TSNE数据降维学习【转载】
转自:https://blog.csdn.net/u012162613/article/details/45920827
https://www.jianshu.com/p/d6e7083d7d61
1.思想
2.例1——鸢尾花数据集降维
# _*_ coding:utf-8 -*-
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt class data():
def __init__(self, data, target):
self.data = data
self.target = target # 加载数据集
iris = load_iris()
# 共有150个例子, 数据的类型是numpy.ndarray
print(iris.data.shape)
# 对应的标签有0,1,2三种
print(iris.target.shape)
# 使用TSNE进行降维处理。从4维降至2维。
tsne = TSNE(n_components=2, learning_rate=100).fit_transform(iris.data)
# 使用PCA 进行降维处理
pca = PCA().fit_transform(iris.data)
# 设置画布的大小
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.scatter(tsne[:, 0], tsne[:, 1], c=iris.target)
plt.subplot(122)
plt.scatter(pca[:, 0], pca[:, 1], c=iris.target)
plt.colorbar()#使用这一句就可以分辨出,颜色对应的类了!神奇啊。
plt.show()
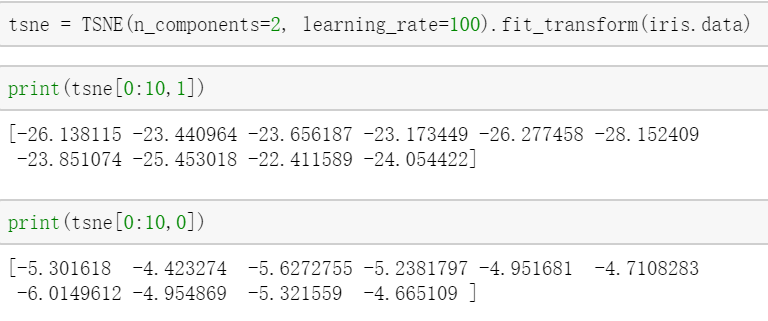
对tsne得到的结果查看,第0维,第1维:
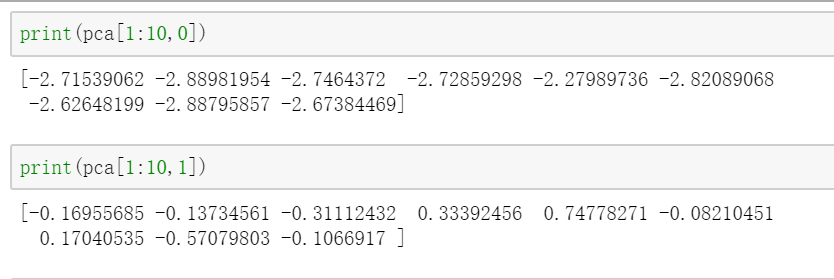
对PCA结果进行查看:
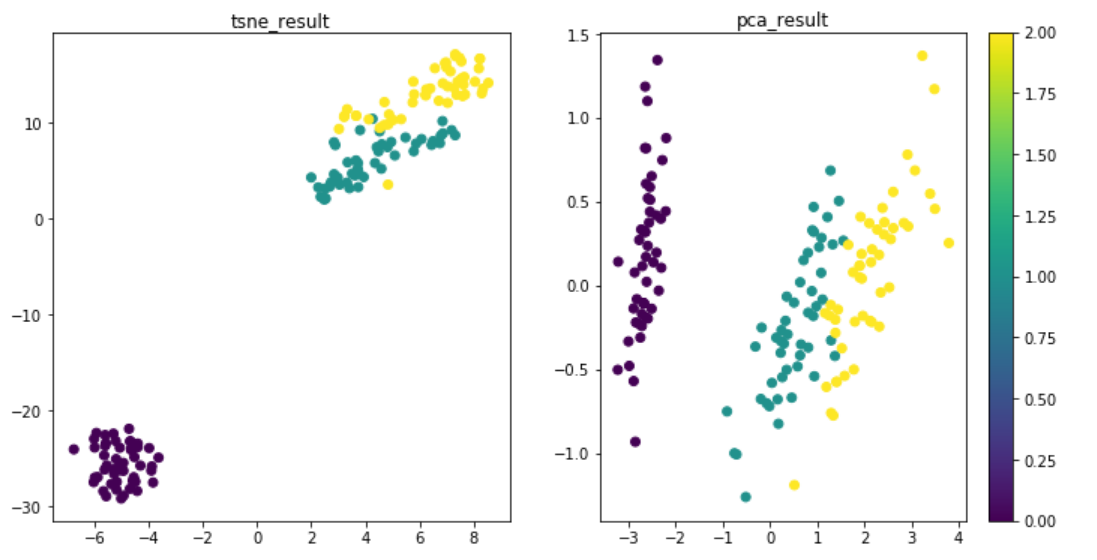
结果:
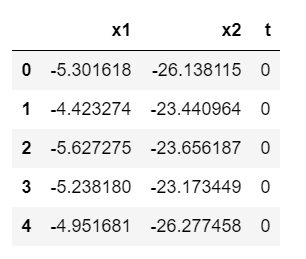
尝试使用Seaborn画图,需要先构造数据框:
import seaborn as sns
import pandas as pd
df=pd.DataFrame(tsne,columns=['x1','x2'])
df['t']=iris.target
df.head()
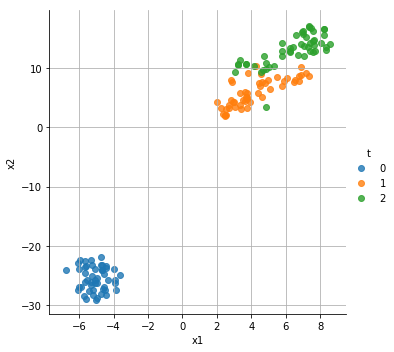
sns.lmplot(x="x1",y="x2",hue="t",data=df,fit_reg=False)
plt.grid(True)
3.例2——MINISET数据集
digits = datasets.load_digits(n_class=5)
X = digits.data
y = digits.target
print X.shape
n_img_per_row = 20
img = np.zeros((10 * n_img_per_row, 10 * n_img_per_row))
for i in range(n_img_per_row):
ix = 10 * i + 1
for j in range(n_img_per_row):
iy = 10 * j + 1
img[ix:ix + 8, iy:iy + 8] = X[i * n_img_per_row + j].reshape((8, 8))
#取前400个,按行放置
#img中会有0、10、20列这些没有,是为了形成空列吧。
plt.imshow(img, cmap=plt.cm.binary)#cmap: 颜色图谱(colormap), 默认绘制为RGB(A)颜色空间。
plt.title('A selection from the 64-dimensional digits dataset')


import time#需导入包
tsne = TSNE(n_components=3, init='pca', random_state=0)
t0 = time
X_tsne = tsne.fit_transform(X)
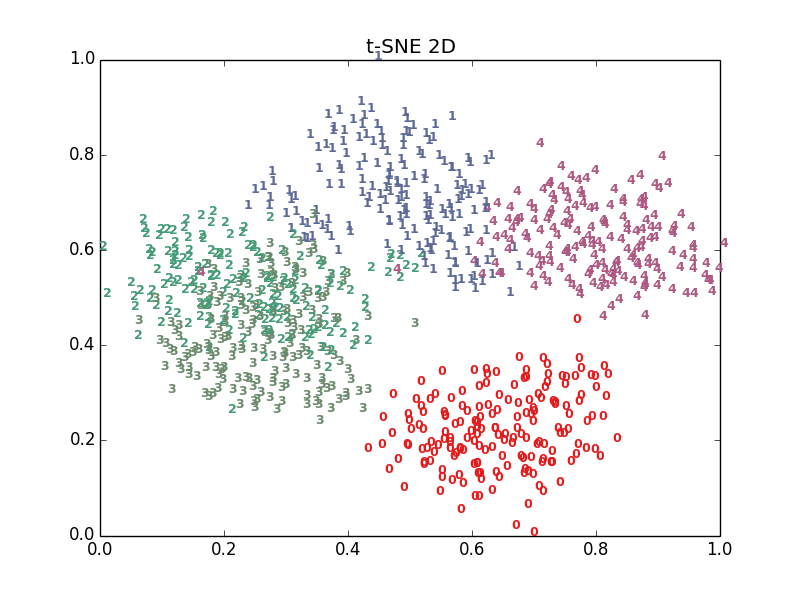
plot_embedding2D(X_tsne[:,0:2],"t-SNE 2D")
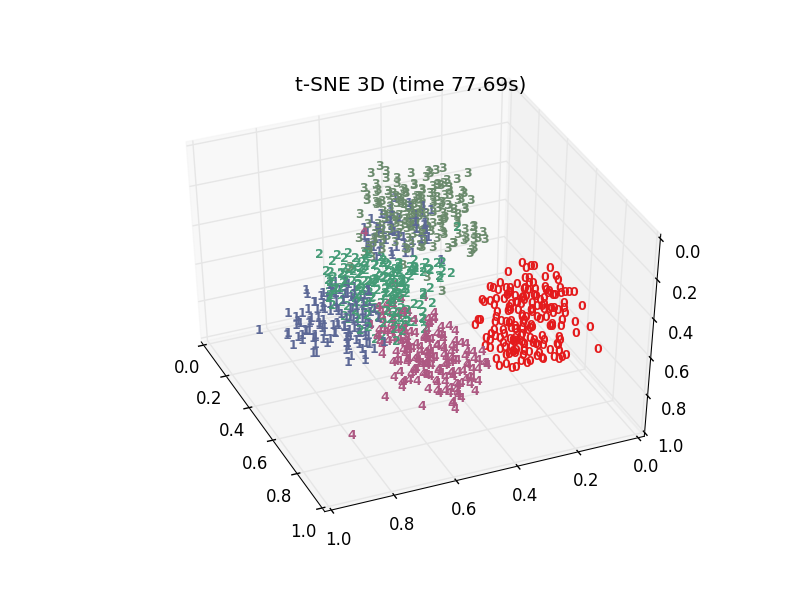
plot_embedding3D(X_tsne,"t-SNE 3D (time %.2fs)" %(time - t0))
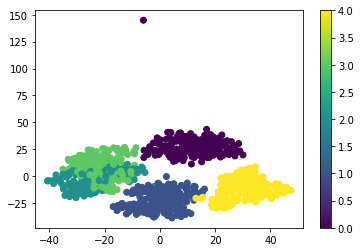
我使用散点图画出的二维结果:
plt.scatter(X_tsne[:,0],X_tsne[:,1],c=Y)
plt.colorbar()
2020-5-8更新——————
1.http://www.datakit.cn/blog/2017/02/05/t_sne_full.html,其实这个讲的一般。
http://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis/
2020-5-13周三更新——————————
1.SNE原理
https://zhuanlan.zhihu.com/p/57937096,讲的不错。
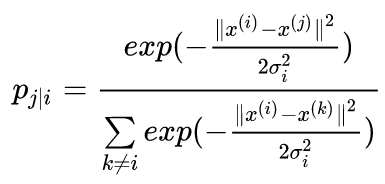
这是在高维空间中,通过仿射将欧几里得距离转换为点之间的相似性的概率分布,p值越大,表示i和j之间的相似性越高,其实也就是表示欧氏距离越小了。高维空间中使用的是高斯分布。
而未知的低维空间中也建立这么一个 分布,sne中使用的同样是高斯分布:
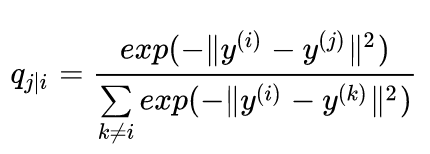
这样的话,想让两个空间中的分布尽可能相似相等,所以使用KL散度来度量:
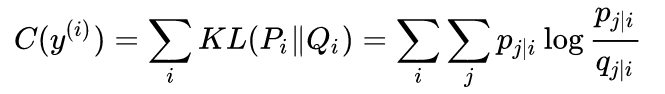
而我们可以看到,KL散度它是不对称的,它是有偏向性的,所以导致了SNE也有偏向性:当p较大,而q较小时损失之较大,翻译过来也就是点在高维空间中相似度较高,但低维空间相似度较小时,损失会比较大;那么sne就会倾向于选择高维空间中距离较远的,而低维空间中距离较近的,所以就说它倾向于保留数据的局部结构(这个时针对于低维空间来说的)。
//但我还是有点想不通,保留这个词不应该针对已知的高维空间吗?高维空间的局部结构不就是点尽可能地相似吗?总之这里感觉很矛盾,保留疑问。

//感觉上面这句话的意思是说,局部特征是针对于低维空间说的,全局结构是针对高维空间说的。所以就说sne更关注于低维空间,也就是局部特征?
2.SNE求解
那么上面主要的参数就是sigma,怎么求呢?
复杂度:
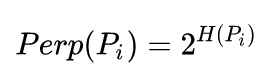
也就是困惑度,可以理解为某个数据点附近有效近邻点的个数。困惑度通常在5-50之间。Hp公式如下:
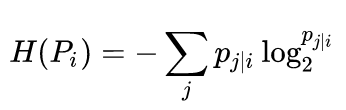
那么在确定了困惑度值之后,就可以根据Hp来计算sigma了。(感觉挺难计算的。)
损失函数对y求梯度:
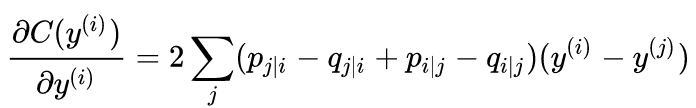
因为我们最终要求的就是yi,数据在2/3维空间中的表示,所以要对它们求梯度啊。
//但是梯度这个计算公式是怎么求的,我还不会。
3.对称TSNE
它使用联合概率分布,所以就是对称的?这一点我还不太懂。
4.t-SNE
//这里的t表示的是t分布,低维空间使用t分布来衡量。
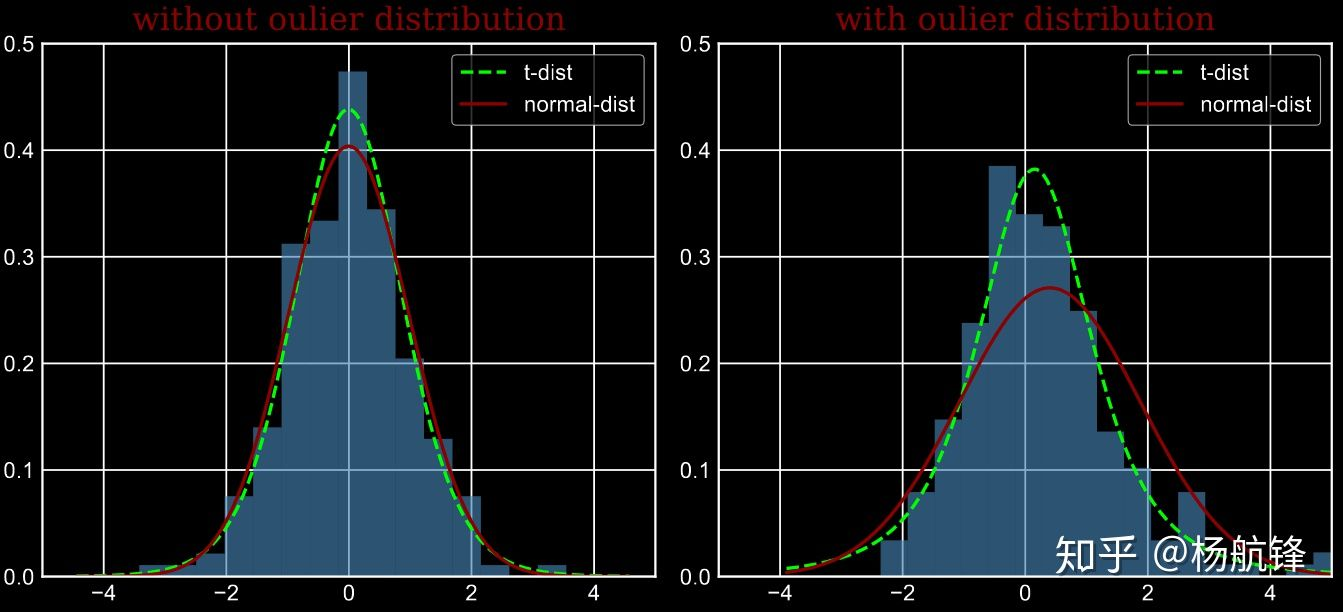
从上面的图和作者的回复来看,因为高斯分布尾部较低对异常值敏感,如果有异常值的话,那么均值方差就会受到影响,曲线形状会照顾那些异常点,而t分布就尾部比较高,对异常点相对不敏感。学习了。而为什么会有异常点出现呢。因为高维降到低维会存在一个拥挤的问题,t可以来缓解这个问题。
使用t分布,低维空间如下:
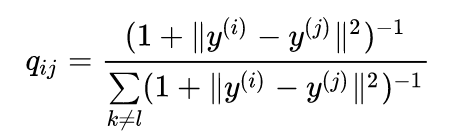
总之,t-sne的改进是:

它主要就是用来可视化。
TSNE数据降维学习【转载】的更多相关文章
- 用TSNE进行数据降维并展示聚类结果
TSNE提供了一种有效的数据降维方式,让我们可以在2维或3维的空间中展示聚类结果. # -*- coding: utf-8 -*- from __future__ import unicode_lit ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- 【Python代码】TSNE高维数据降维可视化工具 + python实现
目录 1.概述 1.1 什么是TSNE 1.2 TSNE原理 1.2.1入门的原理介绍 1.2.2进阶的原理介绍 1.2.2.1 高维距离表示 1.2.2.2 低维相似度表示 1.2.2.3 惩罚函数 ...
- matlab 降维工具 转载【https://blog.csdn.net/tarim/article/details/51253536】
降维工具箱drtool 这个工具箱的主页如下,现在的最新版本是2013.3.21更新,版本v0.8.1b http://homepage.tudelft.nl/19j49/Matlab_Toolb ...
- 使用t-SNE做降维可视化
最近在做一个深度学习分类项目,想看看训练集数据的分布情况,但由于数据本身维度接近100,不能直观的可视化展示,所以就对降维可视化做了一些粗略的了解以便能在低维空间中近似展示高维数据的分布情况,以下内容 ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- Java多线程学习(转载)
Java多线程学习(转载) 时间:2015-03-14 13:53:14 阅读:137413 评论:4 收藏:3 [点我收藏+] 转载 :http://blog ...
- Coursera《machine learning》--(14)数据降维
本笔记为Coursera在线课程<Machine Learning>中的数据降维章节的笔记. 十四.降维 (Dimensionality Reduction) 14.1 动机一:数据压缩 ...
- 高维数据降维 国家自然科学基金项目 2009-2013 NSFC Dimensionality Reduction
2013 基于数据降维和压缩感知的图像哈希理论与方法 唐振军 广西师范大学 多元时间序列数据挖掘中的特征表示和相似性度量方法研究 李海林 华侨大学 基于标签和多特征融合的图像语义空间学习技 ...
随机推荐
- Material Design系列第四篇——Defining Shadows and Clipping Views
Defining Shadows and Clipping Views This lesson teaches you to Assign Elevation to Your Views Custom ...
- Esper学习之十五:Pattern(二)
上一篇开始了新一轮语法——Pattern的讲解,一开始为大家普及了几个基础知识,其中有说到操作符.当时只是把它们都列举出来了,所以今天这篇就是专门详解这些操作符的,但是由于篇幅限制,本篇先会讲几个,剩 ...
- 【Spring源码分析系列】bean的加载
前言 以 BeanFactory bf = new XmlBeanFactory(new ClassPathResource("beans.xml"));为例查看bean的加载过 ...
- 告知你不为人知的UDP-连接性和负载均衡
版权声明:本文由黄日成原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/812444001486438028 来源:腾云阁 h ...
- MySQL数据库执行sql语句创建数据库和表提示The 'InnoDB' feature is disabled; you need MySQL built with 'InnoDB' to have it working
MySQL创建数据库 只想sql文件创建表时候提示 The 'InnoDB' feature is disabled; you need MySQL built with 'InnoDB' to ha ...
- laravel部署常用命令
php composer install composer dump-autoload php artisan key:generate .env 及 config/database.php里的数据库 ...
- linux mint 安装 SecureCRT
最喜欢的ssh工具莫过于SecureCRT了,功能强大,方便易用.最近安装了mint17.1(基于ubuntu),就想安装一个SecureCRT来使用. [此SecureCRT仅作测试使用,不做商业用 ...
- PhpDocumentor
phpDocument是一个通用的生成PHP文档的工具,他本身也是用PHP写的,跟JAVADoc有些相似,但他有不同于PHPDoc,他比PHPDOC要快,而且能够解析的PHP范围更广,他本身包含了11 ...
- jenkins之另辟蹊径实现根据svn项目实现智能选择
项目要求,根据svn选择的trunk或branches及tags里的各分支,动态选择参数.一开始认为很简单,直接用jenkins中的List Subversion tags插件及active choi ...
- Docker Swarm——集群管理
前言 之前在总结docker machine的时候,当时对docker理解还不够深入,甚至还不知道 docker machine 与 docker swarm 的区别. 在查阅资料以及官方文档之后,今 ...