HBase写入性能及改造——multi-thread flush and compaction(续:详细测试数据)[转]
转载:http://blog.csdn.net/kalaamong/article/details/7290192
接上文啊:
| CPU | 16* Intel(R) Xeon(R) CPU E5620 @ 2.40GHz |
|---|---|
| MEMORY | 48GB |
| DISK | 12*SATA 2TB |
| NET | 4*1Gb Ethernet |
测试数据:
| 类型 | 国内某视频网站近半年用户访问日志 |
| 结构 | 一行九列,包括用户访问页,关键词及其它用户信息。对应HBase一个family下9个column,一行120到180字节 |
| 数据量 | 每次测试写入10亿条数据,原始数据约110GB,写到HBase中一张不加压缩的表里HDFS中单副本约480GB (dus结果) |
集群结构
| RegionServer | 1个 hostname: data2 |
| DataNode | 5个hostname: data12~data16 |
这样设设计的集群结构,主要目的就是要压测Region Server。以下所有测试客户端put关HLog,服务端不split。
第一组:(原始情况)
这是最初Hbase的情况,没有对服务端代码做修改,在配置参数上稍稍改动了类似于MemStore up water level,low water level,以及handler数目和HFile的最大Size值。可以看出虽然是压测,hbase所有地方都很闲,内部的情况是就Multi写入数据了之后MemStore大了等flush,flush的store file多了就等compact。各种等也就各种闲。
最后写入10亿行数据用时6小时48分。整个表在HDFS dus出的大小约440GB。


第二组:(配置项修改)
下面的图是继上面情况之后修改了
<property>
<name>hbase.hstore.blockingStoreFiles</name>
<value>2000</value>
</property>
把block flush的storefile数从默认的7改到了2000,已经不让split了,还不许storefile数多一点,太没人性了。此时前段时间写入的性能有些改善,但毕竟还是单线程的flush和compact治标不治本。
最后写入10亿行数据用时5小时54分,比上一组实验缩短了1个小时。整个表在HDFS dus出的大小约480GB,原因应当是flush被阻塞的次数减少,flush得更频繁了,写入流量也稍增,但没来得及compact的store file更多,所以整个表大了40G( 约9%)。


第三组:(代码修改)
最后来治标治本吧。后面的实验中配置参数与上一组相同,同时服务端修改代码,为flush和compact添加了线程池。并新加入两个配置项:
25 <property>
26 <name>hbase.hstore.flush.thread</name>
27 <value>20</value>
28 </property>
29 <property>
30 <name>hbase.hstore.compaction.thread</name>
31 <value>15</value>
32 </property>
再看压测情况CPU基本满载。唉这才是压测啊!!
如此这般下来写入10亿行数据用时2小时58分,不到第一组一半的时间。表大小约410GB
由于compact做得及时,表大小比第一组小30GB,比第二组小70GB。


第四组:(代码修改加压缩)
接着按第三组的情况加上GZ的软压缩(为什么挑GZ请参第五组测试),这组估计CPU都要冒烟了。
写入10亿行数据耗时3小时5分,比上一组多了7分钟。但表的size为71GB !差不多是上一组的六分之一,尽然压缩到了原数据的17%大小。
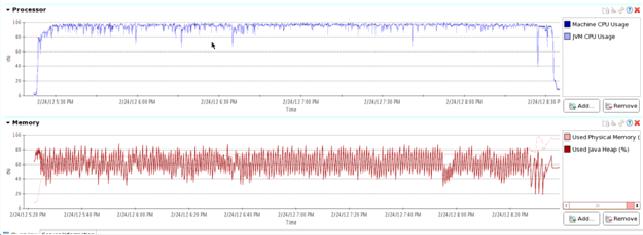
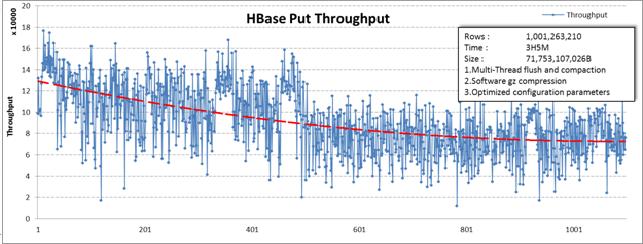
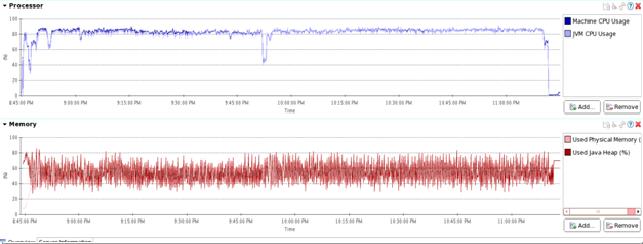
第五组:(第五组大家自己研究吧)
这一组最强悍,采用了一些特殊的硬件改了改HDFS,HBase的修改与上两组相同。
写入10亿行数据耗时2小时24分钟。差不多是第一组时间的1/3。文件size为111GB,压到了第一组的1/4。且CPU也没到冒烟的状态,应当还能加压。关于这个组今后还将有更详细的测试结果放出。现在先不详细介绍了。

HBase写入性能及改造——multi-thread flush and compaction(续:详细测试数据)[转]的更多相关文章
- HBase写入性能改造(续)--MemStore、flush、compact参数调优及压缩卡的使用【转】
首先续上篇测试: 经过上一篇文章中对代码及参数的修改,Hbase的写入性能在不开Hlog的情况下从3~4万提高到了11万左右. 本篇主要介绍参数调整的方法,在HDFS上加上压缩卡,最后能达到的写入 ...
- 多Region下HBase写入问题
最近在集群上发现hbase写入性能受到较大下降,测试环境下没有该问题产生.而生产环境和测试环境的区别之一是生产环境的region数量远远多于测试环境,单台regionserver服务了约3500个re ...
- 提高HBase写性能
以下为使用hbase一段时间的三个思考,由于在内存充足的情况下hbase能提供比较满意的读性能,因此写性能是思考的重点.希望读者提出不同意见讨论 1 autoflush=false的影响 无论是官方还 ...
- 万字长文详解HBase读写性能优化
一.HBase 读优化 1. HBase客户端优化 和大多数系统一样,客户端作为业务读写的入口,姿势使用不正确通常会导致本业务读延迟较高实际上存在一些使用姿势的推荐用法,这里一般需要关注四个问题: 1 ...
- HBase配置性能调优(转)
因官方Book Performance Tuning部分章节没有按配置项进行索引,不能达到快速查阅的效果.所以我以配置项驱动,重新整理了原文,并补充一些自己的理解,如有错误,欢迎指正. 配置优化 zo ...
- HBase配置性能调优
因官方Book Performance Tuning部分章节没有按配置项进行索引,不能达到快速查阅的效果.所以我以配置项驱动,重新整理了原文,并补充一些自己的理解,如有错误,欢迎指正. 配置优化 zo ...
- hbase实践之flush and compaction
本文主要涉及flush流程,探讨flush流程过程中引入的问题并阐述2种解决策略,最后简要说明Flush执行策略. 对于Compaction,本文主要探讨Compaction要解决的本质问题以及由Co ...
- MySQL · 性能优化· InnoDB buffer pool flush策略漫谈
MySQL · 性能优化· InnoDB buffer pool flush策略漫谈 背景 我们知道InnoDB使用buffer pool来缓存从磁盘读取到内存的数据页.buffer pool通常由数 ...
- 公司HBase基准性能测试之结果篇
上一篇文章<公司HBase基准性能测试之准备篇>中详细介绍了本次性能测试的基本准备情况,包括测试集群架构.单台机器软硬件配置.测试工具以及测试方法等,在此基础上本篇文章主要介绍HBase在 ...
随机推荐
- ios中封装九宫格的使用(二级导航)
效果图 一般用于导航功能 第一步下载http://pan.baidu.com/share/link?shareid=1824940819&uk=923776187 第二步 把下图内容放在你的x ...
- HDUOJ-------The Hardest Problem Ever
The Hardest Problem Ever Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java ...
- linux磁盘相关命令
一.查看文件夹大小du du -h -d1 2>/dev/null 解释: h表示以可读性较好的方式显示,即带单位显示 d表示深度depth,为1表示只显示当前目录下文件的大小 2>/de ...
- Weex学习与实践
Weex学习与实践(一):Weex,你需要知道的事 本文主要介绍包括Weex基本介绍.Weex源码结构.初始化工程.we代码结构.Weex的生命周期.Weex的工作原理.页面间通信.boxmodel ...
- nginx配置文件结构,语法,配置命令解释
摘要: nginx的配置文件类似于一门优雅的编程语言,弄懂了它的规范就可以自定义配置文件了,这个很重要~ 1,结构分析 nginx配置文件中主要包括六块:main,events,http,server ...
- 指尖下的js ——多触式web前端开发之二:处理简单手势(转)
这篇文章将描述多触式网页开发中对手势(Gesture)事件的处理. 水果设备中的Gesture,广义的说包括手指点击(click),轻拂(flick),双击(double-click),两只手 ...
- 【Java】解析JScrollPane类的使用
在这篇博文中,笔者介绍JScrollPane类的使用,JScrollPane类可以为组件添加滚动条.在这里笔者不会详细介绍该类的方法有哪些,因为在API上已经写得一清二楚了.在这篇博文中,笔者重点介绍 ...
- AndroidStudio升级到2.3版本无法编译的解决方法
上周五as提示更新,于是为了体验新功能还在编码过程中就迫不及待的点击了更新,公司网很快,十几分钟就下载好,然后一重启就懵逼了,提示是否更改依赖版本到2.3以及升级gradle到3.3,点了确定就一直在 ...
- C语言中的 (void*)0 与 (void)0
前几天看到一个宏, 它大概是这样的: #define assert_param(expr) ((expr) ? (void)0 : assert_failed((u8 *)__FILE__, __LI ...
- 实现一个简单的android开关
近期在学习android中的graphics中绘图系列.依照大神思路.找葫芦画瓢实现了一个开关.如图下: 记录一下实现方式: 1.画背景 上图形状.分成两个半圆与一个矩形,那么代码能够写成: priv ...