torch 深度学习(4)
torch 深度学习(4)
经过数据的预处理、模型创建、损失函数定义以及模型的训练,现在可以使用训练好的模型对测试集进行测试了。测试模块比训练模块简单的多,只需调用模型就可以了
测试模块
加载模块
require 'torch'
require 'xlua' -- 主要使用进度条用到
require 'optim' -- confusionMatrix和Logger会用到
这里多说一句,为什么每个模块都没有调用之前的模块呢?这是因为我们我们最终是将之前的预处理、建模等模块放到一个项目里面一起end-to-end执行的,而且模块里面的共享参数都是全局变量所以不需要再加载之前的模块了。如果单独执行某一个文件,比如_'3_loss.lua' 文件,里面为了能够运行,创建了一个model=nn.Sequential()只是为了运行没有实际意义,像 '4_train.lua' 模块不加载之前的模块则不能单独运行。
测试函数
function test()
local time = sys.time()
for t=1,testData:size() do
xlua.progress(t, testData:size())
local input=testData.data[t]:double()
local target = testData.labels[t]
pred = model:forward(input) --使用模型预测
local _,indices = torch.sort(pred,true) --降序排列
confusion:add(indices[1],target) --注意这里的混淆矩阵是在4_train.lua中定义的,每次都清零了,所以没有影响
end
time=sys.clock()-time
time=time/testData:size() -- 单位所需时间
print('==> time to test 1 sample =' .. (time*1000) .. 'ms') -- ms单位
print(confusion) --打印混淆矩阵
testLogger.add{['% mean class accuracy (test set)'] = confusion.totalValid*100}
if opt.plot then
testLogger:style('-') --折线图
testLogger:plot() --结果变化趋势图
end
confusion:zero() --reset confusionMatrix
end
项目执行
将所有的模块放到一起统一执行
加载模块
require 'torch' -- 其他模块需要的包他们自己加载
设置参数,注意这里设置了opt参数,那么其他模块的命令行参数设置的代码块都不会执行
cmd = torch.CmdLine()
cmd:text()
cmd:text('参数设置')
cmd:text()
cmd:text('Options:')
cmdLtext()
cmd:option('-seed',1,'fixed input seed for repeatable experiments') --因为代码涉及到随机数,为了实验的可重复性,设置固定的随机种子值
cmd:option('-size','small','how many samples do we load: small | full | extra')
cmd:option('-model','convnet','type of model to construct: linear | mlp | convnet')
cmd:option('-loss','nll','type of loss function to minimization: nll | mse | margin')
cmd:option('-save','results','subdirectory to save/log experiments in')
cmd:option('-plot',false,'live plot')
cmd:option('-optimization','SGD','optimization method: SGD | ASGD | LBFGS | CG')
cmd:option('-batchSize',10,'mini-batchSize (1= pure stochastic)')
cmd:option('-learningRate',1e-3,'learning rate at t=0')
cmd:option('-weightDecay',0, 'weight decay(SGD only)')
cmd:option('-momentum',0,'momentum(SGD only)')
cmd:option('-t0',1,'start average at t0 (ASGD only) in nb of epochs')
cmd:option('-maxIter',2,'maximum nb of iteration for CG and LBFGS')
cmd:text()
opt=cmd:parse(arg or {})
torch.setnumthread(4) --设置并行的线程数,这个不能设置太大,因为线程切换也需要时间,而且他们共用模型参数
torch.manualSeed(opt.seed) --设置随机种子
依次执行模块
dofile '1_data.lua'
dofile '2_model.lua'
dofile '3_loss.lua'
dofile '4_train.lua'
dofile '5_test.lua'
dofile 是lua语言里面的函数, loadfile 编译不运行, dofile 运行文件,参见Lua中require,dofile、dofile的区别
训练并测试
while true do
train()
test()
if epoch == 30 then
break;
end
if epoch == 27 then
opt.plot=true
end
end
这里我执行了30个周期,并且在输出后4个周期的实验结果,这里是指结果变化曲线图
实验结果
1.混淆矩阵(第27次)
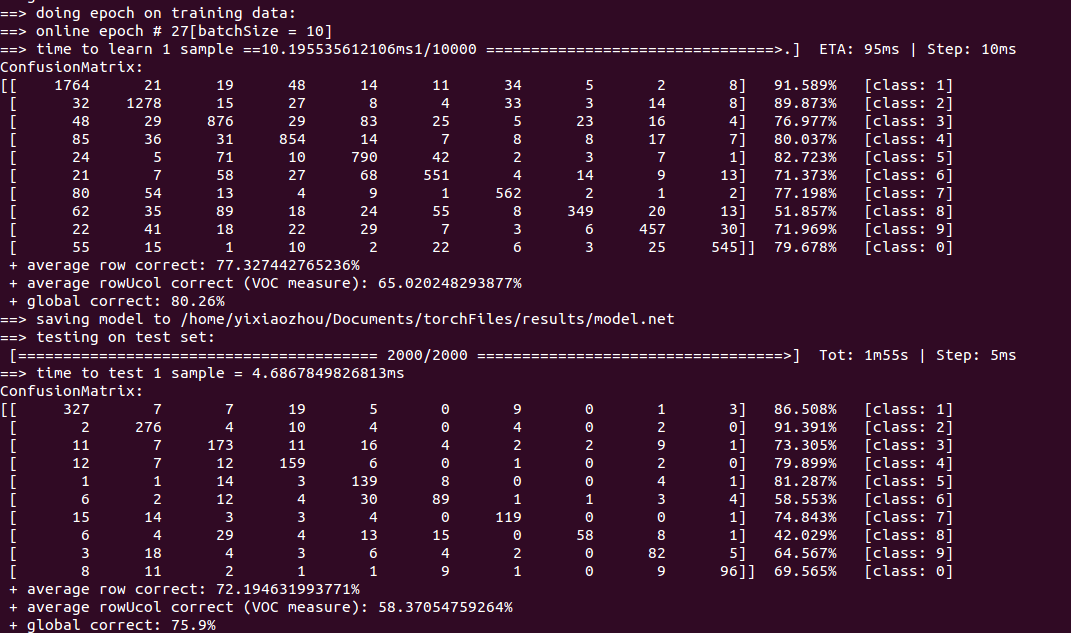
混淆矩阵的可视化显示 render,这个图像的对角线表示正确对应类的正确率,每一行非对角就是错分别别的类的比率
Confusion matrix
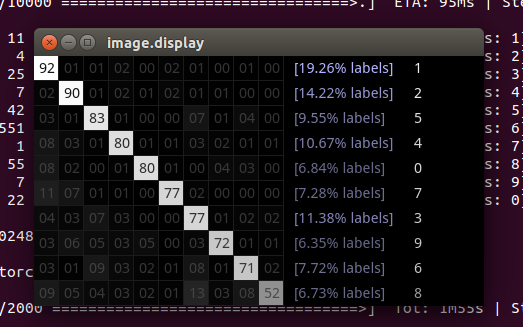
日志文件

模型性能变化趋势
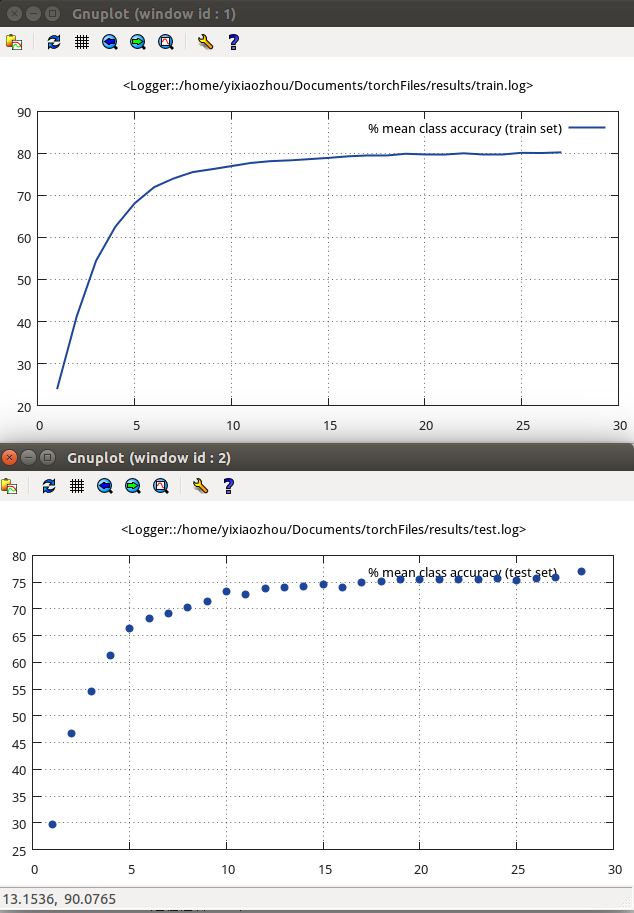
观测这两个图可以发现训练集曲线是单调递增的,这是因为优化算法目标就是让性能不断上升,但也只是能够保证训练集,而对于测试集显然有时候精度反而下降了。这也体现了泛化的概念,训练集好不一定训练集也好,可能过拟合
这段代码都是跑的small规模数据集,10000个训练样本,大约80s完成一次epoch的训练。我是用full规模数据训练,7万多数据训练跑到50次左右训练集结果95%左右,测试集93%左右,时间训练一轮大约13分钟
torch 深度学习(4)的更多相关文章
- torch 深度学习(5)
torch 深度学习(5) mnist torch siamese deep-learning 这篇文章主要是想使用torch学习并理解如何构建siamese network. siamese net ...
- torch 深度学习(3)
torch 深度学习(3) 损失函数,模型训练 前面我们已经完成对数据的预处理和模型的构建,那么接下来为了训练模型应该定义模型的损失函数,然后使用BP算法对模型参数进行调整 损失函数 Criterio ...
- torch 深度学习 (2)
torch 深度学习 (2) torch ConvNet 前面我们完成了数据的下载和预处理,接下来就该搭建网络模型了,CNN网络的东西可以参考博主 zouxy09的系列文章Deep Learning ...
- 深度学习菜鸟的信仰地︱Supervessel超能云服务器、深度学习环境全配置
并非广告~实在是太良心了,所以费时间给他们点赞一下~ SuperVessel云平台是IBM中国研究院和中国系统与技术中心基于POWER架构和OpenStack技术共同构建的, 支持开发者远程开发的免费 ...
- 深度学习框架caffe/CNTK/Tensorflow/Theano/Torch的对比
在单GPU下,所有这些工具集都调用cuDNN,因此只要外层的计算或者内存分配差异不大其性能表现都差不多. Caffe: 1)主流工业级深度学习工具,具有出色的卷积神经网络实现.在计算机视觉领域Caff ...
- 小白学习之pytorch框架(2)-动手学深度学习(begin-random.shuffle()、torch.index_select()、nn.Module、nn.Sequential())
在这向大家推荐一本书-花书-动手学深度学习pytorch版,原书用的深度学习框架是MXNet,这个框架经过Gluon重新再封装,使用风格非常接近pytorch,但是由于pytorch越来越火,个人又比 ...
- [深度学习] Pytorch学习(一)—— torch tensor
[深度学习] Pytorch学习(一)-- torch tensor 学习笔记 . 记录 分享 . 学习的代码环境:python3.6 torch1.3 vscode+jupyter扩展 #%% im ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- [深度学习大讲堂]从NNVM看2016年深度学习框架发展趋势
本文为微信公众号[深度学习大讲堂]特约稿,转载请注明出处 虚拟框架杀入 从发现问题到解决问题 半年前的这时候,暑假,我在SIAT MMLAB实习. 看着同事一会儿跑Torch,一会儿跑MXNet,一会 ...
随机推荐
- web Servlet 3.0 新特性之web模块化编程,web-fragment.xml编写及打jar包
web Servlet 3.0 模块化 原本一个web应用的任何配置都需要在web.xml中进行,因此会使得web.xml变得很混乱,而且灵活性差,因此Servlet 3.0可以将每个Servlet. ...
- python手写神经网络实现识别手写数字
写在开头:这个实验和matlab手写神经网络实现识别手写数字一样. 实验说明 一直想自己写一个神经网络来实现手写数字的识别,而不是套用别人的框架.恰巧前几天,有幸从同学那拿到5000张已经贴好标签的手 ...
- php int 与 datetime 转换
数据库日期类型是int类型的,该查询结果是datetime类型的 select from_unixtime( `dateline` ) from cdb_posts 如果原来类型是datetime类型 ...
- TWebBrowser: Determine when a page with Frames is completed
TWebBrowser: Determine when a page with Frames is completed 6 comments. Current rating: (3 votes). L ...
- Extjs3.4 grid中添加一列复选框
var sm = new Ext.grid.CheckboxSelectionModel(); var cm = new Ext.grid.ColumnModel( [ sm, new Ext.gri ...
- PKU 1932 XYZZY(Floyd+Bellman||Spfa+Floyd)
题目大意:原题链接 给你一张图,初始你在房间1,初始生命值为100,进入每个房间会加上那个房间的生命(可能为负),问是否能到达房间n.(要求进入每个房间后生命值都大于0) 解题思路: 解法一:Floy ...
- web.xml中配置spring配置(application.xml)文件
application.xml 一般放到WEB-INF下,当然,你也可以将它放到任意问题,但需要web.xml指向到该文件 1.application.xml配置 <?xml version=& ...
- Jenkins系统+独立部署系统
原文出自:http://os.51cto.com/art/201601/504846.htm 有了Jenkins,为什么还需要一个独立的部署系统? 现在已经有Jenkins,它自身提供了丰富的部署插件 ...
- 命令查看java的class字节码文件
源代码: public class Math { public static void main(String[] args){ int a=1; int b=2; int c=(a+b)*10; } ...
- sgu 103 Traffic Lights 解题报告及测试数据
103. Traffic Lights Time limit per test: 0.25 second(s) Memory limit: 4096 kilobytes 题解: 1.其实就是求两点间的 ...