Gradient-Based Learning Applied to Document Recognition 部分阅读
卷积网络
卷积网络用三种结构来确保移位、尺度和旋转不变:局部感知野、权值共享和时间或空间降采样。典型的leNet-5如下图所示:
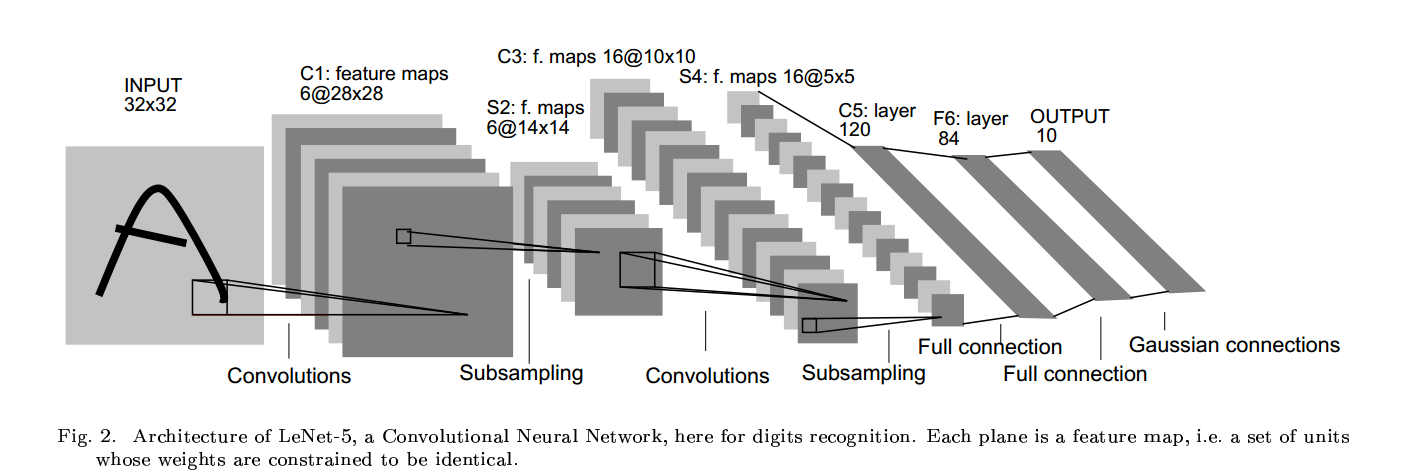
C1中每个特征图的每个单元和输入的25个点相连,这个5*5的区域被称为感知野。特征图的每个单元共享25个权值和一个偏置。其他特征图使用不同的权值(卷积枋),因
此可以得到不同类型的局部特征。卷积层的一个重要思想是,如果图像产生了位移,特征图输出将会产生相同数量的位移。这也是卷积网络位移和形变不变的原理。
特征图检测完毕后,它们的确切位置就不那么重要了,重要的是特征之间的相对位置。特征位置太准确不仅无利于模式识别,还会有害处,因为对不同的字符来说它们的位置是
不同的(所以特征之间的相对位置才是最重要的)。降低位置准确性可以通过下采样来降低分辨率来实现,同是也降低了输出对位移和形变的敏感性。每个单元计算四个输入的平均值(就是采样层),
将下采样的值乘一个训练系数加一个偏置(下采样层连接到sigmod的系数同要需要训练),然后将结果传给激活函数。训练系数和偏置控制了sigmod函数的非线性。如果这个系数很小的话,则每个单元类似于线性模型,下采样层所起的功能仅仅就是模糊输入;如果系数很大,则下采样操作可视为noisy OR或者 noisy AND(取决于偏置的大小)(存疑?)。
leNet-5
leNet-5有七层(不含输入),其中C1有156((5*5+1)*6)个可训练参数,122304(28*28*156)个连接。C2层的一个单元为C1中的2*2所得,输入到激活函数时它们共用一个
系数加一个偏置,所需的训练参数为(1+1)*6=12个,连接参数为(4+1)*6*14*14=5880个(我的理解是只在leNet-5中2*2的感知野值相同)。
C3层有16个特征图,由表格可以看出,每个特征图对S2中的特征图并非是全连接的。共有(25*3+1)*6+(25*4)*9+(25*6+1)=1516个训练参数,连接个数为
1516*10*10=151600个。S4同样为下采样层,有16*(1+1)=32个训练参数,有(2*2+1)*25*16=2000个连接。

C5有120个特征图,同样用5*5的卷积核,与S4层全连接,所以C5的特征是1*1的。之所以C5为卷积层而不是全连接层,是因为当le-Net5的输入增大时,特征图的维度也会大于
1*1。
F6全连接层,有84个单元,与C5全连接,共有(120+1)*84=10164个训练参数。同经经典的神经网络一样,F6乘权重加偏置然后送入到激活函数中。
下面是输出层(好吧,看的不是很明白),参考:http://blog.csdn.net/zouxy09/article/details/8781543
Gradient-Based Learning Applied to Document Recognition 部分阅读的更多相关文章
- 深度学习基础(一)LeNet_Gradient-Based Learning Applied to Document Recognition
作者:Yann LeCun,Leon Botton, Yoshua Bengio,and Patrick Haffner 这篇论文内容较多,这里只对部分内容进行记录: 以下是对论文原文的翻译: 在传统 ...
- 泡泡一分钟:Stabilize an Unsupervised Feature Learning for LiDAR-based Place Recognition
Stabilize an Unsupervised Feature Learning for LiDAR-based Place Recognition Peng Yin, Lingyun Xu, Z ...
- Learning Query and Document Similarities from Click-through Bipartite Graph with Metadata
读了一篇paper,MSRA的Wei Wu的一篇<Learning Query and Document Similarities from Click-through Bipartite Gr ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- Collaborative Spatioitemporal Feature Learning for Video Action Recognition
Collaborative Spatioitemporal Feature Learning for Video Action Recognition 摘要 时空特征提取在视频动作识别中是一个非常重要 ...
- Pros and Cons of Game Based Learning
https://www.gamedesigning.org/learn/game-based-learning/ I remember days gone by at elementary schoo ...
- 论文阅读 | Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition
源地址 arXiv:1712.07465: Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition ...
- 论文阅读:Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis
论文标题:Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis 论文链接:http://arxi ...
- BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition 目录 BBN: Bi ...
随机推荐
- 【bzoj4011】落忆枫音
Portal --> bzoj4011 Solution 这题..看了一眼之后深陷矩阵树定理然后我看了一眼数据范围== 注意到是有向无环图,DAG有十分多优秀的性质所以,这题需要充分利用这个 ...
- 【bzoj2759】一个动态树好题
Portal -->bzoj2759 Solution 哇我感觉这题真的qwq是很好的一题呀qwq 很神qwq反正我真的是自己想怎么想都想不到就是了qwq 首先先考虑一下简化版的问题应该怎么解决 ...
- Python之旅:数字、字符串
一 数字 整型与浮点型 #整型int 作用:年纪,等级,身份证号,qq号等整型数字相关 定义: age=10 #本质age=int(10) #浮点型float 作用:薪资,身高,体重,体质参数等浮点数 ...
- Codeforces Round #306 (Div. 2)A B C D 暴力 位/暴力 暴力 构造
A. Two Substrings time limit per test 2 seconds memory limit per test 256 megabytes input standard i ...
- wireshark 根据域名筛选
应该去掉引号
- C++ ------ 创建对象 new 和不 new 的区别
1.作用域不同 不用new:作用域限制在定义类对象的方法中,当方法结束时,类对象也被系统释放了,(安全不会造成内存系统泄漏). 用new:创建的是指向类对象的指针,作用域变成了全局,当程序结束时,必须 ...
- 「Django」rest_framework学习系列-渲染器
渲染器:作用于页面,JSONRenderer只是JSON格式,BrowsableAPIRenderer有页面,.AdminRenderer页面以admin形式呈现(需要在请求地址后缀添加?fromat ...
- Tests for normality正态分布检验
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程) https://study.163.com/course/ ...
- Bootsrap 直接使用
Bootstrap3 直接使用 <!DOCTYPE html> <html> <head> <title>Bootstrap3</title> ...
- Windows 安装 RabbitMQ
RabbitMQ概述 RabbitMQ是流行的开源消息队列系统,是AMQP(Advanced Message Queuing Protocol高级消息队列协议)的标准实现,用erlang语言开发.Ra ...