用到索引,不符合我们前面介绍的我们对a、b、c进组合创建索引,支持查询时会用到几种。
总结:我们在使用组合索引时,查询时会用到组合索引的前端的几种组合。
我们对a、b、c进组合创建索引,支持查询时会用到索引的几种:
1) a
2) a,b
3) a,b,c
5. 内嵌文档的索引
我们对内嵌文档创建索引时,跟基本文档创建索引一样
语法:
db.collection.createIndex({field:boolean} })field说明:以“.“来指明内嵌文档的路径
(1) 单列的内嵌文档的索引创建
例子:
>db.orders.createIndex({"items.info":1})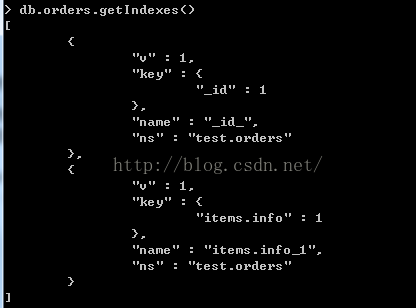
我们orders集合下的内嵌items集合的info字段创建索引
我们以items.info字段作为查询条件,并使用索引的情况
例子:
>db.orders.find({"items.info":{$lt:100}}).explain()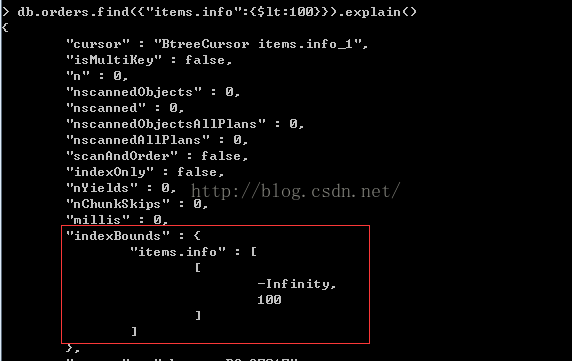
我们查询items.info小于100的数据
(2) 组合的内嵌文档的索引的创建
我们对内嵌文档创建组合索引时,跟基本文档创建组合索引一样
语法:
>db.collection.createIndex({field1:boolean, field2:boolean } })例子:
>db.orders.createIndex({"items.info":1, "items. quantity":-1})6. 删除索引
我们对已经创建的索引进行删除,可以针对具体的集合中索引进行删除,也可以对所有的集合中的所有索引删除
(1)具体索引名称删除索引
语法:
db.collection.dropIndex(index)删除具体的索引,根据索引名称删除,如果不知道索引的名称,可以通过db.collection.getIndexes()查看索引名称
例子:
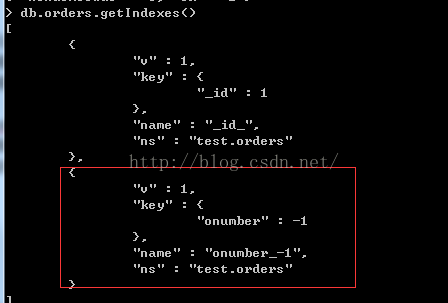
> db.orders.dropIndex("cname_1")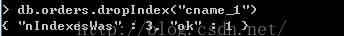
我们删除cname字段的索引,现在只剩下onumber字段索引
(2)删除集合中所有索引
语法:
db.collection.dropIndexes()例子:
> db.orders.dropIndexes()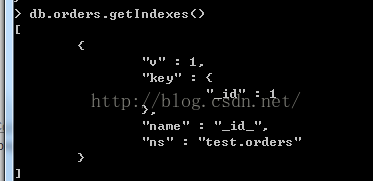
我们对集合中的索引都删除,我们删除cname字段的索引和onumber字段索引,现在只剩默认的_id字段索引,索引我们在使用时,要谨慎,以免把集合中的索引都删除。
(3)对dropIndexes方法,我们还有一种用法,可以指定集合的具体索引的删除
例子:
> db.runCommand({"dropIndexes":"orders","index":"cname_1"})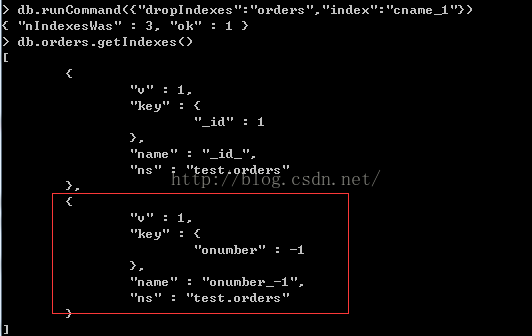
我们删除cname字段的索引,现在只剩下onumber字段索引
总结:
在MongoDB建立索引能提高查询效率,但在MongoDB新增、修改效率上比较慢
学习MongoDB 七: MongoDB索引(索引基本操作)(一)的更多相关文章
- InnoDB学习(七)之索引结构
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息.可以将数据库索引和书的目录进行类比,通过书的目录我们可以快速查找到章节位置,如果没有目录就只能一页页翻书查找 ...
- MongoDB (七) MongoDB 数据类型
MongoDB支持许多数据类型的列表下面给出: String : 这是最常用的数据类型来存储数据.在MongoDB中的字符串必须是有效的UTF-8. Integer : 这种类型是用来存储一个数值.整 ...
- MongoDB学习笔记(五、MongoDB存储引擎与索引)
目录: mongoDB存储引擎 mongoDB索引 索引的属性 MongoDB查询优化 mongoDB存储引擎: 目前mongoDB的存储引擎分为三种: 1.WiredTiger存储引擎: a.Con ...
- 【转载】8天学通MongoDB——第四天 索引操作
这些天项目改版,时间比较紧,博客也就没跟得上,还望大家见谅. 好,今天分享下mongodb中关于索引的基本操作,我们日常做开发都避免不了要对程序进行性能优化,而程序的操作无非就是CURD,通常我们 又 ...
- 【mongoDB中级篇②】索引与expain
索引的操作 数据库百分之八十的工作基本上都是查询,而索引能帮我们更快的查询到想要的数据.但是其降低了数据的写入速度,所以要权衡常用的查询字段,不必在太多字段上建立索引. 在mongoDB中默认是用bt ...
- 8天学通MongoDB——第四天 索引操作
这些天项目改版,时间比较紧,博客也就没跟得上,还望大家见谅. 好,今天分享下mongodb中关于索引的基本操作,我们日常做开发都避免不了要对程序进行性能优化,而程序的操作无非就是CURD,通常我们 又 ...
- MongoDB系列四(索引).
一.索引简介 再来老生常谈一番,什么是索引呢?数据库索引与书籍的索引类似.有了索引就不需要翻整本书,数据库可以直接在索引中查找,在索引中找到条目以后,就可以直接跳转到目标文档的位置,这能使查找速度提高 ...
- mongoDB常见的查询索引(三)
1. _id索引 _id索引是绝大多数集合默认建立的索引 对于每个插入的数据,MongoDB会自动生成一条唯一的_id字段. 1 2 3 4 5 6 7 8 9 10 11 12 13 ...
- MongoDB优化,建立索引实例及索引机制原理讲解
MongoDB优化,建立索引实例及索引机制原理讲解 为什么需要索引? 当你抱怨MongoDB集合查询效率低的时候,可能你就需要考虑使用索引了,为了方便后续介绍,先科普下MongoDB里的索引机制(同样 ...
随机推荐
- Ubuntu16.04怎样安装Python3.6
Ubuntu16.04默认安装了Python2.7和3.5 请注意,系统自带的python千万不能卸载! 输入命令python
- 查看camera设备-linux
前言 本文介绍如何在linux平台查看是否有camera外设. 操作过程 1.打开shell,输入以下命令: ls /dev/video* 即可查看是否有camera外设: 2.如果确实连接了came ...
- WinRAR的自解压模式 - imsoft.cnblogs
一个 SFX (SelF-eXtracting)自解压文件是压缩文件的一种,它结合了可执行文件模块,一种用以运行从压缩文件解压文件的模块.这样的压缩文件不需要外部程序来解压自解压文件的内容,它自己便可 ...
- 大家一起做训练 第一场 B Tournament
题目来源:CodeForce #27 B 有n个人比赛,两两之间都有一场比赛,一共 n * (n - 1) / 2 场比赛.每场比赛的记录方式是 a b,表示在a和b的比赛中,a胜出,b失败. 经过研 ...
- es6语法快速上手(转载)
一.相关背景介绍 我们现在大多数人用的语法javascript 其实版本是ecmscript5,也是就es5.这个版本己经很多年了,且完美被各大浏览器所支持.所以很多学js的朋友可以一直分不清楚es5 ...
- 关于springmvc 返回json数据null字段的显示问题-转https://blog.csdn.net/qq_23911069/article/details/62063450
最近做项目(ssm框架)的时候,发现从后台返回的json(fastjson)数据对应不上实体类,从数据库查询的数据,如果对应的实体类的字段没有信息的话,json数据里面就不显示,这不是我想要的结果,准 ...
- HDMI接口基本信息
一.HDMI基本概念1.HDMI标准的发展历史: 2002年12月9日,HDMI1.0版正式发布,标志着HDMI技术正式登上历史舞台. 2004年1月,HDMI1.1版发布. 2005年8月,HDMI ...
- MySQL Disk--SSD 特性
======================================================================= SSD 特性 .随机读能力非常好,连续读性能一般,但比普 ...
- java中Thread类分析
创建线程的方式有三种,一是创建Thread实例,二是实现Runnable接口,三是实现Callable接口,Runnable接口和Callable接口的区别是一个无返回值,一个有返回值:不管是Runn ...
- HTMLCanvasElement.toBlob() 兼容性及使用
toBlob 兼容性: 在最新版chrome和firefox中能正常使用,在Safari中报错:没有这个函数 规避方法: 不使用toBlob,使用toDataURL()将file转成base64编码, ...