cuda编程-并行规约
利用shared memory计算,并避免bank conflict;通过每个block内部规约,然后再把所有block的计算结果在CPU端累加
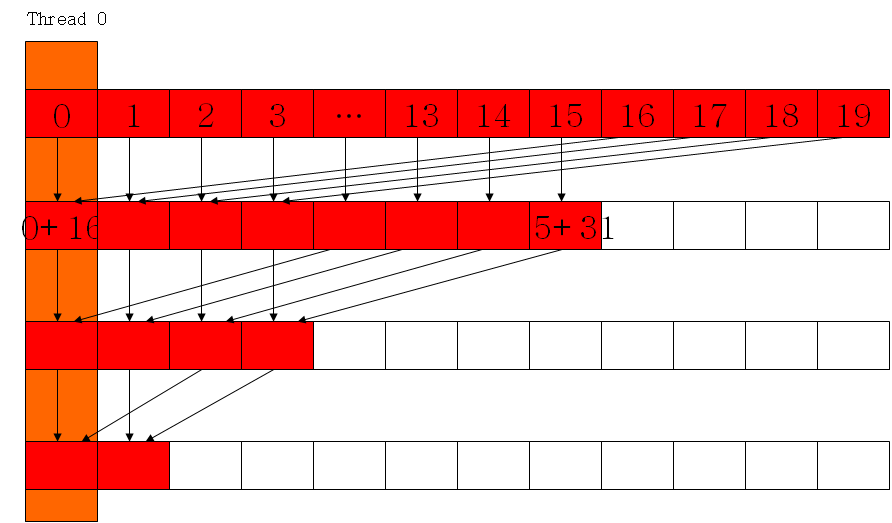
代码:
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <stdio.h>
#include <stdlib.h>
#include <memory>
#include <iostream> #define DATA_SIZE 128
#define TILE_SIZE 64 __global__ void reductionKernel(float *in, float *out){
int tx = threadIdx.x;
int bx = blockIdx.x; __shared__ float data_shm[TILE_SIZE];
data_shm[tx] = in[bx * blockDim.x + tx];
__syncthreads(); for (int i = blockDim.x / ; i > ; i >>= ){
if (tx < i){
data_shm[tx] += data_shm[tx + i];
}
__syncthreads();
} if (tx == )
out[bx] = data_shm[];
} void reduction(){
int out_size = (DATA_SIZE + TILE_SIZE - ) / TILE_SIZE;
float *in = (float*)malloc(DATA_SIZE * sizeof(float));
float *out = (float*)malloc(out_size*sizeof(float));
for (int i = ; i < DATA_SIZE; ++i){
in[i] = i;
}
memset(out, , out_size*sizeof(float)); float *d_in, *d_out;
cudaMalloc((void**)&d_in, DATA_SIZE * sizeof(float));
cudaMalloc((void**)&d_out, out_size*sizeof(float));
cudaMemcpy(d_in, in, DATA_SIZE * sizeof(float), cudaMemcpyHostToDevice); dim3 block(TILE_SIZE, );
dim3 grid(out_size, );
reductionKernel << <grid, block >> >(d_in, d_out); cudaMemcpy(in, d_in, DATA_SIZE * sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(out, d_out, out_size * sizeof(float), cudaMemcpyDeviceToHost); float sum = ;
for (int i = ; i < out_size; ++i){
sum += out[i];
}
std::cout << sum << std::endl; // Check on CPU
float sum_cpu = ;
for (int i = ; i < DATA_SIZE; ++i){
sum_cpu += in[i];
}
std::cout << sum_cpu << std::endl; }
cuda编程-并行规约的更多相关文章
- CUDA中并行规约(Parallel Reduction)的优化
转自: http://hackecho.com/2013/04/cuda-parallel-reduction/ Parallel Reduction是NVIDIA-CUDA自带的例子,也几乎是所有C ...
- 【Cuda编程】加法归约
目录 cuda编程并行归约 AtomicAdd调用出错 gpu cpu下时间计算 加法的归约 矩阵乘法 矩阵转置 统计数目 平方和求和 分块处理 线程相邻 多block计算 cuda编程并行归约 At ...
- CUDA编程(六)进一步并行
CUDA编程(六) 进一步并行 在之前我们使用Thread完毕了简单的并行加速,尽管我们的程序运行速度有了50甚至上百倍的提升,可是依据内存带宽来评估的话我们的程序还远远不够.在上一篇博客中给大家介绍 ...
- cuda编程基础
转自: http://blog.csdn.net/augusdi/article/details/12529247 CUDA编程模型 CUDA编程模型将CPU作为主机,GPU作为协处理器(co-pro ...
- CUDA学习笔记(一)——CUDA编程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm56.html CUDA的代码分成两部分,一部分在host(CPU)上运行,是普通的C代码:另一部分在d ...
- CUDA编程
目录: 1.什么是CUDA 2.为什么要用到CUDA 3.CUDA环境搭建 4.第一个CUDA程序 5. CUDA编程 5.1. 基本概念 5.2. 线程层次结构 5.3. 存储器层次结构 5.4. ...
- CUDA编程-(1)Tesla服务器Kepler架构和万年的HelloWorld
结合CUDA范例精解以及CUDA并行编程.由于正在学习CUDA,CUDA用的比较多,因此翻译一些个人认为重点的章节和句子,作为学习,程序将通过NVIDIA K40服务器得出结果.如果想通过本书进行CU ...
- CUDA编程模型
1. 典型的CUDA编程包括五个步骤: 分配GPU内存 从CPU内存中拷贝数据到GPU内存中 调用CUDA内核函数来完成指定的任务 将数据从GPU内存中拷贝回CPU内存中 释放GPU内存 *2. 数据 ...
- CUDA编程之快速入门
CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架构.做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要 ...
随机推荐
- linux进程控制开发实例
fork.c #include <sys/types.h> #include <unistd.h> #include <stdio.h> #include < ...
- Javascript设计模式之我见:观察者模式
大家好!本文介绍观察者模式及其在Javascript中的应用. 模式介绍 定义 定义对象间一种一对多的依赖关系,使得每当一个对象改变状态,则所有依赖于它的对象都会得到通知并被自动更新. 类图及说明 S ...
- mybatis百科-列映射类ResultMapping
目录 1 成员变量 2 构造函数 3 其他函数 3.1 setter 和 getter 函数 3.2 equals 和 hashCode 函数 3.3 toString 函数 4 内部类 Builde ...
- 【C#复习总结】细说泛型委托
1 前言 本系列会将[委托] [匿名方法][Lambda表达式] [泛型委托] [表达式树] [事件]等基础知识总结一下.(本人小白一枚,有错误的地方希望大佬指正) 系类1:细说委托 系类2:细说匿名 ...
- 来自后端的突袭? --开包即食的教程带你浅尝最新开源的C# Web引擎 Blazor
在今年年初, 恰逢新春佳节临近的时候. 微软给全球的C#开发者们, 着实的送上了一分惊喜. 微软正式开源Blazor ,将.NET带回到浏览器. 这个小惊喜, 迅速的在dotnet开发者中间传开了. ...
- c++ 入门之深入探讨拷贝函数和内存分配
在c++入门之深入探讨类的一些行为时,说明了拷贝函数即复制构造函数运用于如下场景: 对象作为函数的参数,以值传递的方式传给函数. 对象作为函数的返回值,以值的方式从函数返回 使用一个对象给另一个对象初 ...
- 使用mysql,sql语言删除冗余信息
这是表,我们需要操作的就是删除除了学号不同,其它信息都相同的冗余信息 思路:删除表格class3中的冗余的stu_id信息,那么接下来我们应该去筛选哪些stu_id信息是冗余的, 此时我们想到的就是利 ...
- iOS NSDictionary JSON 相互转换
/*! * @brief 把格式化的JSON格式的字符串转换成字典 * @param jsonString JSON格式的字符串 * @return 返回字典 */ + (NSDictionary * ...
- 《梦断代码》Scott Rosenberg著(三)
开放与封闭之论: 程序源代码是商业软件公司最重要的资产,所以软件公司售卖二进制文件.这样也就意味着如果微软的软件产品出了问题,即便你是一个程序大牛也无法修复它.你只能等着微软来修正问题,因为只有微软程 ...
- windows 环境下 eclipse + maven + tomcat 的 hello world 创建和部署
主要记录自己一个新手用 eclipse + maven + tomcat 搭建 hello world 的过程,以及遇到的问题.讲真都是自己通过百度和谷歌一步步搭建的项目,没问过高手,也没高手可问,由 ...