神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词。看完后有一些自己的小想法,也想做一个玩儿一玩儿。用到的原理是深度学习里的循环神经网络,无奈理论太艰深,只能从头开始开始慢慢看,因此产生写一个项目的想法,把机器学习和深度学习里关于分类的算法整理一下,按照原理写一些demo,方便自己也方便其他人。项目地址:https://github.com/LiuRoy/classfication_demo,目前实现了逻辑回归和神经网络两种分类算法。
Logistic回归
这是相对比较简单的一种分类方法,准确率较低,也只适用于线性可分数据,网上有很多关于logistic回归的博客和文章,讲的也都非常通俗易懂,就不赘述。此处采用随机梯度下降的方式实现,讲解可以参考《机器学习实战》第五章logistic回归。代码如下:
def train(self, num_iteration=150):
"""随机梯度上升算法
Args:
data (numpy.ndarray): 训练数据集
labels (numpy.ndarray): 训练标签
num_iteration (int): 迭代次数
"""
for j in xrange(num_iteration):
data_index = range(self.data_num)
for i in xrange(self.data_num):
# 学习速率
alpha = 0.01
rand_index = int(random.uniform(0, len(data_index)))
error = self.label[rand_index] - sigmoid(sum(self.data[rand_index] * self.weights + self.b))
self.weights += alpha * error * self.data[rand_index]
self.b += alpha * error
del(data_index[rand_index])
效果图:
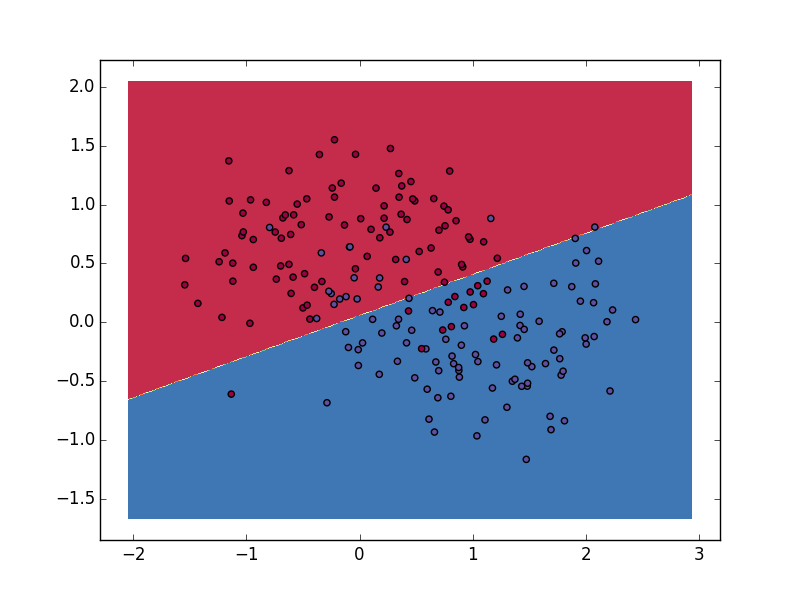
神经网络
参考的是这篇文章,如果自己英语比较好,还可以查看英文文章,里面有简单的实现,唯一的缺点就是没有把原理讲明白。关于神经网络,个人认为确实不是一两句就能解释清楚的,尤其是网上的博客,要么只给公式,要么只给图,看起来都非常的晦涩,建议大家看一下加州理工的一个公开课,有中文字幕,一个小时的课程绝对比自己花一天查文字资料理解的深刻,知道原理之后再来看前面的那篇博客就很轻松啦!
BGD实现
博客里面实现用的是批量梯度下降(batch gradient descent),代码:
def batch_gradient_descent(self, num_passes=20000):
"""批量梯度下降训练模型"""
for i in xrange(0, num_passes):
# Forward propagation
z1 = self.data.dot(self.W1) + self.b1
a1 = np.tanh(z1)
z2 = a1.dot(self.W2) + self.b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Backpropagation
delta3 = probs
delta3[range(self.num_examples), self.label] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(self.W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(self.data.T, delta2)
db1 = np.sum(delta2, axis=0)
# Add regularization terms (b1 and b2 don't have regularization terms)
dW2 += self.reg_lambda * self.W2
dW1 += self.reg_lambda * self.W1
# Gradient descent parameter update
self.W1 += -self.epsilon * dW1
self.b1 += -self.epsilon * db1
self.W2 += -self.epsilon * dW2
self.b2 += -self.epsilon * db2
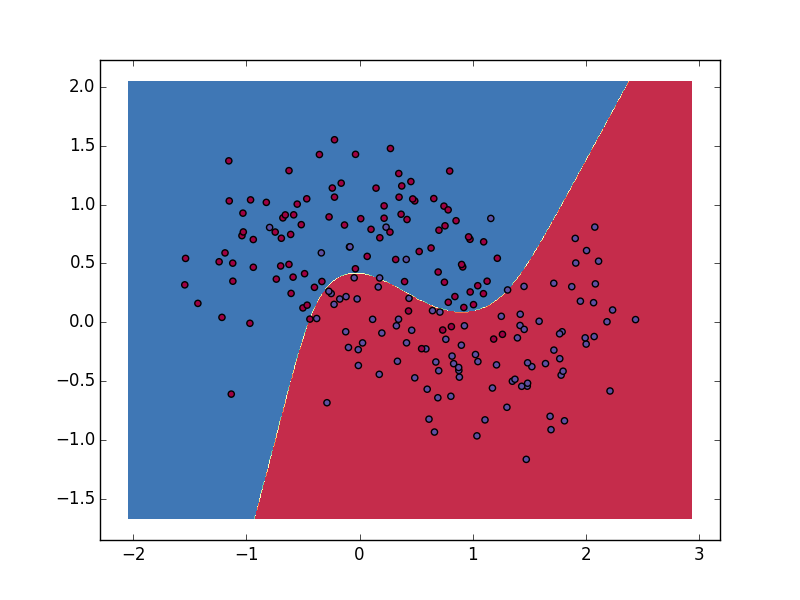
效果图:

注意:强烈怀疑文中的后向传播公式给错了,因为和代码里的delta2 = delta3.dot(self.W2.T) * (1 - np.power(a1, 2))对不上。
SGD实现
考虑到logistic回归可以用随机梯度下降,而且公开课里面也说随机梯度下降效果更好一些,所以在上面的代码上自己改动了一下,代码:
def stochastic_gradient_descent(self, num_passes=200):
"""随机梯度下降训练模型"""
for i in xrange(0, num_passes):
data_index = range(self.num_examples)
for j in xrange(self.num_examples):
rand_index = int(np.random.uniform(0, len(data_index)))
x = np.mat(self.data[rand_index])
y = self.label[rand_index]
# Forward propagation
z1 = x.dot(self.W1) + self.b1
a1 = np.tanh(z1)
z2 = a1.dot(self.W2) + self.b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Backpropagation
delta3 = probs
if y:
delta3[0, 0] -= 1
else:
delta3[0, 1] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
va = delta3.dot(self.W2.T)
vb = 1 - np.power(a1, 2)
delta2 = np.mat(np.array(va) * np.array(vb))
dW1 = x.T.dot(delta2)
db1 = np.sum(delta2, axis=0)
# Add regularization terms (b1 and b2 don't have regularization terms)
dW2 += self.reg_lambda * self.W2
dW1 += self.reg_lambda * self.W1
# Gradient descent parameter update
self.W1 += -self.epsilon * dW1
self.b1 += -self.epsilon * db1
self.W2 += -self.epsilon * dW2
self.b2 += -self.epsilon * db2
del(data_index[rand_index])
可能是我写的方式不好,虽然可以得到正确的结果,但是性能上却比不上BGD,希望大家能指出问题所在,运行效果图:
其他
SVM我还在看,里面的公式推导能把人绕死,稍晚一点写好合入,数学不好就是坑啊
神经网络、logistic回归等分类算法简单实现的更多相关文章
- 02-15 Logistic回归(鸢尾花分类)
目录 Logistic回归(鸢尾花分类) 一.导入模块 二.获取数据 三.构建决策边界 四.训练模型 4.1 C参数与权重系数的关系 五.可视化 更新.更全的<机器学习>的更新网站,更有p ...
- 《转》Logistic回归 多分类问题的推广算法--Softmax回归
转自http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92 简介 在本节中,我们介绍Softmax回归模型,该模型是log ...
- 【2008nmj】Logistic回归二元分类感知器算法.docx
给你一堆样本数据(xi,yi),并标上标签[0,1],让你建立模型(分类感知器二元),对于新给的测试数据进行分类. 要将两种数据分开,这是一个分类问题,建立数学模型,(x,y,z),z指示[0,1], ...
- Logistic回归二分类Winner or Losser----台大李宏毅机器学习作业二(HW2)
一.作业说明 给定训练集spam_train.csv,要求根据每个ID各种属性值来判断该ID对应角色是Winner还是Losser(0.1分类). 训练集介绍: (1)CSV文件,大小为4000行X5 ...
- Sklearn中的回归和分类算法
一.sklearn中自带的回归算法 1. 算法 来自:https://my.oschina.net/kilosnow/blog/1619605 另外,skilearn中自带保存模型的方法,可以把训练完 ...
- logistic regression二分类算法推导
- 《Machine Learning in Action》—— Taoye给你讲讲Logistic回归是咋回事
在手撕机器学习系列文章的上一篇,我们详细讲解了线性回归的问题,并且最后通过梯度下降算法拟合了一条直线,从而使得这条直线尽可能的切合数据样本集,已到达模型损失值最小的目的. 在本篇文章中,我们主要是手撕 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- 【机器学习实战】第5章 Logistic回归
第5章 Logistic回归 Logistic 回归 概述 Logistic 回归虽然名字叫回归,但是它是用来做分类的.其主要思想是: 根据现有数据对分类边界线建立回归公式,以此进行分类. 须知概念 ...
随机推荐
- H5单页面手势滑屏切换原理
H5单页面手势滑屏切换是采用HTML5 触摸事件(Touch) 和 CSS3动画(Transform,Transition)来实现的,效果图如下所示,本文简单说一下其实现原理和主要思路. 1.实现原理 ...
- 漫扯:从polling到Websocket
Http被设计成了一个单向的通信的协议,即客户端发起一个request,然后服务器回应一个response.这让服务器很为恼火:我特么才是老大,我居然不能给小弟发消息... 轮询 老大发火了,小弟们自 ...
- 8.仿阿里云虚拟云服务器的FTP(包括FTP文件夹大小限制)
平台之大势何人能挡? 带着你的Net飞奔吧!:http://www.cnblogs.com/dunitian/p/4822808.html#iis 原文:http://dnt.dkill.net/Ar ...
- Electron使用与学习--(基本使用与菜单操作)
对于electron是个新手,下面纯属个人理解.如有错误,欢迎指出. 一.安装 如果你本地按照github上的 # Install the `electron` command globally ...
- 玩转spring boot——结合redis
一.准备工作 下载redis的windows版zip包:https://github.com/MSOpenTech/redis/releases 运行redis-server.exe程序 出现黑色窗口 ...
- Python学习基础
1.使用范围: 大数据 .图像处理.web .运维.爬虫.自动化.科学计算 2.准备环境: linux/mac python 3.5.2 ipython vim/sublime/atom 3.列表 3 ...
- SpringMVC_简单小结
SpringMVC是一个简单的.优秀的框架.应了那句话简单就是美,而且他强大不失灵活,性能也很优秀. 机制:spring mvc的入口是servlet,而struts2是filter(这里要指出,fi ...
- mono3.2和monodevelop4.0在ubuntu12.04上两天的苦战
首先第一步是设置ubuntu server 12.04版更新源,推荐中科大的比较快:deb http://debian.ustc.edu.cn/ubuntu/ precise main multive ...
- Java中的Checked Exception——美丽世界中潜藏的恶魔?
在使用Java编写应用的时候,我们常常需要通过第三方类库来帮助我们完成所需要的功能.有时候这些类库所提供的很多API都通过throws声明了它们所可能抛出的异常.但是在查看这些API的文档时,我们却没 ...
- ABP框架 - 介绍
文档目录 本节内容: 简介 一个快速示例 其它特性 启动模板 如何使用 简介 我们总是对不同的需求开发不同的应用.但至少在某些层面上,一次又一次地重复实现通用的和类似的功能.如:授权,验证,异常处理, ...