【cs229-Lecture5】生成学习算法:1)高斯判别分析(GDA);2)朴素贝叶斯(NB)
参考:
cs229讲义
机器学习(一):生成学习算法Generative Learning algorithms:http://www.cnblogs.com/zjgtan/archive/2013/06/08/3127490.html
首先,简单比较一下前几节课讲的判别学习算法(Discriminative Learning Algorithm)和本节课讲的生成学习算法(Generative Learning Algorithm)的区别。
eg:问题:Consider a classification problem in which we want to learn to distinguishbetween elephants (y = 1) and dogs (y = 0), based on some features of
an animal.
判别学习算法:(DLA通过建立输入空间X与输出标注{1, 0}间的映射关系学习得到p(y|x))
Given a training set, an algorithm like logistic regression or the perceptron algorithm (basically) tries to find a straight line—that is, a decision boundary—that separates the elephants and dogs. Then, to classify a new animal as either an elephant or a dog, it checks on which side of the decision boundary it falls, and makes its prediction accordingly.
生成学习算法:(GLA首先确定p(x|y)和p(y),由贝叶斯准则得到后验分布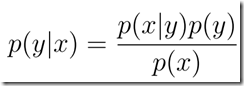 ,通过最大后验准则进行预测,
,通过最大后验准则进行预测,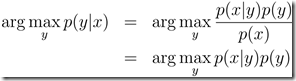 )
)
First, looking at elephants, we can build a model of what elephants look like. Then, looking at dogs, we can build a separate model of what dogs look like. Finally, to classify a new animal, we can match the new animal against the elephant model, and match it against the dog model, to see whether the new animal looks more like the elephants or more like the dogs we had seen in the training set.
(ps:先验概率 vs 后验概率
事情还没有发生,要求这件事情发生的可能性的大小,是
先验概率
.
事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小,是
后验概率
.
)
生成学习算法
首先,温习一下高斯分布的相关知识:
高斯分布 Gaussian distribution
高斯分布也就是正态分布; 数学期望为 , 方差为
, 方差为 的高斯分布通常记为
的高斯分布通常记为 .
.
标准正态分布 Standard normal distribution
标准正态分布是指数学期望为 , 方差为
, 方差为 的正态分布, 记为
的正态分布, 记为 . 对于数学期望为, 方差为的正态分布随机变量
. 对于数学期望为, 方差为的正态分布随机变量 , 通过下列线性变换
, 通过下列线性变换 可以得到服从标准正态分布的随机变量
可以得到服从标准正态分布的随机变量 .
.
二元正态分布 Bivariate normal distribution
二元正态分布[]是指两个服从正态分布的随机变量具有的联合概率分布. 二元正态分布的联合概率密度函数为

其中

 ,
,  ,
,  ,
,  ,
,  为概率分布的参数. 上述二元正态分布记为
为概率分布的参数. 上述二元正态分布记为 .
.
二元正态分布的特征函数为

多元正态分布 Multivariate normal distribution
多元正态分布是指多个服从正态分布的随机变量组成的随机向量具有的联合概率分布. 数学期望为 和协方差矩阵为
和协方差矩阵为 的
的 个随机变量
个随机变量 的多元正态分布
的多元正态分布 的联合概率密度函数为
的联合概率密度函数为

 服从多元正态分布可以记为
服从多元正态分布可以记为 .
.
如果, 并且 , 那么
, 那么 .
.
可以看到,多元正态分布与两个量相关:均值和协方差矩阵。因此,接下来,通过图像观察一下改变这两个量的值,所引起的变化。
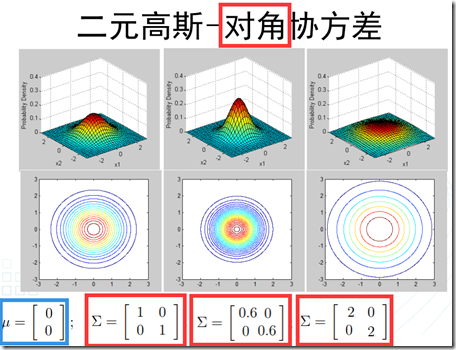
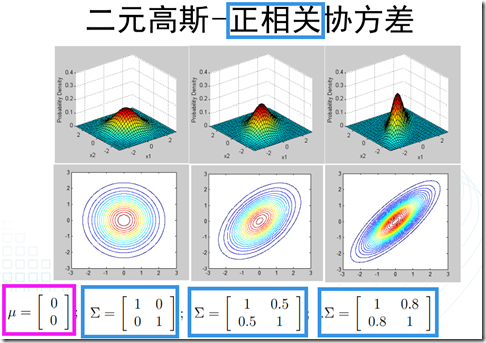
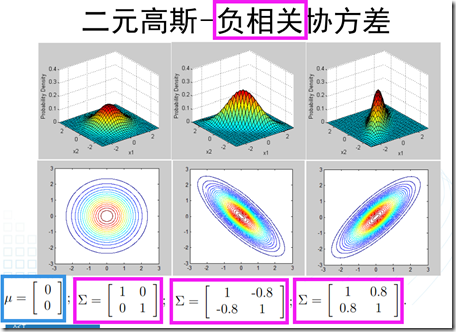
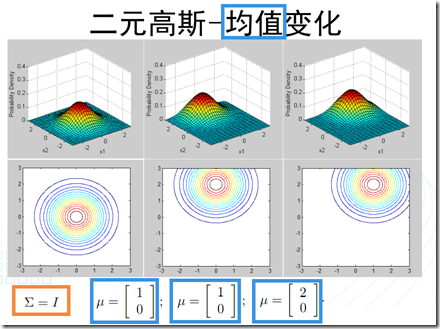
- 1、高斯判别分析(GDA,Gaussian Discriminant Analysis):
a、提出假设遵循正态分布:
In this model, we’ll assume that p(x|y) is distributed according to a multivariate normal distribution(多元正态分布).

b、分别对征服样本进行拟合,得出相应的模型
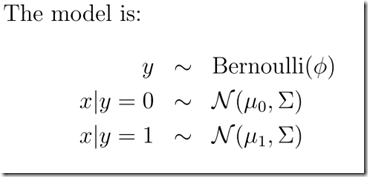


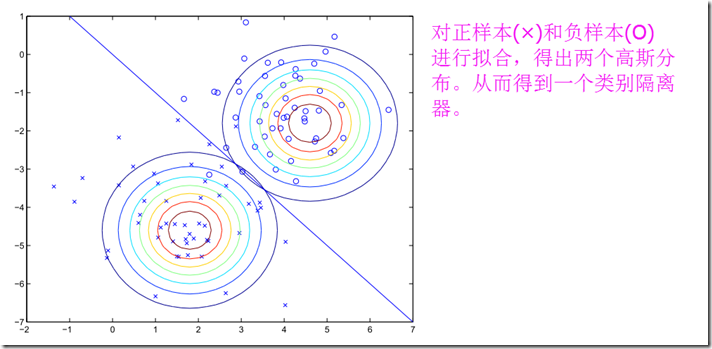
最后,比较一下GDA和Logistic回归
GDA——如果确实符合实际数据,则只需要少量的样本就可以得到较好的模型

Logistic Regression——Logistic回归模型有更好的鲁棒性

总结:
GDA makes stronger modeling assumptions, and is more data efficient (i.e., requires less training data to learn “well”) when the modeling assumptions are correct or at least approximately correct.
Logistic regression makes weaker assumptions, and is significantly more robust to deviations from modeling assumptions.
Specifically, when the data is indeed non-Gaussian, then in the limit of large datasets, logistic regression will almost always do better than GDA. For this reason, in practice logistic regression is used more often than GDA. (Some related considerations about discriminative vs. generative models also apply for the Naive Bayes algorithm that we discuss next, but the Naive Bayes algorithm is still considered a very good, and is certainly also a very popular, classification algorithm.)
2、朴素贝叶斯(NB,Naive Bayes):
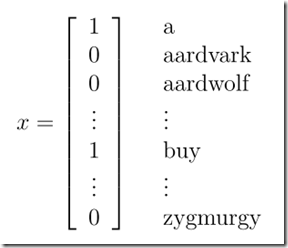
以文本分类为例,基于条件独立的假设。在实际语法上,有些单词之间是存在一定联系的,尽管如此,朴素贝叶斯还是表现出了非常好的性能。
因为独立,所以
得到联合似然函数Joint Likelihood:
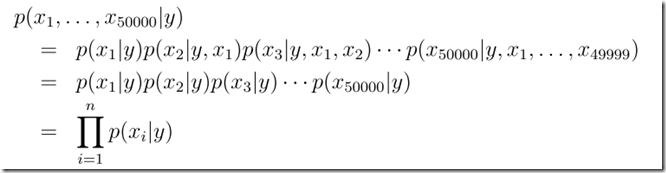
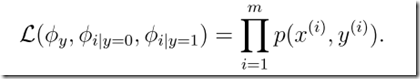

得到这些参数的估计值之后,给你一封新的邮件,可以根据贝叶斯公式,计算
(可以参阅我的另一篇实战随笔:http://www.cnblogs.com/XBWer/p/3840736.html)

Laplace smoothing(Laplace 平滑)
当邮件中遇到新词,(0/0)本质是输入样本特征空间维数的提升,旧的模型无法提供有效分类信息。
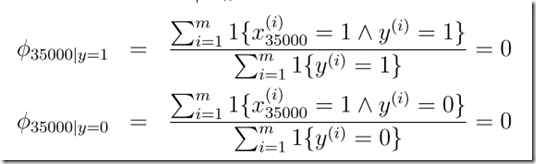
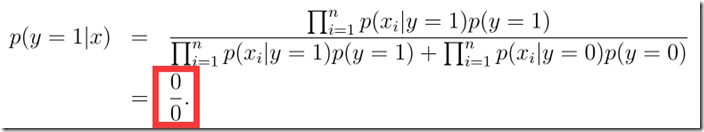
遇到这种情况时,可以进行平滑处理:(+1)
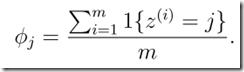 ==============>
==============>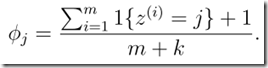
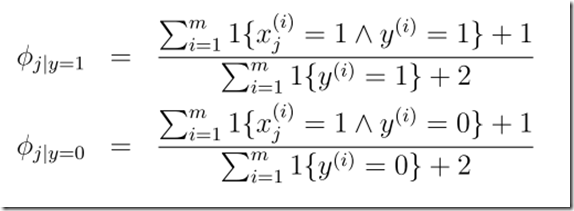
【cs229-Lecture5】生成学习算法:1)高斯判别分析(GDA);2)朴素贝叶斯(NB)的更多相关文章
- [置顶] 生成学习算法、高斯判别分析、朴素贝叶斯、Laplace平滑——斯坦福ML公开课笔记5
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9285001 该系列笔记1-5pdf下载请猛击这里. 本篇博客为斯坦福ML公开 ...
- Stanford大学机器学习公开课(五):生成学习算法、高斯判别、朴素贝叶斯
(一)生成学习算法 在线性回归和Logistic回归这种类型的学习算法中我们探讨的模型都是p(y|x;θ),即给定x的情况探讨y的条件概率分布.如二分类问题,不管是感知器算法还是逻辑回归算法,都是在解 ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- 机器学习理论基础学习3.5--- Linear classification 线性分类之朴素贝叶斯
一.什么是朴素贝叶斯? (1)思想:朴素贝叶斯假设 条件独立性假设:假设在给定label y的条件下,特征之间是独立的 最简单的概率图模型 解释: (2)重点注意:朴素贝叶斯 拉普拉斯平滑 ...
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
关于bayes的基础知识,请参考: 基于朴素贝叶斯分类器的文本聚类算法 (上) http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.h ...
- CS229 Lesson 5 生成学习算法
课程视频地址:http://open.163.com/special/opencourse/machinelearning.html 课程主页:http://cs229.stanford.edu/ 更 ...
- CS229笔记:生成学习算法
在线性回归.逻辑回归.softmax回归中,学习的结果是\(p(y|x;\theta)\),也就是给定\(x\)的条件下,\(y\)的条件概率分布,给定一个新的输入\(x\),我们求出不同输出的概率, ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- 3.朴素贝叶斯和KNN算法的推导和python实现
前面一个博客我们用Scikit-Learn实现了中文文本分类的全过程,这篇博客,着重分析项目最核心的部分分类算法:朴素贝叶斯算法以及KNN算法的基本原理和简单python实现. 3.1 贝叶斯公式的推 ...
- 朴素贝叶斯算法java实现(多项式模型)
网上有很多对朴素贝叶斯算法的说明的文章,在对算法实现前,参考了一下几篇文章: NLP系列(2)_用朴素贝叶斯进行文本分类(上) NLP系列(3)_用朴素贝叶斯进行文本分类(下) 带你搞懂朴素贝叶斯分类 ...
随机推荐
- 错误 未能找到类型或命名空间名称"xxxxxx"的真正原因
今天又被这问题撞上了,结果神奇般的解决了 谷歌了很久都没有找到真正有用的解决方案,所以在这儿写下,让更多的人看到 最根本的原因其实就是引用的问题,引用错了,然后VS在这上面提示又不够智能,所以大家被坑 ...
- thinkphp中的AJAX返回ajaxReturn()
系统支持任何的AJAX类库,Action类提供了ajaxReturn方法用于AJAX调用后返回数据给客户端.并且支持JSON.XML和EVAL三种方式给客户端接受数据,通过配置DEFAULT_AJAX ...
- UITableViewCell : 横向
在自定义 UITableViewCell 的 layoutSubviews 方法中添加如下代码 - (void)layoutSubviews { [super layoutSubviews]; if ...
- bind带autocomplete时,最好是从新的tr复制
(function($) { //自动关联ItemNo $.fn.extend({ productitemlist: function(options) { return this.each(func ...
- C++ 著名程序库 概览
本文转载自: http://ace.acejoy.com/thread-3777-1-1.html 1.C++各大有名库的介绍--C++标准库 2.C++各大有名库的介绍--准标准库B ...
- 如何设置Jquery UI Menu 菜单为横向展示
Jquery UI Menu 默认是纵向展示的.Jquey UI Menu 设置API,http://api.jqueryui.com/menu/#option-position 修改对应的CSS可 ...
- 性能监控-TP理解
首先给出Google到的答案: The tp90 is a minimum time under which 90% of requests have been served. tp90 = top ...
- 杨涛老师MvcPager示例
杨涛老师插件地址:http://www.webdiyer.com/mvcpager 杨涛老师网站上示例写的很详细了,参考他的示例和帮助文档就可以运用的很好了,有经验的同学可以直接参考官方示例. 一.标 ...
- 使用jstl+el表达式遇到的几个问题
1.使用jstl访问Map<Integer,String>中的内容时总取不到? el表达式的一个bug,在解析数字的时候,会自动将数字转换成Long类型. 我的解决办法是,Map的key改 ...
- windows 环境内网超快同步 DFS
记录下: 在WINDOWS环境下,内网同步使用DFS可以超快实现文件同步,效果非常OK 纯粹记录下!