python爬虫-上期所持仓排名数据爬取
摘要:笔记记录爬取上期所持仓数据的过程,本次爬取使用的工具是python,使用的IDE是pycharm
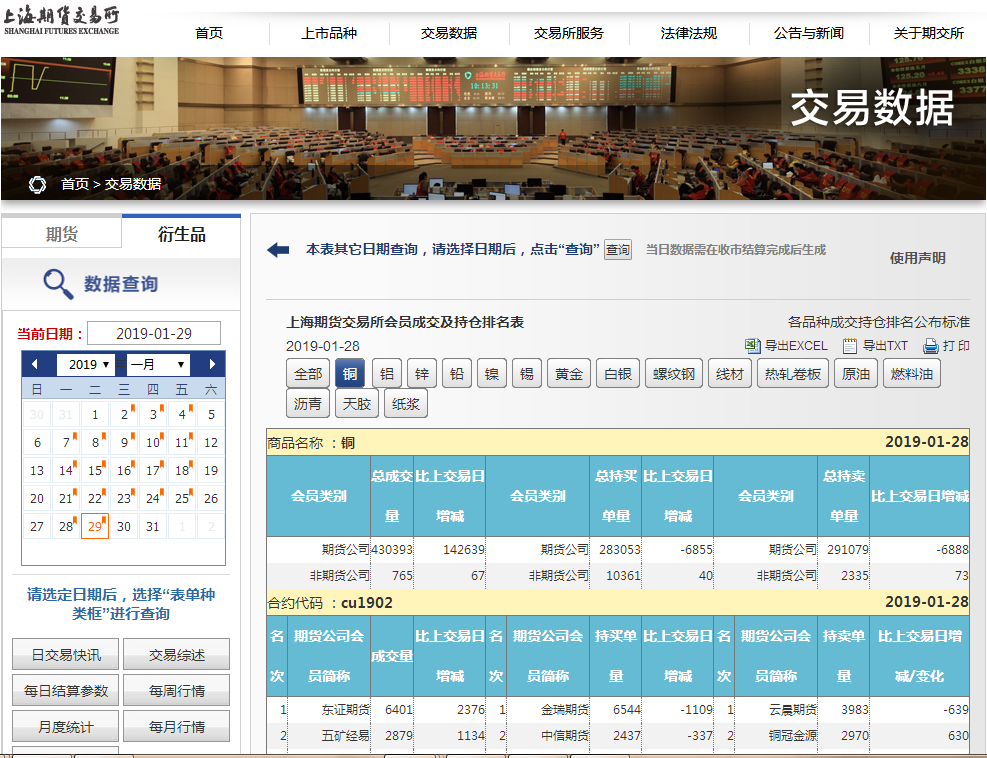
一、查看网页属性,分析数据结构
在浏览器中打开上期所网页,按F12或者选择表格文字-右键-审查元素,调出控制台:
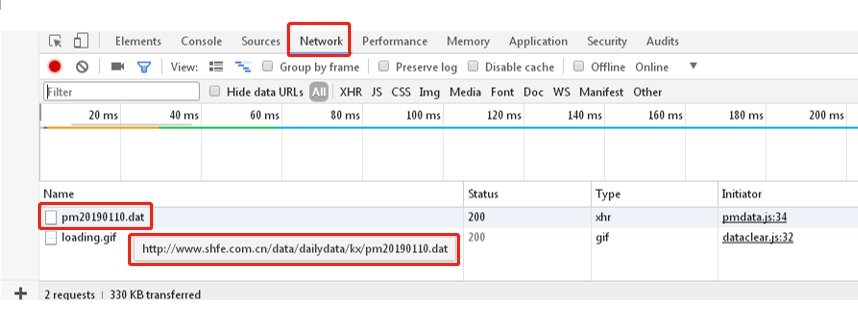
在Network中可以看到目标数据:http://www.shfe.com.cn/data/dailydata/kx/pm20190110.dat,其中20190110是数据代表的日期:
二、将数据下载到本地文件夹
1.在pycharm中新建一个python文档,将目标dat文件下载到本地文件夹,需要用到的包可以在CMD控制台中通过 ‘pip install [包名]’ 安装:
import xlwt
import requests
import os
mydate = "" #指定需要的数据日期
url = "http://www.shfe.com.cn/data/dailydata/kx/pm" + mydate + ".dat"
root = "F://py//SQ//"
path = root + url.split('/')[-1] + ".txt" #指定下载的目录,保存为txt文件
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
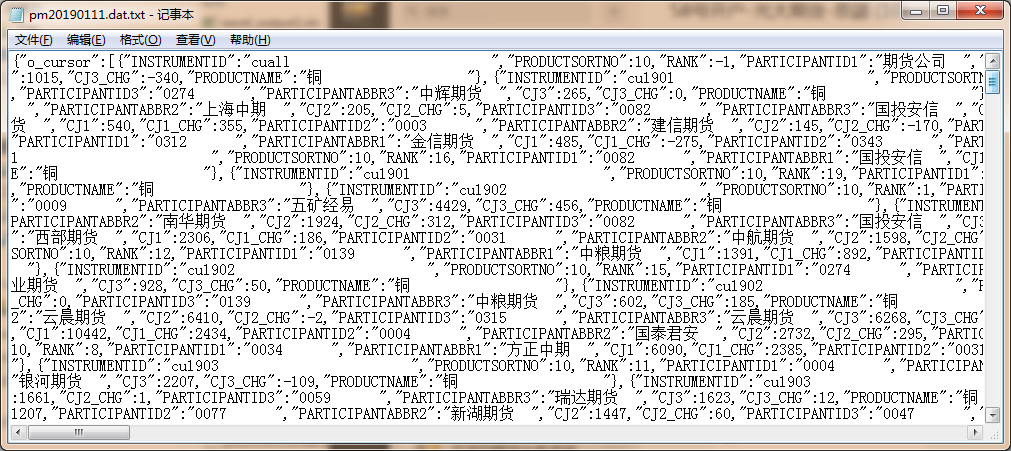
2.运行代码后,可以看到文件夹中多了个pm20190111.dat.txt文件,用记事本打开文件,可以看到文件是Json格式的表格,接下来用json包将其解析成python的dataframe格式:
代码:
import json
file = open("F://py//SQ//pm" + mydate + ".dat.txt", 'r', encoding='UTF-8')
js = file.read()
dic = json.loads(js)
file.close()
3.接下来将数据存储到excel表中,使用的是xlwt包,运行代码,至此,上期所的每日持仓数据已成功爬取:
def WriteExcel(data):
pm = xlwt.Workbook()
sheet = pm.add_sheet('Sheet1', cell_overwrite_ok=True)
title = ['品种代码', '序号', '排名', '期货公司会员号', '会员类别', '总成交量', '比上交易日增减', '期货公司会员号', '会员类别', '总持买单量', '比上交易日增减', '期货公司会员号',
'会员类别', '总持卖单量', '比上交易日增减', '品种']
for i in range(len(title)): # 创建表头
sheet.write(0, i, title[i])
j = 0
for line in data["o_cursor"]: # 写入数据
dataV = list(data["o_cursor"][j].values())
j = j + 1
for k in range(len(dataV)):
if isinstance(dataV[k], str):
dataV[k] = dataV[k].strip()
sheet.write(j, k, dataV[k])
pm.save("F://py//SQ//demo" + mydate + ".xls")
WriteExcel(dic)
python爬虫-上期所持仓排名数据爬取的更多相关文章
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- Python爬虫开源项目代码,爬取微信、淘宝、豆瓣、知乎、新浪微博、QQ、去哪网等 代码整理
作者:SFLYQ 今天为大家整理了32个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [ ...
- 23个Python爬虫开源项目代码:爬取微信、淘宝、豆瓣、知乎、微博等
来源:全球人工智能 作者:SFLYQ 今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.Wec ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- 小白学 Python 爬虫(25):爬取股票信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 【python爬虫】一个简单的爬取百家号文章的小爬虫
需求 用"老龄智能"在百度百家号中搜索文章,爬取文章内容和相关信息. 观察网页 红色框框的地方可以选择资讯来源,我这里选择的是百家号,因为百家号聚合了来自多个平台的新闻报道.首先看 ...
- Python爬虫之-动态网页数据抓取
什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新.这意 ...
随机推荐
- vue+sass实现切换字体大小
接到领导指示,用户嫌我做的页面字体太小,15px的字体叫小?领导说用户多是上了年纪的人.没办法,改吧,谁让咱是个搬砖的呢..咳咳 我寻思着这次改大了,下次用户嫌大再让改小呢?干脆给他做个选择字号的功能 ...
- 8. springboot logback 日志整合
在resources目录下,新建log/logback-spring.xml文件,内容如下: <?xml version="1.0" encoding="UTF-8 ...
- python2操作MySQL
#coding=utf-8 import MySQLdb conn = MySQLdb.connect(host='localhost',user='root',passwd='123456' ...
- 模块(modue)和包(package)的概念-import导入模块
模块 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较 ...
- mount.cifs permission denied
[root@dev ~]# mount.cifs //192.168.9.155/APP /mnt/APP/ -o user=administrator,pass=dsff#$TTT 在检查帐号密码权 ...
- [Tools] Wireshark Primer Tutorials
介绍就不说了,安装也没必要讲,关于如何使用,网上的辣鸡文过多,视频又太冗余. 我推荐看下面有条理的入门教程. 界面说明:http://openmaniak.com/cn/wireshark_use.p ...
- []、()、None的区别
def product(*numbers): if numbers == (): raise TypeError for x in numbers: if not isinstance (x, (in ...
- Redis部署说明
一.普通部署 将Redis-x64-3.2.100解压,修改配置文件,一般不需要修改,直接使用默认,具体要修改可自行百度. 打开命令行,定位到解压目录,执行命令: redis-server.exe r ...
- Selenium+TestNG+Maven(2)
转载自http://www.cnblogs.com/hustar0102/p/5885115.html selenium介绍和环境搭建 一.简单介绍 1.selenium:Selenium是一个用于W ...
- 【算法】BM算法
目录 BM算法 一. 字符串比较的分析 二.BM算法的思想 三.算法实现 BM算法 @ 一. 字符串比较的分析 如果要判定长度为\(n\)两个字符串相等,比较中要进行\(n\)比较,但是如果要判定两个 ...