PostgreSQL分布式架构之——PL/Proxy
1. PL/Proxy的介绍
1.1 PL/Proxy概述
PL/Proxy是一款能在PostgreSQL数据库实现数据库水平拆分的软件;可以理解分布式架构(shared nothing);但是不是真正的分布式数据库软件;也是一款能在PostgreSQL数据库实现SQL语言复制(replication)
分布式架构图如下:
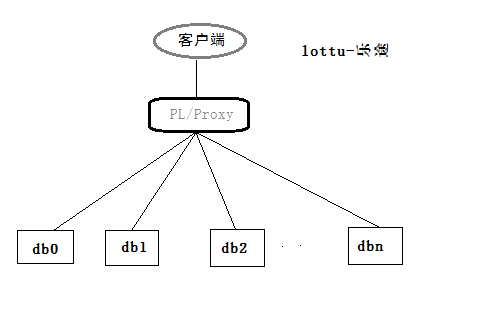
1.2 PL/Proxy集群配置
PL/Proxy既能配置成“CONNECT”模式又能配置成“CLUSTER”模式
- 在"CONNECT"模式中;PL/Proxy直接把请求路由(run on n)到指定的数据库。
- 在"CLUSTER"模式中;PL/Proxy可以支持数据水平分区,即shared nothing。也可以实现SQL语言复制(run on all)。
在配置“CLUSTER”模式有两种方式:
- 集群configuration API
- SQL/MED
1.3 PL/Proxy特性介绍
- PL/Proxy把需要对数据库SQL访问转换为对PostgreSQL函数调用。
- PL/Proxy后端数据库节点数必须是2的N次方。
2. PL/Proxy安装
2.1 编译安装
执行“source /home/postgres/.bashrc”加载环境变量;目的确保来自postgresql bin目录的pgconfig在您的路径中
tar -zxvf plproxy-2.7.tar.gz
cd plproxy-2.7
source /home/postgres/.bashrc
make
make install
2.2 创建PL/Proxy扩展
在这里我选“proxy”数据库作为路由代理数据库。
[postgres@Postgres201 ~]$ psql
psql (9.6.0)
Type "help" for help. postgres=# create database proxy;
CREATE DATABASE
postgres=# \c proxy
You are now connected to database "proxy" as user "postgres".
proxy=# create extension plproxy;
CREATE EXTENSION
proxy=# \dx
List of installed extensions
Name | Version | Schema | Description
---------+---------+------------+----------------------------------------------------------
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
plproxy | 2.7.0 | public | Database partitioning implemented as procedural language
(2 rows)
3. PL/Proxy的配置
本实验的配置环境如下:
| 主机名 | IP | 角色 | 数据库名 | 用户 |
|---|---|---|---|---|
| PostgreSQL201 | 192.168.1.201 | proxy node | proxy | lottu |
| PostgreSQL202 | 192.168.1.202 | data node | pl_db0 | lottu |
| PostgreSQL202 | 192.168.1.202 | data node | pl_db1 | lottu |
| PostgreSQL202 | 192.168.1.202 | data node | pl_db2 | lottu |
| PostgreSQL202 | 192.168.1.202 | data node | pl_db3 | lottu |
修改数据节点的pg_hba.conf
要确保PL/Proxy节点能访问所有数据库。
host all all 192.168.1.0/ trust
当然在线上数据库大家可以这样配置,例如:
host all lottu 192.168.1.201/ md5
采用SQL/MED方式配置集群【在PL/Proxy节点操作】
创建一个使用plproxy FDW的服务器来完成的。服务器的选项是PL/Proxy配置设置和集群分区列表。
[postgres@Postgres201 ~]$ psql proxy lottu
psql (9.6.0)
Type "help" for help. proxy=# \c
You are now connected to database "proxy" as user "lottu".
proxy=# CREATE SERVER cluster_srv1 FOREIGN DATA WRAPPER plproxy
proxy-# OPTIONS (
proxy(# connection_lifetime '',
proxy(# disable_binary '',
proxy(# p0 'dbname=pl_db0 host=192.168.1.202',
proxy(# p1 'dbname=pl_db1 host=192.168.1.202',
proxy(# p2 'dbname=pl_db2 host=192.168.1.202',
proxy(# p3 'dbname=pl_db3 host=192.168.1.202'
proxy(# );
CREATE SERVER
proxy=# \des
List of foreign servers
Name | Owner | Foreign-data wrapper
--------------+-------+----------------------
cluster_srv1 | lottu | plproxy
(1 row) proxy=# grant usage on FOREIGN server cluster_srv1 to lottu;
GRANT #创建用户映射
proxy=# create user mapping for lottu server cluster_srv1 options (user 'lottu');
CREATE USER MAPPING
proxy=# \deu
List of user mappings
Server | User name
--------------+-----------
cluster_srv1 | lottu
(1 row)
配置完成!在"CLUSTER"模式中;才需要上述配置;在"CONNECT"模式中是不需要的。
4. PL/Proxy测试
PL/Proxy把需要对数据库SQL访问转换为对PostgreSQL函数调用;这就需要使用者有良好的编程功底。
在数据节点创建测试样本表
create table users(userid int, name text);
4.1 "CLUSTER"模式测试
4.1.1 数据水平拆分测试
- 在每个数据节点创建insert函数接口
pl_db0=> CREATE OR REPLACE FUNCTION insert_user(i_id int, i_name text)
pl_db0-> RETURNS integer AS $$
pl_db0$> INSERT INTO users (userid, name) VALUES ($1,$2);
pl_db0$> SELECT 1;
pl_db0$> $$ LANGUAGE SQL;
CREATE FUNCTION
- 在PL/Proxy数据库创建同名的insert函数接口
proxy=# CREATE OR REPLACE FUNCTION insert_user(i_id int, i_name text)
proxy-# RETURNS integer AS $$
proxy$# CLUSTER 'cluster_srv1';
proxy$# RUN ON ANY;
proxy$# $$ LANGUAGE plproxy;
CREATE FUNCTION
为什么要同名的函数呢?若不是同名的话;需要在函数里面添加一个"TRAGET INSERT_USER";表明从数据节点调用函数"INSERT_USER"。
- 在PL/Proxy数据库创建读的函数get_user_name()
proxy=# CREATE OR REPLACE FUNCTION get_user_name()
RETURNS TABLE(userid int, name text) AS $$
CLUSTER 'cluster_srv1';
RUN ON ALL ;
SELECT userid,name FROM users;
$$ LANGUAGE plproxy;
CREATE FUNCTION
Ok;现在函数接口开发完成;我现在来调用函数插入10条记录
SELECT insert_user(1001, 'Sven');
SELECT insert_user(1002, 'Marko');
SELECT insert_user(1003, 'Steve');
SELECT insert_user(1004, 'lottu');
SELECT insert_user(1005, 'rax');
SELECT insert_user(1006, 'ak');
SELECT insert_user(1007, 'jack');
SELECT insert_user(1008, 'molica');
SELECT insert_user(1009, 'pg');
SELECT insert_user(1010, 'oracle');
由于函数执行的是"RUN ON ANY";表明插入数据是随机选取数据节点。我们看看每个数据节点的数据。
pl_db0=> select * from users;
userid | name
--------+--------
1005 | rax
1006 | ak
1008 | molica
1009 | pg
(4 rows) pl_db1=> select * from users;
userid | name
--------+-------
1002 | Marko
1004 | lottu
(2 rows) pl_db2=> select * from users;
userid | name
--------+--------
1007 | jack
1010 | oracle
(2 rows) pl_db3=> select * from users;
userid | name
--------+-------
1001 | Sven
1003 | Steve
(2 rows)
可以看出10条数据已经切分到每个数据节点。(10条取样太少,导致数据不均匀)。我们在proxy节点查询下。
proxy=# SELECT USERID,NAME FROM GET_USER_NAME();
userid | name
--------+--------
1005 | rax
1006 | ak
1008 | molica
1009 | pg
1002 | Marko
1004 | lottu
1007 | jack
1010 | oracle
1001 | Sven
1003 | Steve
(10 rows)
4.1.2数据复制(replication)测试
- 选择users表作为实验对象;我们先清理表users数据;在数据节点创建truncatet函数接口
pl_db0=> CREATE OR REPLACE FUNCTION trunc_user()
pl_db0-> RETURNS integer AS $$
pl_db0$> truncate table users;
pl_db0$> SELECT 1;
pl_db0$> $$ LANGUAGE SQL;
CREATE FUNCTION
- 在PL/Proxy数据库创建同名的truncate函数接口
proxy=# CREATE OR REPLACE FUNCTION trunc_user()
proxy-# RETURNS SETOF integer AS $$
proxy$# CLUSTER 'cluster_srv1';
proxy$# RUN ON ALL;
proxy$# $$ LANGUAGE plproxy;
CREATE FUNCTION
- 执行之后trunc_user();数据已经清理了。
proxy=# SELECT TRUNC_USER();
trunc_user
------------
1
1
1
1
(4 rows)
其实在这里我们已经验证数据复制(replication)测试。为了更好解释;我们选择insert函数接口来。
- 在PL/Proxy数据库创建函数接口 insert_user_2
proxy=# CREATE OR REPLACE FUNCTION insert_user_2(i_id int, i_name text)
proxy-# RETURNS SETOF integer AS $$
proxy$# CLUSTER 'cluster_srv1';
proxy$# RUN ON ALL;
proxy$# TARGET insert_user;
proxy$# $$ LANGUAGE plproxy;
CREATE FUNCTION
我们选择这几条语句
proxy=# SELECT insert_user_2(1004, 'lottu');
proxy=# SELECT insert_user_2(1005, 'rax');
proxy=# SELECT insert_user_2(1006, 'ak');
proxy=# SELECT insert_user_2(1007, 'jack');
- 我们看看每个数据节点的数据。
pl_db0=> select * from users;
userid | name
--------+-------
1004 | lottu
1005 | rax
1006 | ak
1007 | jack
(4 rows) pl_db1=> select * from users;
userid | name
--------+-------
1004 | lottu
1005 | rax
1006 | ak
1007 | jack
(4 rows) pl_db2=> select * from users;
userid | name
--------+-------
1004 | lottu
1005 | rax
1006 | ak
1007 | jack
(4 rows) pl_db3=> select * from users;
userid | name
--------+-------
1004 | lottu
1005 | rax
1006 | ak
1007 | jack
(4 rows)
每个节点的数据都是一样的。完成了数据复制(replication)测试。
- 我们在proxy节点查询下。只要在任意数据节点读取数据即可;我们先编辑函数。
proxy=# CREATE OR REPLACE FUNCTION get_user_name_2()
proxy-# RETURNS TABLE(userid int, name text) AS $$
proxy$# CLUSTER 'cluster_srv1';
proxy$# RUN ON ANY ;
proxy$# SELECT userid,name FROM users;
proxy$# $$ LANGUAGE plproxy;
CREATE FUNCTION
proxy=# SELECT USERID,NAME FROM GET_USER_NAME_2();
userid | name
--------+-------
1004 | lottu
1005 | rax
1006 | ak
1007 | jack
(4 rows)
4.2 "CONNECT"模式测试
使用"CONNECT"模式;PL/Proxy不需要上述的配置;直接使用即可。
proxy=# CREATE OR REPLACE FUNCTION get_user_name_3()
proxy-# RETURNS TABLE(userid int, name text) AS $$
proxy$# CONNECT 'dbname=pl_db0 host=192.168.1.202';
proxy$# CONNECT 'dbname=pl_db1 host=192.168.1.202';
proxy$# SELECT userid,name FROM users;
proxy$# $$ LANGUAGE plproxy;
ERROR: PL/Proxy function lottu.get_user_name_3(0): Compile error at line 3: Only one CONNECT statement allowed
proxy=# CREATE OR REPLACE FUNCTION get_user_name_3()
proxy-# RETURNS TABLE(userid int, name text) AS $$
proxy$# CONNECT 'dbname=pl_db0 host=192.168.1.202';
proxy$# SELECT userid,name FROM users;
proxy$# $$ LANGUAGE plproxy;
CREATE FUNCTION
proxy=# SELECT USERID,NAME FROM GET_USER_NAME_3();
userid | name
--------+-------
1004 | lottu
1005 | rax
1006 | ak
1007 | jack
(4 rows)
只允许一个“CONNECT statement”;用法很简单;作用很鸡肋。
5. 总结
PL/Proxy的语法本文差不多都涉及到了。至于通过“集群configuration API”方式配置集群,本文不讲解了;其实配置也很简单。
6. 参考文档
https://yq.aliyun.com/articles/59372?spm=a2c4e.11153940.blogcont59345.17.46039916yDaqtq
PostgreSQL分布式架构之——PL/Proxy的更多相关文章
- PostgreSQL Replication之第十三章 使用PL/Proxy扩展(3)
13.3 聪明地扩展与处理集群 建立集群不是您面临的唯一任务.如果所有的事情都做完了并且系统已经运行了,您可能需要到处调整配置. 13.3.1 添加和移动分区 一旦一个集群启动并运行,您可能会发现您的 ...
- PostgreSQL Replication之第十三章 使用PL/Proxy扩展(2)
13.2 设置 PL/Proxy 简短的理论介绍之后,我们可以继续前进并运行一些简单的PL/Proxy设置.要做到这一点,我们只需安装PL/Proxy并看看这是如何被使用的. 安装PL/Proxy是一 ...
- PostgreSQL Replication之第十三章 使用PL/Proxy扩展(1)
在这里添加一个slave,真的有一个很好的可扩展性的策略,这基本上足以满足大多数现代应用程序.使用一台服务器的情况下,许多应用程序就会完美地运行,您可能想添加以副本以给基础设施增加一些安全,但在许多情 ...
- PL/Proxy介绍
PL/Proxy 介绍 一.概述 1.PL/Proxy 是一个采用PL Language语言的数据库分区系统. 目的:轻松访问分区数据库 它的理念是代理远程函数体内指定.函数调用同样标签创建的函数,所 ...
- Kubernetes——基于容器技术的分布式架构领先方案,它的目标是管理跨多个主机的容器,提供基本的部署,维护以及运用伸缩
1.Kubernetes介绍 1.1 简介 Kubernetes是什么?首先,它是一个全新的基于容器技术的分布式架构领先方案.其次,它是一个开放的开发平台.最后,它是一个完备的分布式系统支撑平台.Ku ...
- 深入理解java:5. Java分布式架构
什么是分布式架构 分布式系统(distributed system)是建立在网络之上的软件系统. 内聚性是指每一个数据库分布节点高度自治,有本地的数据库管理系统. 透明性是指每一个数据库分布节点对用户 ...
- nginx+iis+redis+Task.MainForm构建分布式架构 之 (redis存储分布式共享的session及共享session运作流程)
本次要分享的是利用windows+nginx+iis+redis+Task.MainForm组建分布式架构,上一篇分享文章制作是在windows上使用的nginx,一般正式发布的时候是在linux来配 ...
- windows+nginx+iis+redis+Task.MainForm构建分布式架构 之 (nginx+iis构建服务集群)
本次要分享的是利用windows+nginx+iis+redis+Task.MainForm组建分布式架构,由标题就能看出此内容不是一篇分享文章能说完的,所以我打算分几篇分享文章来讲解,一步一步实现分 ...
- .net 分布式架构之分布式缓存中间件
开源git地址: http://git.oschina.net/chejiangyi/XXF.BaseService.DistributedCache 分布式缓存中间件 方便实现缓存的分布式,集群, ...
随机推荐
- 《快学 Go 语言》第 16 课 —— 包管理 GOPATH 和 Vendor
到目前位置我们一直在编写单文件代码,只有一个 main.go 文件.本节我们要开始朝完整的项目结构迈进,需要使用 Go 语言的模块管理功能来组织很多的代码文件. 细数 Go 语言的历史发展,模块管理经 ...
- 我写的javascript常用静态方法类,分享给大家
util=function(){ return { $:function(id){ return document.getElementById(id); ...
- MinGW32和64位交叉编译环境的安装和使用
原文出处: CompileGraphics Magick, Boost, Botan and QT with MinGW64 under Windows 7 64 http://www.kinetic ...
- JBMP学习引导
好文: 偶然机会,认识了工作流系统,并且在www.open-open.com(相当不错的开源项目站点,极力推荐!)上了解了些相当出色的工作流系统,不过呼声最高的应该属JBoss 的JBPM工作流组件了 ...
- 【Centos】【Python】【Flask】阿里云上部署一个 flask 项目
1. 安装 python3 和 pip3 参考:http://www.cnblogs.com/mqxs/p/8692870.html 2.安装 lnmpa 集成开发环境 参考:http://www.c ...
- Python学习注脚
python版本:2.7.6 Python基础学习书摘. 变量命名规范: python的变量名只能由字母和数字组成,且必须以字母开头. python的变量名不能使用系统已有的关键字,包括: and c ...
- C#网络唤醒
什么是网络唤醒 网络唤醒实现了对网络的集中管理,即在任何时刻,网管中心的IT管理人员可以经由网络远程唤醒一台处于休眠或关机状态的计算机.使用这一功能,IT管理人员可以在下班后,网络流量最小以及企业的正 ...
- MarkDown 使用说明示例
一.标题 一级标题 二级标题 三级标题 四级标题 五级标题 六级标题 一级标题 这是 H2 这是 H3 一级和二级标题还有一种写法 就是下面加横杆,同时 超过2个的 = 和 - 都可以有效果. Thi ...
- java rpc
一.简介 Hessian和Burlap是由Caucho Technology提供的基于HTTP协议的轻量级远程服务解决方案.他们都致力于借助尽可能简单那的API和通信协议来简化Web服务. He ...
- spark shell学习笔记
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html