LightGBM
1.简介
lightGBM包含两个关键点:light即轻量级,GBM 梯度提升机
LightGBM 是一个梯度 boosting 框架,使用基于学习算法的决策树。它可以说是分布式的,高效的,有以下优势:
更快的训练效率
低内存使用
更高的准确率
支持并行化学习
可处理大规模数据
与常用的机器学习算法进行比较:速度飞起
LightGBM 垂直地生长树,即 leaf-wise,它会选择最大 delta loss 的叶子来增长。
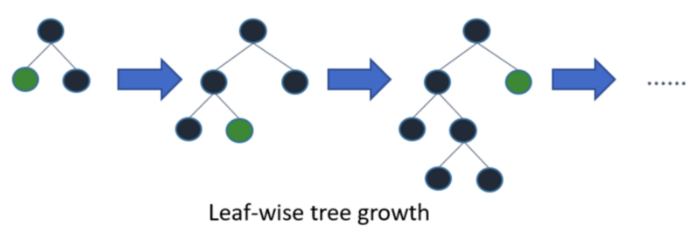
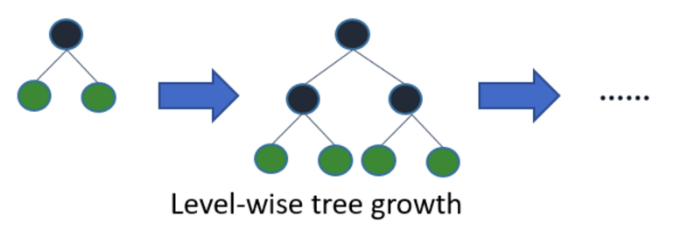
而以往其它基于树的算法是水平地生长,即 level-wise
当生长相同的叶子时,Leaf-wise 比 level-wise 减少更多的损失。
高速,高效处理大数据,运行时需要更低的内存,支持 GPU
不要在少量数据上使用,会过拟合,建议 10,000+ 行记录时使用。
2.特点
1)xgboost缺点
每轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
预排序方法(pre-sorted):首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。其次时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
2)LightGBM优点
Histogram算法
直方图算法的基本思想:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
Leaf-wise则是一种更为高效的策略:每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
Leaf-wise的缺点:可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合。
3.安装
需要安装64位的python才能进行安装
自己进行编译的方法参照:https://blog.csdn.net/testcs_dn/article/details/54176824
使用python可以直接pip安装:
pip install lightgbm
4.参数
- max_depth, default=-1, type=int,树的最大深度限制,防止过拟合
- min_data_in_leaf, default=20, type=int, 叶子节点最小样本数,防止过拟合
- feature_fraction, default=1.0, type=double, 0.0 < feature_fraction < 1.0,随机选择特征比例,加速训练及防止过拟合
- feature_fraction_seed, default=2, type=int,随机种子数,保证每次能够随机选择样本的一致性
- bagging_fraction, default=1.0, type=double, 类似随机森林,每次不重采样选取数据
- lambda_l1, default=0, type=double, L1正则
- lambda_l2, default=0, type=double, L2正则
- min_split_gain, default=0, type=double, 最小切分的信息增益值
- top_rate, default=0.2, type=double,大梯度树的保留比例
- other_rate, default=0.1, type=int,小梯度树的保留比例
- min_data_per_group, default=100, type=int,每个分类组的最小数据量
- max_cat_threshold, default=32, type=int,分类特征的最大阈值
- num_leaves:默认 31,因为LightGBM使用的是leaf-wise的算法,因此在调节树的复杂程度时,使用的是num_leaves而不是max_depth。
大致换算关系:num_leaves = 2^(max_depth)。它的值的设置应该小于2^(max_depth),否则可能会导致过拟合。 - 对于非平衡数据集:可以param['is_unbalance']='true’
- early_stopping_round:如果一次验证数据的一个度量在最近的
early_stopping_round回合中没有提高,模型将停止训练,加速分析,减少过多迭代 - application(objective):选择 regression: 回归时,binary: 二分类时,multiclass: 多分类时
- num_class:多分类的分类数
- learning_rate:如果一次验证数据的一个度量在最近的
early_stopping_round回合中没有提高,模型将停止训练,常用 0.1, 0.001, 0.003… - verbose_eval:type=int,输出日志详细情况,多少条数据输出一条记录
5.比较

6.调参
下表对应了 Faster Speed ,better accuracy ,over-fitting 三种目的时,可以调的参数
| Faster Speed | better accuracy | over-fitting |
|---|---|---|
将 max_bin 设置小一些 |
用较大的 max_bin |
max_bin 小一些 |
num_leaves 大一些 |
num_leaves 小一些 |
|
用 feature_fraction 来做 sub-sampling |
用 feature_fraction |
|
用 bagging_fraction 和 bagging_freq |
设定 bagging_fraction 和 bagging_freq |
|
| training data 多一些 | training data 多一些 | |
用 save_binary 来加速数据加载 |
直接用 categorical feature | 用 gmin_data_in_leaf 和 min_sum_hessian_in_leaf |
| 用 parallel learning | 用 dart | 用 lambda_l1, lambda_l2 ,min_gain_to_split 做正则化 |
num_iterations 大一些,learning_rate 小一些 |
用 max_depth 控制树的深度 |
7.例子
params={
"learning_rate":0.1,
"lambda_l1":0.1,
"lambda_l2":0.2,
'num_leaves':20,
"max_depth":4,
"objective":"multiclass",
"num_class":11,
}
param['is_unbalance']='true'
param['metric'] = 'auc'
clf=lgb.train(params,train_data,num_boost_round=100000,early_stopping_rounds=50,verbose_eval=20)
pred = clf.predict(X_test,num_iteration=clf.best_iteration)
8.自动寻优调参
现在最新的lightgbm python包已经更新到了0.2版本,支持sklearn的自动寻优调参
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV estimator = lgb.LGBMRegressor(objective='regression',colsample_bytree=0.8,subsample=0.9,subsample_freq=5) param_grid={
'learning_rate':[0.01,0.02,0.05,0.1],
'n_estimators' :[1000,2000,3000,4000,5000],
'num_leaves':[128,1024,4096]
} fit_param={'categorical_feature':[0,1,2,3,4,5]}
gbm = GridSearchCV(estimator,param_grid,fit_params=fit_param,n_jobs=5,refit=True)
gbm.fit(X_lgb,y_lgb) print('.....................................cv results.......................')
print(gbm.cv_results_)
9.特征重要性
# 放入训练的属性以及分类的特征值
import_rate = clf.feature_importance()
# 转化为百分比
importance = np.array(import_rate)/sum(import_rate)
LightGBM的更多相关文章
- LightGBM中GBDT的实现
现在LightGBM开源了,这里将之前的一个文档发布出来供大家参考,帮助更快理解LightGBM的实现,整体思路应该是类似的. LightGBM优雅,快速,效果好,希望LightGBM越来越好:) L ...
- XGBoost、LightGBM的详细对比介绍
sklearn集成方法 集成方法的目的是结合一些基于某些算法训练得到的基学习器来改进其泛化能力和鲁棒性(相对单个的基学习器而言)主流的两种做法分别是: bagging 基本思想 独立的训练一些基学习器 ...
- 安装 LightGBM 包的过程
conda install cmake conda install gcc git clone --recursive https://github.com/Microsoft/LightGBM ; ...
- 工业级GBDT算法︱微软开源 的LightGBM(R包正在开发....)
看完一篇介绍文章后,第一个直觉就是这算法已经配得上工业级属性.日前看到微软已经公开了这一算法,而且已经发开python版本,本人觉得等hadoop+Spark这些平台配齐之后,就可以大规模宣传啦~如果 ...
- LightGBM大战XGBoost,谁将夺得桂冠?
引 言 如果你是一个机器学习社区的活跃成员,你一定知道 提升机器(Boosting Machine)以及它们的能力.提升机器从AdaBoost发展到目前最流行的XGBoost.XGBoost实际上已经 ...
- Stacking:Catboost、Xgboost、LightGBM、Adaboost、RF etc
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- LightGBM总结
一.LightGBM介绍 LightGBM是一个梯度Boosting框架,使用基于决策树的学习算法.它可以说是分布式的,高效的,有以下优势: 1)更快的训练效率 2)低内存使用 3)更高的准确率 4) ...
- LightGBM算法(转载)
原文:https://blog.csdn.net/niaolianjiulin/article/details/76584785 前者的含义是轻量级,GBM:梯度上升机. 相较于xgboost: 更快 ...
- 自动调参库hyperopt+lightgbm 调参demo
在此之前,调参要么网格调参,要么随机调参,要么肉眼调参.虽然调参到一定程度,进步有限,但仍然很耗精力. 自动调参库hyperopt可用tpe算法自动调参,实测强于随机调参. hyperopt 需要自己 ...
- Lightgbm 随笔
lightGBM LightGBM 是一个梯度 boosting 框架,使用基于学习算法的决策树.它可以说是分布式的,高效的,有以下优势: 更快的训练效率 低内存使用 更高的准确率 支持并行化学习 可 ...
随机推荐
- 监听器(Listener)学习(二)在开发中的常见应用
监听器在JavaWeb开发中用得比较多,下面说一下监听器(Listener)在开发中的常见应用: 统计当前在线人数 自定义Session扫描器 一.统计当前在线人数 在JavaWeb应用开发中,有时候 ...
- Codeforces 914H Ember and Storm's Tree Game 【DP】*
Codeforces 914H Ember and Storm's Tree Game 题目链接 ORZ佬 果然出了一套自闭题 这题让你算出第一个人有必胜策略的方案数 然后我们就发现必胜的条件就是树上 ...
- 20179223《Linux内核原理与分析》第三周学习笔记
测试3的实验: 1. 用gcc -g编译vi输入的代码 2. 在main函数中设置一个行断点 3. 在main函数增加一个空循环,循环次数为自己学号后4位,设置一个约为学号一半的条件断点 4. 提交调 ...
- from 验证
/* 新版的页面控件值验证 @element 要验证的范围对象 @isValiMust 是否需要验证必填(临时保存的时候就不需要验证必填) @isByName 是否依赖name寻找控件 @return ...
- 在 FastAdmin 中启动 ThinkPHP 5 的请求缓存分析
在 FastAdmin 中启动 ThinkPHP 5 的请求缓存分析 缓存的基础配置 ThinkPHP 5 中有一个请求缓存:1 'request_cache' => true, 'reques ...
- Netty--Google Protobuf编解码
Google Protobuf是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化.它很适合做数据存储或 RPC 数据交换格式.可用于通讯协议.数据存储等领域的语言无关.平台无关.可扩展的序列 ...
- Appium ios新的定位方式FindsByIosNSPredicate (没有试 先记录在这里) 有个 driver.find_element_by_ios_uiautomation() 研究下 ios的定位
这个定位方式需要用java-client -5.0.版本,4.x的版本没有这个定位方式 //输入账号和密码 driver.findElementByIosNsPredicate("value ...
- log4j示例-Daily方式(log4j.properties)
log_home=./log log4j.rootLogger=info log4j.category.com.ai.toptea.collection=Console,DailyFile,Daily ...
- H3C V7版本的系统默认权限
H3C (v7平台)Console口通过账号密码登陆配置教程 http://www.023wg.com/h3c/496.html H3C (v7平台)Console口通过账号密码登陆配置教程 看不懂的 ...
- @BindingAnnotation
(1) 如果 一个接口只有一个实现,使用这种连接注解就可以: bind(XXInterface.class).to(XXImpl.class); @Inject XXInterface xxInter ...