hbase-写操作
hbase连接过程
hbase client在写入的数据的过程中,是直接和rs进行通信的,整个的数据写入流程并不涉及到HMaster。那么client是如何找到对应的rs呢?流程如下:
- client从zookeeper中获取存储hbase:root表的RegionServer(设为rs1)的地址信息,hbase考虑到hbase:meta表过大,存储到了不同的region中,需要一个hbase:root的表对hbase:meta表的元数据进行存储。在0.98版本后,hbase:mata表不在split,只有一个region,也去除掉了hbase:root表,client的访问过程也不用进行这一步。
- client访问rs1,从hbase:root表中获取对应hbase:meta表的RegionServer(rs2)的地址信息。这里有些问题?hbase:root中如何知道一条数据应该写入哪个RegionServer?而这个对应的RegionServer应该存储在哪个hbase:meta中?在下面介绍hbase:meta表介绍。
- client访问rs2,从hbase:meta表中获取对应要访问的region的RegionServer(rs3)的地址信息。
- client访问rs3,和rs3进行数据交互。这里是具体的数据插入流程看下面两个具体的步骤(hbase客户端流程和hbase服务器端流程)。
meta表和root表格式:
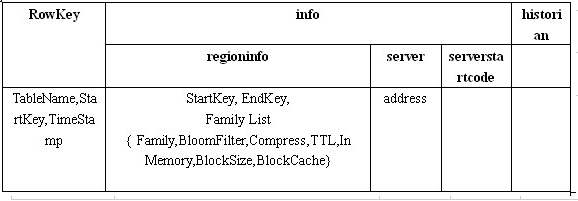
meta表结构例子:
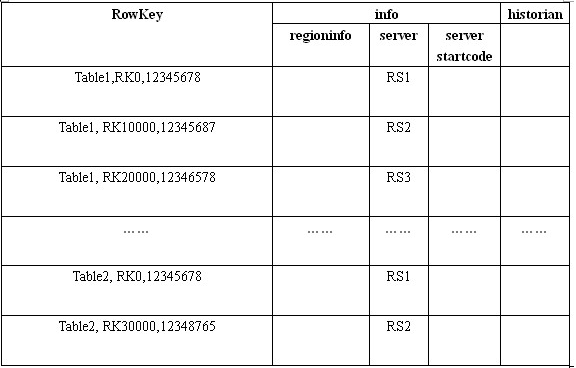
root表结构例子:

- 回答一下上面步骤二问题,从上面的root表中可以知道,RowKey里面包含了具体的表信息,这里就可以排除其他表,在regioninfo里面有具体的startKey和endKey信息,这里可以判断该条数据是否在这个区间。通过这两个信息就可以查找到对应meta表的rs地址。同理可以在meta表中查到到对应的数据交互的rs。
- 还有一个问题,是否每次put数据都需要进行这3次连接?其实不用的,每次client和hbase进行通信后,将访问过的meta表信息存储在本地。数据首先从本地的缓存中获取meta表数据,直接访问rs进行数据交互。
hbase客户端流程
- 用户提交put请求。hbase client提交可以设置autoflush参数,该参数默认autoflush=true,表示put请求会直接提交给服务器进行处理。可以设置为autoflush=false,这样的话put请求数据首先会存放在buffer中,等待本地的buffer数据大小达到阈值之后才会提交。很明显,两种方式的有优缺点在于,方式一数据写入慢,但是不会丢数据,方式二写入快,但是存在丢数据的风险。
- 在提交数据之前,client通过meta表查找到对应rowkey所属的rs,如果的批量提交,会将rowkey对应不同的rs分组,每个分组分别批量提交。
hbase服务器端流程
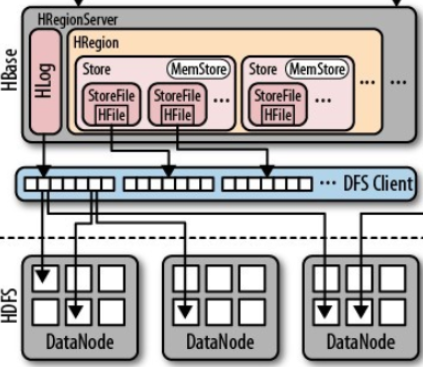
数据的写入流程:
- 数据首先写入到wal中
- 然后数据写入到MemStore中
- 当MemStore中的数据大小超过阈值,flush到HFile中
当机器出现宕机情况,因为wal和HFile中的数据存储在hdfs中,并不会出现数据丢失情况,数据丢失的是在MemStore中尚未flush到HFile的数据,可以从wal将这部分数据从新恢复
hbase-写操作的更多相关文章
- Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作
Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作 1.sparkstreaming实时写入Hbase(saveAsNewAPIHadoopDataset方法 ...
- NoSQL生态系统——事务机制,行锁,LSM,缓存多次写操作,RWN
13.2.4 事务机制 NoSQL系统通常注重性能和扩展性,而非事务机制. 传统的SQL数据库的事务通常都是支持ACID的强事务机制.要保证数据的一致性,通常多个事务是不可能交叉执行的,这样就导致了可 ...
- HBase Shell操作
Hbase 是一个分布式的.面向列的开源数据库,其实现是建立在google 的bigTable 理论之上,并基于hadoop HDFS文件系统. Hbase不同于一般的关系型数据库(RDBMS ...
- hbase日常操作及维护
一,基本命令: 建表:create 'testtable','coulmn1','coulmn2' 也可以建表时加coulmn的属性如:create 'testtable',{NAME => ' ...
- Hbase写数据,存数据,读数据的详细过程
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 出发Compact合并操作 -> 多 ...
- HBase写数据
1 多HTable并发写 创建多个HTable客户端用于写操作,提高写数据的吞吐量,一个例子: static final Configuration conf = HBaseConfiguration ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- HBase写请求分析
HBase作为分布式NoSQL数据库系统,不单支持宽列表.而且对于随机读写来说也具有较高的性能.在高性能的随机读写事务的同一时候.HBase也能保持事务的一致性. 眼下HBase仅仅支持行级别的事务一 ...
- HBase常用操作之namespace
1.介绍 在HBase中,namespace命名空间指对一组表的逻辑分组,类似RDBMS中的database,方便对表在业务上划分.Apache HBase从0.98.0, 0.95.2两个版本开始支 ...
- HBase写过程详解
1首次读写流程图 2 首次写基本流程 (1)客户端发起PUT请求,Zookeeper返回hbase:meta所在的region server (2)去(1)返回的server上,根据rowkey去hb ...
随机推荐
- Java能不能通过代码干预Java垃圾回收
1.不能通过Java代码干预Java垃圾回收. 2.system.gc是请求运行垃圾回收器,不一定真的运行了垃圾回收器. 3.Java的system.gc不受代码控制. 4.影响Java虚拟机垃圾回收 ...
- Python2--Pytest_html测试报告优化(解决中文输出问题)
1.报告的输出: pytest.main(["-s","Auto_test.py","--html=Result_test.html"]) ...
- 树——B-树
B树的定义: 1.若根结点不是终端结点,则至少有2棵子树 2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m 3.每一个叶子节点都包含k-1个元素,其中 m/2 ...
- mongodb集群部署
一.安装Mongodb(Tarballs) 1.检查依赖文件包: yum install libcurl openssl 2.解压文件到/usr/local/ tar -zxvf mongodb-li ...
- Jquery如何序列化form表单数据为JSON对象
jquery提供的serialize方法能够实现. $("#searchForm").serialize();但是,观察输出的信息,发现serialize()方法做的是将表单中的数 ...
- ORM版学员管理系统
ORM版学员管理系统 班级表 表结构 class Class(models.Model): id = models.AutoField(primary_key=True) # 主键 cname = m ...
- python大法好——mysql防注入
MySQL 及 SQL 注入 如果您通过网页获取用户输入的数据并将其插入一个MySQL数据库,那么就有可能发生SQL注入安全的问题. 本章节将为大家介绍如何防止SQL注入,并通过脚本来过滤SQL中注入 ...
- groovy 知识集锦
对应官方的<Program structure>的中文翻译 http://www.cnblogs.com/zhaoxia0815/p/7404387.html
- 基于WCF的支持跨局域网可断点续传的大文件传输服务实现
题外话:这个系列的文章记录了本人最近写的一个小工程,主要包含了两个功能,一是对文件的断点续传的功能,二是基于WCF的一对多文件主动发送的功能,顺便这也是我自己在WCF学习路上的一个小成果吧. 在网上找 ...
- (译)MySQL的10个基本性能技巧
原文出处:https://www.infoworld.com/article/3210905/sql/10-essential-performance-tips-for-mysql.html MySQ ...