python稀疏矩阵得到每列最大k项的值,对list内为类对象的排序(scipy.sparse.csr.csr_matrix)
print(train_set.tdm)
print(type(train_set.tdm))
输出得到:
(0, 3200) 0.264940780338
(0, 1682) 0.356545827856
(0, 3875) 0.404535449364
(0, 2638) 0.375094236628
(0, 2643) 0.420086333071
(0, 558) 0.332314202381
(0, 2383) 0.215711023304
(0, 3233) 0.304884643652
(0, 3848) 0.26822694041
(1, 1682) 0.0679433740085
(1, 3586) 0.186001809282
(1, 1748) 0.224453998729
(1, 4369) 0.217962362491
(1, 4102) 0.321977101868
(1, 3717) 0.11571865147
(1, 1849) 0.23976007391
(1, 3019) 0.105831301914
(1, 2731) 0.133236987271
(1, 2284) 0.158959982269
(1, 1129) 0.224453998729
(1, 4004) 0.14716429302
(1, 1113) 0.224453998729
(1, 1239) 0.23282317344
(1, 4439) 0.17621324335
(1, 4075) 0.111234138548
: :
(3297, 4296) 0.189022497666
(3297, 1273) 0.173257613112
(3297, 611) 0.189022497666
(3297, 1639) 0.201945480138
(3297, 1401) 0.196076146399
(3297, 800) 0.193531186809
(3297, 4442) 0.213804760507
(3298, 2383) 0.115351969953
(3298, 3848) 0.143434978411
(3298, 3480) 0.166989458436
(3298, 767) 0.208015125433
(3298, 3836) 0.115469714921
(3298, 3877) 0.132381892057
(3298, 4387) 0.302243669544
(3298, 2967) 0.182430066726
(3298, 4184) 0.170734583655
(3298, 3878) 0.131142324027
(3298, 3381) 0.202336034891
(3298, 3959) 0.299487688552
(3298, 1392) 0.257499357524
(3298, 3039) 0.266066529253
(3298, 3599) 0.27026191686
(3298, 4289) 0.302243669544
(3298, 484) 0.36124988755
(3298, 2037) 0.36124988755
<class 'scipy.sparse.csr.csr_matrix'>
说明这个变量train_set.tdm是个scipy.sparse.csr.csr_matrix,类似稀疏矩阵,输出得到的是矩阵中非0的行列坐标及值,现在我们要挑出每一行中值最大的k项。
首先我们知道一个对于稀疏矩阵很方便函数:
#输出非零元素对应的行坐标和列坐标
nonzero=train_set.tdm.nonzero()
#nonzero是个tuple
print(type(nonzero))
print(nonzero[0])
print(nonzero[1])
print(nonzero[1][0])
输出为:
<class 'tuple'>
[ 0 0 0 ..., 3298 3298 3298]
[3200 1682 3875 ..., 4289 484 2037]
3200
其实train_set.tdm是我文本挖掘tf-idf后得到的权重矩阵,
我要挑出每条记录中权重最大的76个词,根据权重从大到小输出这些词的字典编号到excel
我用一个class来存储这些非零格子的两个信息:一个是这个词权重信息,一个是这个词的字典编号,
lis来存一条记录的所有权重非零词的信息,gather则是所有lis的集合,代码如下:

class obj:
def __init__(self):
self.key=0
self.weight=0.0 k=0 #k用来记录是不是一条记录结束了
lis=[]
gather=[]
p=-1 #p用来计数,每走一遍循环+1
for i in nonzero[0]:#i不一定每循环就+1的,它是nonzero【0】里的数,不懂可以看之前输出的nonzero【0】
p=p+1
print(i)
if k==i:
a=obj()
a.key=nonzero[1][p]#这个词的字典编号就是它属于第几列
a.weight=train_set.tdm[i,nonzero[1][p]]
lis.append(a)
else:
lis.sort(key=lambda obj: obj.weight, reverse=True)#对链表内为类对象的排序
#print(lis)
gather.append(lis)
while k < i:
k=k+1
lis=[]
a=obj()
a.key=nonzero[1][p]
a.weight=train_set.tdm[i,nonzero[1][p]]
lis.append(a)
gather.append(lis)
最后就是输出到excel中
myexcel = xlwt.Workbook()
sheet = myexcel.add_sheet('sheet')
#si,sj表示输出到第几行第几列
si=-1
sj=-1
for i in gather:
si=si+1
for j in i:
sj=sj+1
sheet.write(si,sj,str(j.key))
while sj<=76:
sj=sj+1
sheet.write(si,sj,'-1')#要是没有那么多词组就用-1代替
sj=-1
myexcel.save("attribute76.xls")
就如下所示:
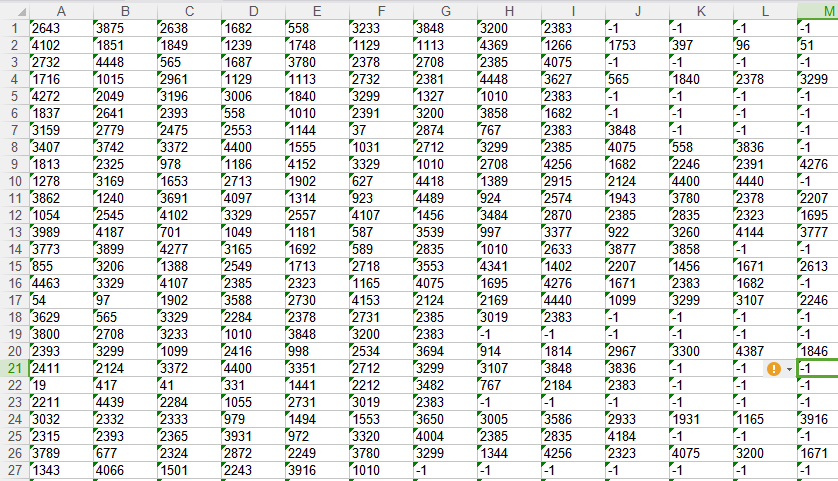
python稀疏矩阵得到每列最大k项的值,对list内为类对象的排序(scipy.sparse.csr.csr_matrix)的更多相关文章
- Python scipy.sparse矩阵使用方法
本文以csr_matrix为例来说明sparse矩阵的使用方法,其他类型的sparse矩阵可以参考https://docs.scipy.org/doc/scipy/reference/sparse.h ...
- python—类对象和实例对象的区别
最近在对RF的通讯层的模块进行封装,需要将之前放在类似main里面的一个方法,如下所示:这段代码是开发提供,用于接口测试,模拟底层通讯,具体的通讯是在dll内,python这边只是做了个封装让RF进行 ...
- Python - 面向对象编程 - 什么是 Python 类、类对象、实例对象
什么是对象和类 https://www.cnblogs.com/poloyy/p/15178423.html Python 类 类定义语法 最简单的类定义看起来像这样 class ClassName: ...
- PyQt(Python+Qt)学习随笔:QTreeWidgetItem项是否首列跨所有列展示属性isFirstColumnSpanned
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTreeWidget树型部件的QTreeWidgetItem项方法isFirstColumnSpa ...
- PyQt(Python+Qt)学习随笔:QTableWidgetItem项数据的data和setData访问方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTableWidget部件中的QTableWidgetItem项数据可以通过项的data( int ...
- 【跟着stackoverflow学Pandas】 - Adding new column to existing DataFrame in Python pandas - Pandas 添加列
最近做一个系列博客,跟着stackoverflow学Pandas. 以 pandas作为关键词,在stackoverflow中进行搜索,随后安照 votes 数目进行排序: https://stack ...
- 7-19 求链式线性表的倒数第K项(20 分)(单链表定义与尾插法)
给定一系列正整数,请设计一个尽可能高效的算法,查找倒数第K个位置上的数字. 输入格式: 输入首先给出一个正整数K,随后是若干正整数,最后以一个负整数表示结尾(该负数不算在序列内,不要处理). 输出格式 ...
- 7-19 求链式线性表的倒数第K项
7-19 求链式线性表的倒数第K项(20 分) 给定一系列正整数,请设计一个尽可能高效的算法,查找倒数第K个位置上的数字. 输入格式: 输入首先给出一个正整数K,随后是若干正整数,最后以一个负整数表示 ...
- python常见模块-collections-time-datetime-random-os-sys-序列化反序列化模块(json-pickle)-subprocess-03
collections模块-数据类型扩展模块 ''' 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque ...
随机推荐
- HDU 3923 Invoker(polya定理+乘法逆元(扩展欧几里德+费马小定理))
Invoker Time Limit : 2000/1000ms (Java/Other) Memory Limit : 122768/62768K (Java/Other) Total Subm ...
- arch初认识
在这里下载最新的iso镜像,一个iso里面已经包括了32和64位. 来者不善. 进去后竟然是进入字符界面,并且给各位留了一个install.txt,果然..==! 好吧,粗略看下install.txt ...
- 《Effective C++》第8章 定制new和delete-读书笔记
章节回顾: <Effective C++>第1章 让自己习惯C++-读书笔记 <Effective C++>第2章 构造/析构/赋值运算(1)-读书笔记 <Effecti ...
- C# 用Mutex或进程限制一台电脑上同时打开多个实例
private void Form1_Load(object sender, EventArgs e) { bool requestInitialOwnership ...
- New Concept English three(15)
31w/m 43 Children always appreciate small gifts of money. Father, of course, provides a regular supp ...
- Visual studio 生成后事件说明
在“配置属性->生成事件->生成后事件”属性页中的“命令行”编辑框中输入如下命令: copy "$(ProjectDir)$(IntDir)\$(ProjectName).t ...
- geotools中泰森多边形的生成
概述 本文讲述如何在geotools中生成泰森多边形,并shp输出. 泰森多边形 1.定义 泰森多边形又叫冯洛诺伊图(Voronoi diagram),得名于Georgy Voronoi,是由一组由连 ...
- CentOS6 mail邮件服务配置
mail服务配置 环境: [root@m01 ~]# cat /etc/redhat-release CentOS release 6.7 (Final) [root@m01 ~]# uname -m ...
- 【剑指offer】和为s的两个数字
原创博文,转载请注明出处! # 题目 # 思路 首先定义两个指针,第一个指针p指向数组的第一个数字,第二个指针q指向数组的最后一个数字.如果p+q=s,则找到要找的数字:如果p+q<s,则p向后 ...
- 拷贝ssh公钥到多台服务器上
这篇文章几乎是对Push SSH public keys to multiple host的翻译,谢谢该作者. 使用SSH登陆.执行命令到远程机器需要输入密码,很多系统需要免输密码访问远程机器,比如h ...